




1.环境安装
硬件配置最好内存>=16GB,显卡NVIDIA 20系列及其以上显卡,显存>=8GB
建议新建虚环境:
conda create -n yolo11 python=3.10
进入虚环境,查询CUDA支持的最高版本:
conda activate yolo11
nvidia-smi
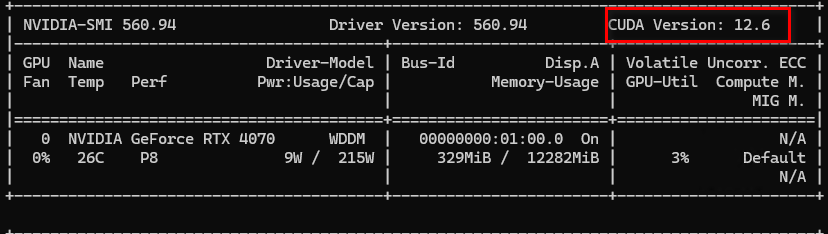
进入Pytorch官网,下载Pytorch-GPU版本,建议2.0以上版本,CUDA不高于你显卡的版本的都行,我这里下载的是:
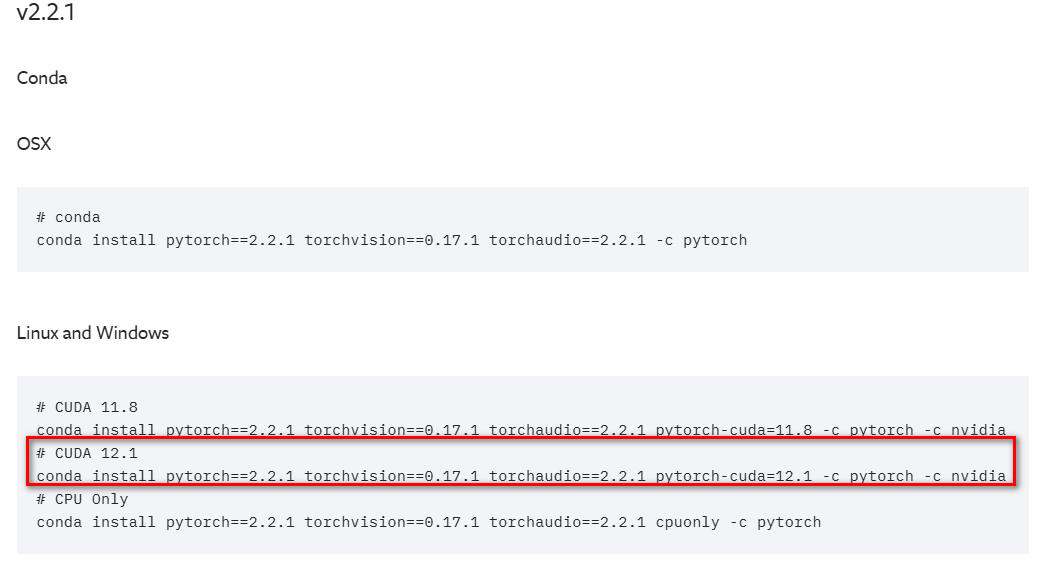
conda install pytorch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 pytorch-cuda=12.1 -c pytorch -c nvidia
打开requirements.txt,将其中的如下三行删除,否则会再次安装一遍
torch==2.2.1+cu121
torchaudio==2.2.1+cu121
torchvision==0.17.1+cu121
保存关闭后,用cd命令将路径切换到requirements.txt下,
cd requirements.txt文件所在的路径(替换为自己的实际路径)
安装其他依赖包
pip install -r requirements.txt --timeout 6000
已经自动安装了包含YOLO11的ultralytics包,后面可以直接用命令行训练。
2.王者荣耀英雄状态检测
2.1 数据集获取
这里可以从网上下载王者荣耀游戏视频,或者本地游戏时候保存的视频,然后用视频工具或者QQ截屏截取不同的游戏画面图片后,用labelme手动标注。我这里标注了886张图片,共计6个英雄状态类别:attacked_by_tower(被塔打), death(死亡),destroy_towers(打塔), kill_heroes(杀死英雄), kill_minions_monsters(杀怪), killed(被杀),其中划分数据集如下:训练集619张,验证集177张,测试集90张。
在项目路径下创建data目录,将训练集、验证集和测试集图片放在该路径下,编写data.yaml文件如下:
train: train/images
val: valid/images
test: test/images
nc: 6
names: ['attacked_by_tower' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6692
6692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









