







文章信息
- 模型: PatchTST (Channel-independent Patch time series Transformer )
- 关键词:Transformer,通道独立,patch,多变量时间序列,自监督学习
- 作者:Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam
- 机构:Princeton University(普林斯顿大学), IBM Research
- 发表情况:发表于 ICLR 2023 ( Published: 02 Feb 2023, Last Modified: 25 Nov
2024 ) - 会议网址:A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
前言
- Patching
先前的多个Transformer模型专注于设计更稀疏的注意力机制。然而逐点的设计思路还是难以在信息利用率和计算复杂度上达到平衡。而通过patch可以提高对局部信息的提取,实现子序列级(patch之间)依赖关系的提取,同时降低计算复杂度。
- 相比于点,片段具备更丰富语义信息;
- 即便之前出现了Autoformer这种基于片段的,但其并不提取片段内语义,且片段附近的其他时间点受到了忽视。
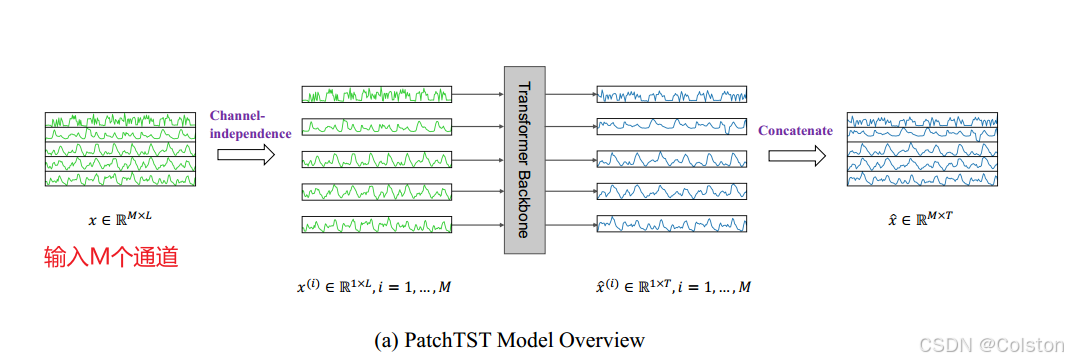
- Channel-independence
每个通道包含单个单变量时间序列,该序列在所有序列中共享相同的嵌入和Transformer权重。在patchTST中是将每个通道单独送入Transformer模块来实现的。
例如之前的DLinear模型采用全连接结构,每个神经元对输入数据的权重是独立学习的,不考虑输入数据的通道关系。
 而通道混合(Channel-mixing)强调不同通道之间的相关性和交互性建模,提高模型的表达能力和泛化能力。
而通道混合(Channel-mixing)强调不同通道之间的相关性和交互性建模,提高模型的表达能力和泛化能力。
一、网络结构
 整体的结构是在Transformer的结构上构建的,在输入时进行了归一化和patching操作,在输出时进行反归一化操作,并利用线性展平层将不同patch合并得到对应输出。
整体的结构是在Transformer的结构上构建的,在输入时进行了归一化和patching操作,在输出时进行反归一化操作,并利用线性展平层将不同patch合并得到对应输出。
Patching
patching是沿着时间步进行划分的,通过滑动窗口来实现。这样一来可以将不同时间步之间注意力转变为同一特征不同patch之间的注意力。

代码实现
class PatchEmbedding(nn.Module):
def __init__(self, d_model, patch_len, stride, padding, dropout):
super(PatchEmbedding, self).__init__()
# Patching
self.patch_len = patch_len
self.stride = stride
self.padding_patch_layer = nn.ReplicationPad1d((0, padding))
# Backbone, Input encoding: projection of feature vectors onto a d-dim vector space
self.value_embedding = nn.Linear(patch_len, d_model, bias=False)
# Positional embedding
self.position_embedding = PositionalEmbedding(d_model)
# Residual dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# do patching
n_vars = x.shape[1] # 特征数(通道数)
x = self.padding_patch_layer(x) # 划分前进行padding,
x = x.unfold(dimension=-1, size=self.patch_len, step=self.stride) # 划分padding
x = torch.reshape(x, (x.shape[0] * x.shape[1], x.shape[2], x.shape[3]))
# Input encoding
x = self.value_embedding(x) + self.position_embedding(x)
return self.dropout(x), n_vars
代码解读:
以ETT数据集多对单的预测为例:
- 输入
x:(Tensor:(32,7,96))依次对应batch_size,feature,seq_len. - padding的长度为滑动步长
stride,padding后的长度为96+8=104. - 对最后一个维度进行滑动取值,最后得到12个长度为
patch_len=16的序列
计算公式为 (seq_len − patch_len + padding)/stride + 1 = (96 - 16 + 8)/8 + 1 = 12.
此时x:Tensor:(32,7,12,16) reshape:将前两维合并,得到尺寸为(224,12,16)的张量,对比原本的输入可以发现:原本计算96个点之间的注意力转变为了计算12个patch之间的注意力。(直到最后预测输出时再将前两维展平还原)
总结
- 优点:
- 片段具备更丰富的语义信息
- 使用channel-independent,不同通道会有不同注意力分数分布,从而使模型能够识别不同序列(不同通道)的个性行为
- 缺点
- 由于使用channel-independent,有意不去捕获多变量时间序列不同序列(不同通道间)的依赖关系,缺乏关注不同序列的共性。

















 2092
2092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









