





硬件是两张32G RTX5000显卡,内存250G。我先是尝试了DeepSeek-VL2、DeepSeek-VL2-small,启动是都可以启动,但是调用接口的时候会提示共享内存不足,然后服务挂掉,换成tiny版本才可以正常回答。
启动框架用的是lmdeploy,目前DeepSeek-VL2官网上推荐的另外两个还没说可以支持VL2,等后续吧
附:目前对于DeepSeek-VL2服务的部署资料其实还是比较少的,大部分都是使用gradio或者本地调用的方式,部署的时候也没想那么多,部署完成后才想起来把自己踩得坑做下分享,所以许多命令没有执行截图,问题也列的不全,大家遇到问题可以评论继续完善,共同进步
一、 环境版本
| 系统 | Ubuntu24.04 x86_64 |
| conda | 24.11.3 |
| Cuda | 12.8.61 |
| python | 3.10 |
| torch | 2.0.1+cu118(版本必须是2.0.1) |
| torchvision | 0.15.2a0 |
| transformers | 4.44.2 |
| lmdeploy | 0.7.0.post3(推荐拉取最新代码进行安装) |
| 显卡Driver Version | 570.86.15 |
二、 部署步骤
由于这套环境比较混乱,所以有的软件安装的过程不具有参考性,这里就不具体写了,可以自行百度对应安装部署文档
1. 安装conda
2. 安装python3.10
3. 安装cuda
cuda是向下兼容的,所以安装的版本可以高一点,我这里是刚开始安装不清楚具体版本,安装了最新的,其实可以安装低版本的下载地址
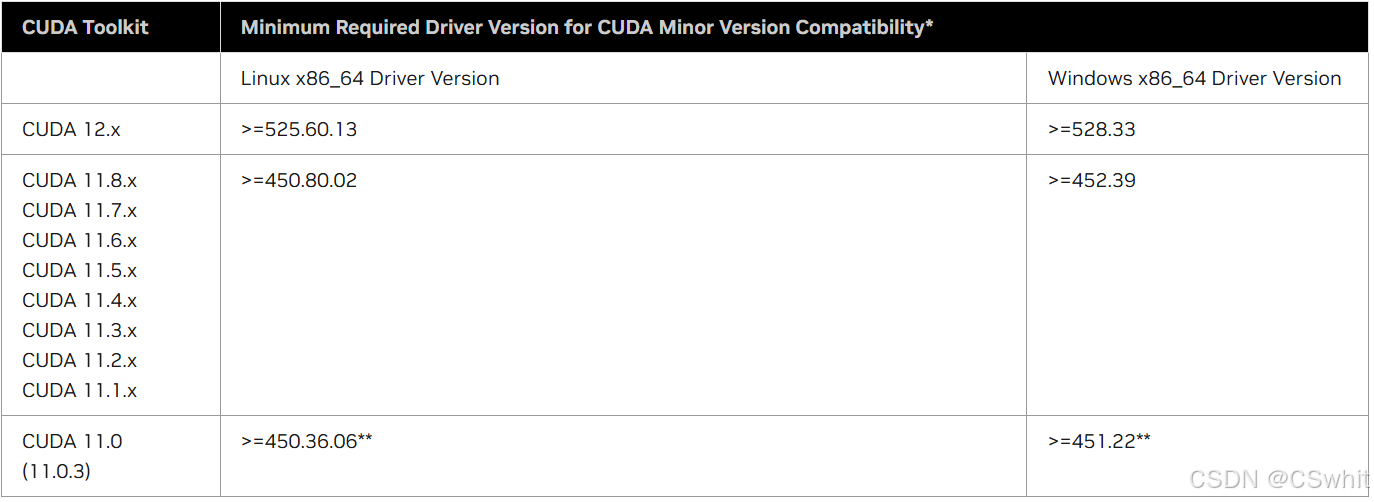
4. 安装对应cuda版本的驱动
贴个CUDA官网对应版本的图,具体的可以到官网看1. CUDA 12.8 Release Notes — Release Notes 12.8 documentation
5. 安装torch
torch我是用whl的方式安装的,下载后指定文件安装,这里的cu118就是cuda的版本,cp310是python版本下载地址
# 安装torch
pip3 install torch-2.0.1+cu118-cp310-cp310-linux_x86_64.whl
# 下面的命令可能会提示连接失败,可以换源或者多试几次
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia6. 安装lmdeploy 官方文档
git clone https://github.com/InternLM/lmdeploy.git
cd lmdeploy
pip3 install -e .7. 安装Deepseek-VL2、transformers lmdeploy文档中安装ds内容
pip install git+https://github.com/deepseek-ai/DeepSeek-VL2.git --no-deps
pip install attrdict timm 'transformers<4.48.0'8. 下载Deepseek-VL2模型
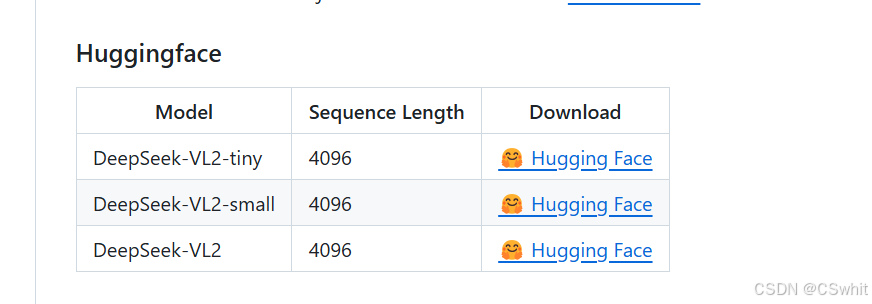
模型可以从官网的huggingface下载
9. 启动
# 启动命令
lmdeploy serve api_server {模型存储路径} --tp {显卡数量}如果遇到下面报错,可以添加两个参数解决
Error: mkl-service + Intel(R) MKL: MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library.
Try to import numpy first or set the threading layer accordingly. Set MKL_SERVICE_FORCE_INTEL to force it
export MKL_THREADING_LAYER=GNU
export MKL_SERVICE_FORCE_INTEL=1打印下面日志则说明启动成功了


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









