






YOLO领域太卷,2025年2月18日YOLO12来袭。由于官方发布的只是技术报告,详细细节还有待代码阅读后补上,因此只是简单解读。
1.原理
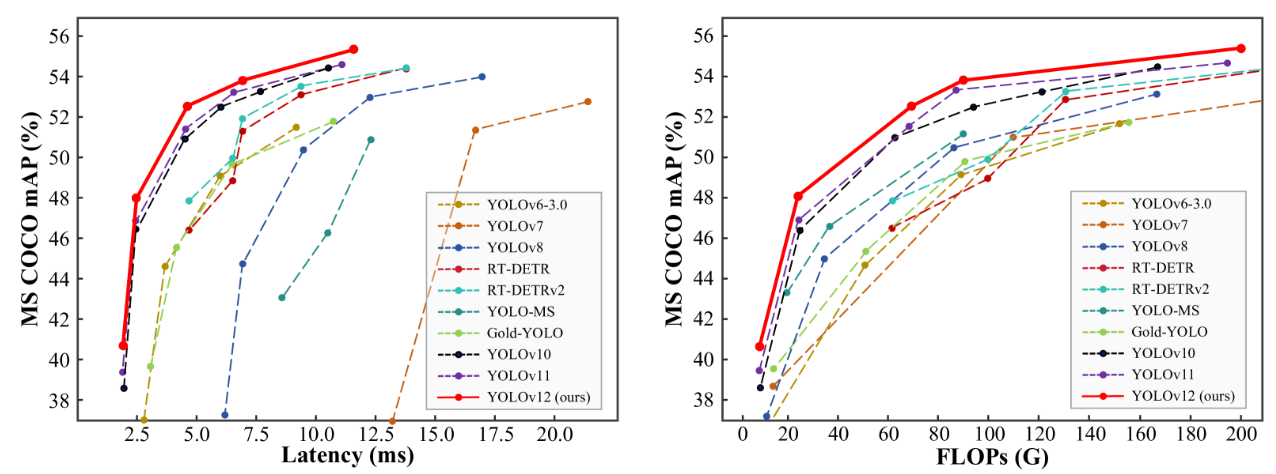
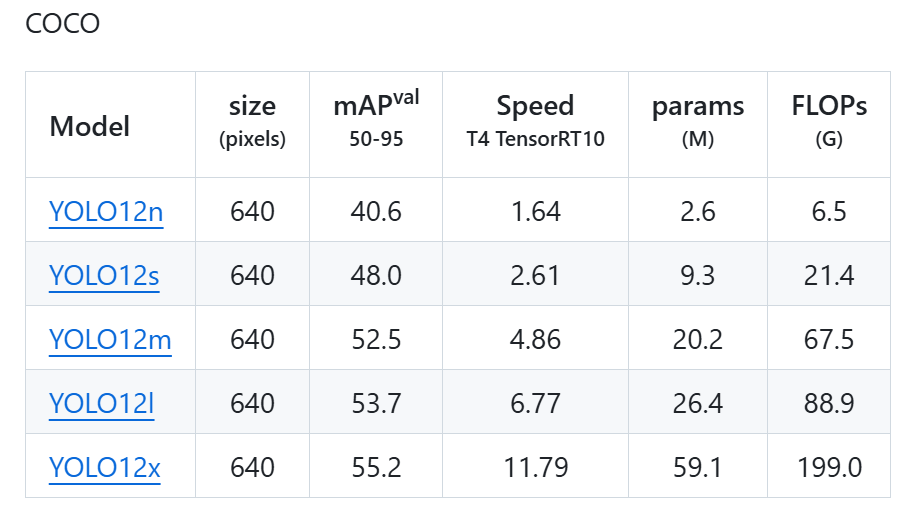
2025年2月18日由布法罗大学和中国科学院大学联合提出的YOLO12发布。YOLO12是以注意力为中心的实时目标检测器。长期以来,增强 YOLO 框架的网络架构一直至关重要,但尽管注意力机制在建模能力方面已被证明具有优越性,但仍然专注于基于 CNN 的改进。这是因为基于注意力的模型无法与基于 CNN 的模型的速度相媲美。本文提出了一个以注意力为中心的 YOLO 框架,即 YOLOv12,它与以前基于 CNN 的框架的速度相匹配,同时利用了注意力机制的性能优势。YOLOv12 在精度和速度上超越了所有流行的实时对象检测器。例如,YOLOv12-N 实现了 40.6 % 推理延迟为 1.64 ms 在 T4 GPU 上,性能优于高级 YOLOv10-N / YOLOv11-N 2.1 % / 1.2 % mAP 具有相当的速度。这一优势延伸到其他模型尺度。YOLOv12 还超越了改进 DETR 的端到端实时检测器,例如 RT-DETR / RT-DETRv2:YOLOv12-S 在运行时击败了 RT-DETR-R18 / RT-DETRv2-R18 42 % 更快,仅使用 36 % 的计算和 45 % 的参数。
本文旨在解决这些挑战,并进一步构建一个以注意力为中心的 YOLO 框架,即 YOLOv12。 论文介绍了三个关键改进。
首先,提出了一个简单而高效的区域注意力模块(A2),通过将特征图划分为多个区域(论文中是4),并只在这些区域内进行注意力计算,显著降低了计算复杂度,同时保持了较大的感受野。避免了复杂的窗口划分操作,只需简单的重塑操作,从而提高了速度。尽管感受野有所减小,但对性能的影响微乎其微。

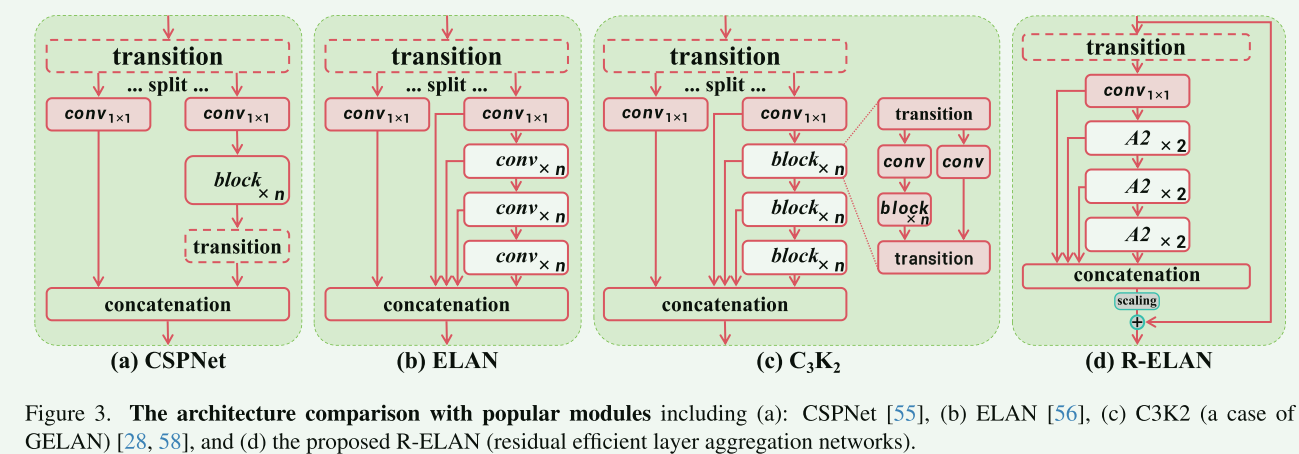
其次,引入了残差高效层聚合网络 (R-ELAN) 来解决注意力(主要是大规模模型)带来的优化挑战。R-ELAN 在原始 ELAN的基础上引入了两项改进:(i) 采用缩放技术的块级残差设计,引入残差连接,缓解了注意力机制带来的优化挑战,特别是对于大规模模型。,**以及 (ii)**设计了特征聚合方法,降低了计算成本,同时保持了性能。。 使用缩放技术,进一步稳定训练过程。
第三,在原版关注之外进行了一些架构改进,以适应 YOLO 系统。升级了传统的以注意力为中心的架构,包括:引入 FlashAttention 来克服注意力的内存访问问题,去掉位置编码等设计使模型快速干净,将 MLP 比率从 4 调整到 1.2,平衡了注意力机制和前馈网络的计算量,提高了性能。减少堆叠块的深度以方便优化, 并尽可能多地使用卷积运算符来利用其计算效率。
YOLOv12 的贡献:
1) 建立了一个以注意力为中心、简单而高效的 YOLO 框架,通过方法论创新和架构改进,打破了 CNN 模型在 YOLO 系列中的主导地位
2) 无需依赖预训练等额外技术,YOLOv12 即可以快速的推理速度和更高的检测精度获得最先进的结果,展示了其潜力。
性能:
从论文中看YOLOv12 需要更长的训练时间才能达到最佳性能。根据文档中的表格 5c,YOLOv12 需要 600 个训练周期才能达到最佳性能,而 YOLOv11 只需要大约 500 个训练周期。
YOLOv12 的设计是否完全取代了 CNN 的使用?
虽然论文标题是以注意力为中心,但仍然保留了 CNN 的一些优势,并将其与注意力机制相结合,以实现更好的性能和效率。YOLOv12 仍然使用卷积操作来提取特征,并利用其计算效率。YOLOv12 使用卷积操作来实现位置感知,帮助注意力机制更好地理解图像中的位置信息。YOLOv12 将 MLP 比率从 4 调整到 1.2,平衡了注意力机制和前馈网络的计算量,其中前馈网络包含卷积操作。
本地部署及测试
源码:github.com/sunsmarterjie/yolov12
环境安装:
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
conda activate yolov12
pip install -r requirements.txt
pip install -e .
验证:
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.val(data='coco.yaml', save_json=True)
选练:
from ultralytics import YOLO
model = YOLO('yolov12n.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="0,1,2,3",
)
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("path/to/image.jpg")
results[0].show()
预测:
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.predict()
模型导出:
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.export(format="engine", half=True) # or format="onnx"
Demo:
python app.py
# Please visit http://127.0.0.1:7860

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









