




Zeng J, Liu T, Zhou J. Tag-assisted multimodal sentiment analysis under uncertain missing modalities[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022: 1545-1554.【开放源码】
【论文概述】
本文提出了一种名为“标签辅助变换器编码器(TATE)网络”的新型多模态情感分析方法,旨在解决在不确定的多模态数据中部分模态缺失的问题。该方法通过引入一个标签编码模块来处理单个或多个模态的缺失情况,引导网络注意力集中于缺失的模态。此外,还采用了一种新的空间投影模式来对齐共同的向量,并使用变换器编码器-解码器网络来学习缺失模态的特征。实验表明,该模型在CMU-MOSI和IEMOCAP数据集上比几个基准模型表现更好,显示了该方法的有效性和优越性。
【模型结构】
主要工作流程如下:对于一个给定的视频片段,假设视觉模态和听觉模态缺失,首先将这些缺失的模态标记为0,然后提取剩余的原始特征。之后,被掩蔽的多模态表示通过两个分支进行处理:1)一个分支由预训练模型编码,该模型是用所有完整模态数据训练的;2)另一个分支通过标签编码模块和公共空间投影模块来获取对齐的特征向量。然后,更新的表示由Transformer编码器处理,并计算预训练向量和编码器输出之间的前向相似性损失。同时,编码输出被输入到分类器中进行情感预测。最后,计算反向重构损失和标签恢复损失以指导联合表示学习。

- Tag Encoding
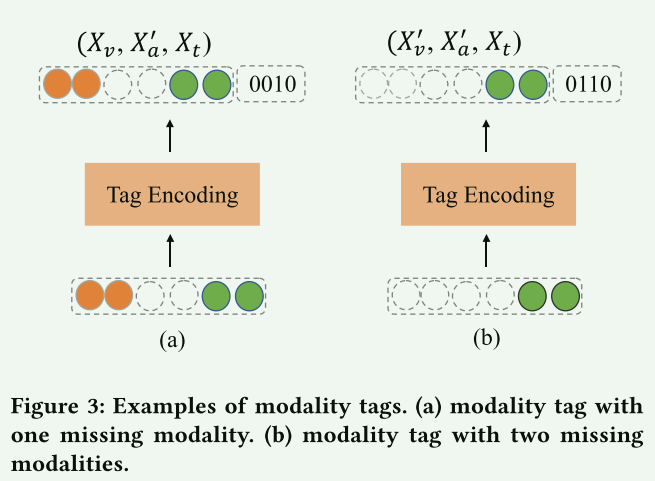
为了确定不确定的缺失模态,采用标签编码模块来标记,并将网络的注意力引导到这些缺失的模态上。采用4位数字(“0”或“1”)来标记缺失的模态。如果输入的部分模态丢失,将第一个数字设置为“0”,否则设置为“1”。此外,最后三位数字用于标记相应的视觉、听觉和文本模态。设置标签的好处是双重的:1)标签编码模块可以覆盖单个和多个模态缺失条件;以及2)编码的标签可以互补地辅助联合表示的学习。
-
Common Space Projection
首先基于以下线性变换获得自相关公共空间:
C v = [ W v a E v ∥ W v t E v ] , C a = [ W v a E a ∥ W t a E a ] , C t = [ W v t E t ∥ W t a E t ] , \begin{array}{l} C_{v}=\left[W_{v a} E_{v} \| W_{v t} E_{v}\right], \\ C_{a}=\left[W_{v a} E_{a} \| W_{t a} E_{a}\right], \\ C_{t}=\left[W_{v t} E_{t} \| W_{t a} E_{t}\right], \end{array} Cv=[WvaEv∥WvtEv],Ca=[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4148
4148




 到【灌水乐园】发言
到【灌水乐园】发言







