多模态模型落地实践:DeepSeek-VL2-Tiny本地服务部署全攻略
 项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/deepseek-vl2-tiny
项目地址: https://ai.gitcode.com/hf_mirrors/deepseek-ai/deepseek-vl2-tiny 随着多模态人工智能技术的快速发展,DeepSeek-VL2作为新一代视觉语言模型,凭借其高效的混合专家架构和强大的跨模态理解能力,受到了广泛关注。然而,对于许多开发者而言,将这样的先进模型成功部署到本地环境仍面临诸多挑战。本文将详细记录一次DeepSeek-VL2-Tiny模型的本地部署历程,分享硬件选型、环境配置、部署流程以及常见问题的解决方案,为广大AI爱好者和开发者提供一份实用的参考指南。
在开始部署之前,硬件配置的选择至关重要。经过实际测试,我们发现硬件资源的充足与否直接影响模型的运行稳定性。最初,我们尝试使用DeepSeek-VL2和DeepSeek-VL2-small版本,在两张32G RTX5000显卡和250G内存的配置下,虽然能够启动服务,但在调用接口时频繁出现共享内存不足的错误,导致服务崩溃。最终,换成参数规模更小的Tiny版本后,服务才能够正常响应请求。这一经历告诉我们,在本地部署大模型时,需要根据实际硬件条件合理选择模型版本,并非参数规模越大效果越好。
部署框架的选择同样关键。目前,DeepSeek-VL2官方推荐的部署框架中,lmdeploy对VL2的支持最为成熟。虽然官网提到的其他框架未来可能也会支持VL2,但就当前而言,lmdeploy是实现本地服务化部署的首选。需要注意的是,目前关于DeepSeek-VL2服务化部署的公开资料相对匮乏,大多数教程仍停留在使用gradio进行本地调用的阶段。因此,本文的经验分享具有一定的实践参考价值,希望能为后续开发者提供借鉴。
环境配置详解
成功部署DeepSeek-VL2-Tiny的首要步骤是搭建合适的软件环境。经过多次尝试和优化,我们总结出以下关键组件的版本要求,这些版本组合经过实际验证,能够确保模型的稳定运行。
操作系统方面,我们选择了Ubuntu 24.04 x86_64版本,该版本提供了良好的稳定性和对最新软件包的支持。在虚拟环境管理工具上,conda 24.11.3版本表现出色,能够有效隔离不同项目的依赖关系。CUDA作为GPU加速的核心组件,版本选择尤为重要,我们最终确定使用12.8.61版本。Python作为主要开发语言,3.10版本提供了较好的兼容性和性能。PyTorch作为深度学习框架,必须严格使用2.0.1+cu118版本,这是确保模型正常运行的关键因素之一。相应地,torchvision选择0.15.2a0版本,transformers则使用4.44.2版本。lmdeploy作为部署框架,推荐使用0.7.0.post3版本或直接拉取最新代码进行安装,以获得最佳支持。最后,显卡驱动版本需匹配CUDA要求,我们使用的是570.86.15版本。
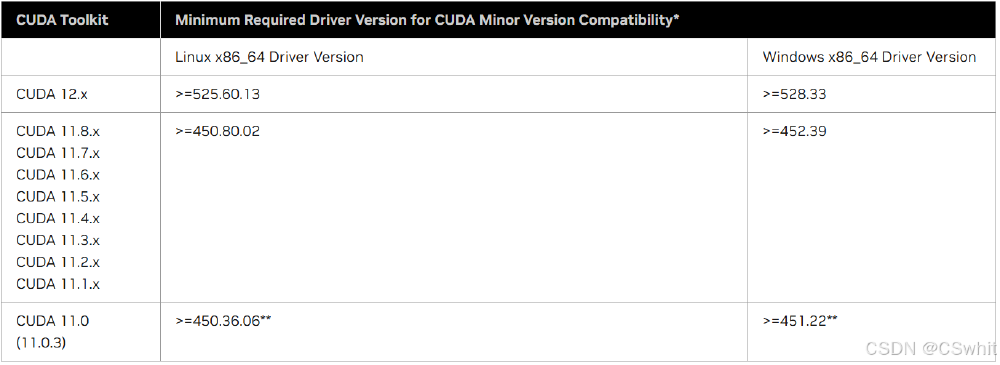
如上图所示,该表格详细列出了不同CUDA版本在Linux和Windows系统下所需的最低NVIDIA驱动版本。这一兼容性信息对于DeepSeek-VL2的本地部署至关重要,它为开发者提供了清晰的硬件配置指导,确保选择的CUDA版本与显卡驱动版本相匹配,从而避免因兼容性问题导致的部署失败。
部署步骤与实践
环境配置完成后,接下来进入实际的部署流程。需要说明的是,由于不同系统环境存在差异,以下步骤仅供参考,具体细节可能需要根据实际情况进行调整。
首先,安装conda。作为Python环境管理工具,conda能够帮助我们创建独立的虚拟环境,避免不同项目之间的依赖冲突。安装过程可以参考conda官方文档,选择适合Ubuntu系统的安装包进行安装。
其次,安装Python 3.10。在conda环境中,可以通过创建指定Python版本的虚拟环境来实现。例如,使用命令conda create -n deepseek-vl2 python=3.10即可创建一个名为deepseek-vl2的虚拟环境,并自动安装Python 3.10。
第三步是安装CUDA。需要注意的是,CUDA具有向下兼容性,因此可以安装比实际需求更高的版本。我们最初安装了最新的12.8.61版本,虽然稍显冗余,但确保了对后续可能升级的支持。开发者也可以根据实际需求选择较低版本,但需确保与其他组件兼容。CUDA的官方下载地址提供了详细的安装指南,建议仔细阅读并按照步骤操作。
安装完CUDA后,需要安装对应的显卡驱动。驱动版本的选择应参考CUDA官方提供的兼容性表格,确保与所安装的CUDA版本匹配。NVIDIA官方网站提供了各版本驱动的下载链接,选择适合自己显卡型号和操作系统的驱动进行安装。
接下来是安装PyTorch。这里需要特别注意,必须安装2.0.1+cu118版本。我们推荐使用whl文件的方式进行安装,先从官方网站下载对应版本的whl文件,然后通过pip3 install torch-2.0.1+cu118-cp310-cp310-linux_x86_64.whl命令进行本地安装。这种方式可以确保安装的是指定版本,避免因网络问题导致的版本错误。此外,还可以尝试使用conda命令安装:conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia。如果遇到连接失败的问题,可以尝试更换镜像源或多次尝试。
然后是安装lmdeploy。作为部署DeepSeek-VL2的关键框架,我们建议从源码安装以获取最新功能。具体步骤为:首先克隆lmdeploy的代码仓库:git clone https://gitcode.com/hf_mirrors/deepseek-ai/deepseek-vl2-tiny,然后进入lmdeploy目录,执行pip3 install -e .进行 editable模式安装。这种方式便于后续更新代码。
安装完成lmdeploy后,需要安装DeepSeek-VL2模型和transformers库。通过pip install git+https://github.com/deepseek-ai/DeepSeek-VL2.git --no-deps命令可以安装DeepSeek-VL2的相关依赖。同时,还需要安装attrdict、timm和transformers<4.48.0等辅助库。
模型下载是部署过程中的重要环节。DeepSeek-VL2的各个版本可以从Hugging Face平台下载。
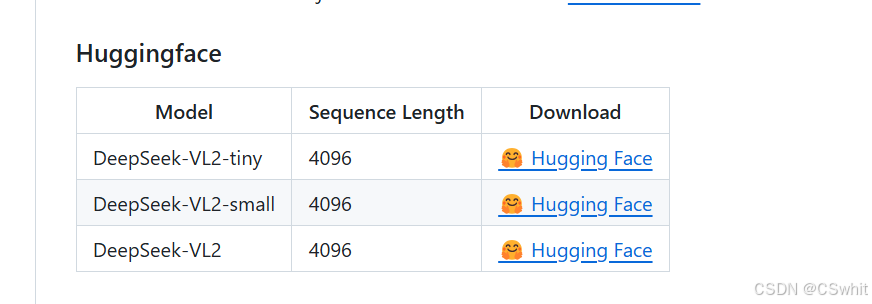
如上图所示,该表格清晰展示了DeepSeek-VL2的三个版本(tiny、small、VL2)的关键信息,包括各版本的序列长度和Hugging Face下载链接。这为开发者在本地部署时的模型选择提供了直接参考,帮助开发者根据自身硬件条件选择合适的模型版本,同时也提供了便捷的下载途径。
最后是启动服务。使用lmdeploy提供的命令行工具,执行lmdeploy serve api_server {模型存储路径} --tp {显卡数量}即可启动API服务。其中,{模型存储路径}需要替换为实际下载的模型文件所在目录,{显卡数量}指定用于推理的GPU数量。
在启动过程中,可能会遇到一些常见问题。例如,出现关于MKL_THREADING_LAYER的错误,可以通过设置环境变量解决:export MKL_THREADING_LAYER=GNU和export MKL_SERVICE_FORCE_INTEL=1。如果启动成功,控制台会输出相应的日志信息,指示服务已在指定端口监听请求。
部署经验与展望
回顾整个部署过程,我们遇到了不少挑战,但也积累了宝贵的经验。首先,硬件资源的评估至关重要。在选择模型版本时,必须充分考虑本地GPU的显存容量和内存大小,避免因资源不足导致部署失败。其次,环境配置的版本兼容性需要严格把控,尤其是PyTorch和CUDA的版本匹配,这直接关系到模型能否正常加载和运行。此外,选择合适的部署框架可以事半功倍,lmdeploy在当前阶段对DeepSeek-VL2的支持最为成熟,能够提供稳定的服务化部署能力。
对于未来的改进方向,我们期待看到更多针对DeepSeek-VL2的部署工具和教程出现,降低普通开发者的使用门槛。同时,随着硬件技术的进步,希望能够在消费级硬件上流畅运行更大规模的模型版本,以获得更强大的推理能力。此外,社区的力量也不可或缺,通过开发者之间的经验分享和问题排查,可以共同完善部署流程,推动多模态模型的普及应用。
总的来说,DeepSeek-VL2-Tiny的本地部署虽然存在一定挑战,但通过合理的硬件选型、严格的环境配置和正确的部署流程,是完全可以实现的。本文分享的经验希望能为广大开发者提供参考,助力更多人将先进的多模态AI技术应用到实际项目中,推动人工智能技术的落地和创新。随着技术的不断发展,相信未来的模型部署将更加便捷高效,为AI应用开辟更广阔的前景。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







