




 本文是首篇专注医学视觉语言预训练(VLP)的综述。探讨多模态学习方法,分析多种目标函数优缺点,介绍相关附加方面、数据增强技术、架构等。阐述其在多种医学任务的应用,指出预训练数据、医学特殊性等方面的挑战,并对未来发展提出展望。
本文是首篇专注医学视觉语言预训练(VLP)的综述。探讨多模态学习方法,分析多种目标函数优缺点,介绍相关附加方面、数据增强技术、架构等。阐述其在多种医学任务的应用,指出预训练数据、医学特殊性等方面的挑战,并对未来发展提出展望。
arXiv:2312.06224Submitted 11 December, 2023; originally announced December 2023.
这篇综述文章很长,本文对各部分简要概述。
【文章整体概述】
医学视觉语言预训练(VLP)最近已经成为解决医学领域标记数据稀缺问题的一种有希望的解决方案。通过利用成对或非成对的视觉和文本数据集进行自监督学习,模型能够获得大量知识并学习强大的特征表示。这样的预训练模型有潜力同时提升多个下游医学任务,减少对标记数据的依赖。然而,尽管近期取得了进展并显示出潜力,目前还没有一篇综述文章全面探讨了医学VLP的各个方面和进展。在本文中,特别审视了现有工作,通过不同的预训练目标、架构、下游评估任务和用于预训练及下游任务的数据集的视角。随后,深入探讨了医学VLP中的当前挑战,讨论了现有和潜在的解决方案,并以展望未来的发展方向作为结论。这是第一篇专注于医学VLP的综述。
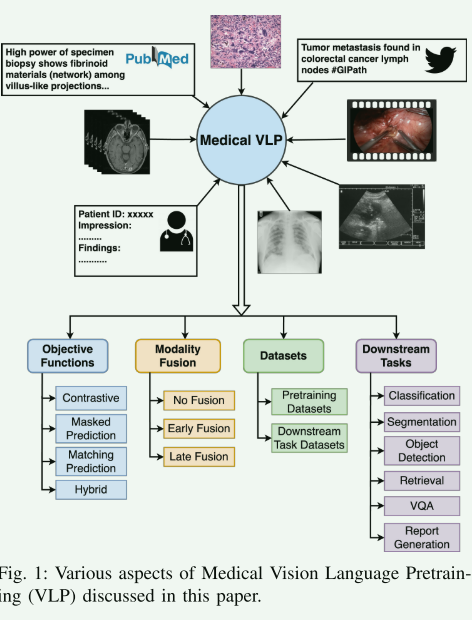
【IV.MULTIMODAL LEARNING APPROACHES】
在第四部分“多模态学习方法”中,本文探讨了多模态学习在医学领域的应用,尤其是监督和自监督学习方法的使用。
A. 监督多模态学习: 这一部分讨论了监督多模态学习,其中需要依赖于真实标签(ground truth labels)来学习预测模型。监督学习在医学领域面临着由于需要大量标注数据而引发的挑战,这一挑战由专业领域专家对医学数据进行注释的需求和隐私问题的日益增长进一步加剧。
B. 自监督多模态学习: 自监督学习分为预训练和下游任务学习两个阶段。在预训练阶段,自监督方法不依赖于真实标签,而是使用数据中的其他形式的自生成的监督作为目标函数来训练预测模型。这种方法通过替换监督目标中的真实标签为伪标签来实现。预训练后,训练好的模型用于学习使用真实标签的特定下游任务。自监督预训练步骤减少了对标注数据的依赖,并在某些情景下显示出优于全监督模型的性能。在医学领域,获取标注数据是一个重大障碍,自监督学习显示出高效性。尽管缺乏注释标签,医学数据集通常包含图像和详细的文本报告,为自监督预训练提供了宝贵的资源。
总体而言,这一部分强调了在医学领域中多模态学习的重要性,特别是自监督学习在利用大规模医学图像和文本数据中的潜力。
【V. MEDICAL VLP OBJECTIVE FUNCTIONS】
在第五部分“医学VLP目标函数”中,各种目标函数的常用模型和方法被详细讨论,图画得很好,这里总结一下它们的优缺点:
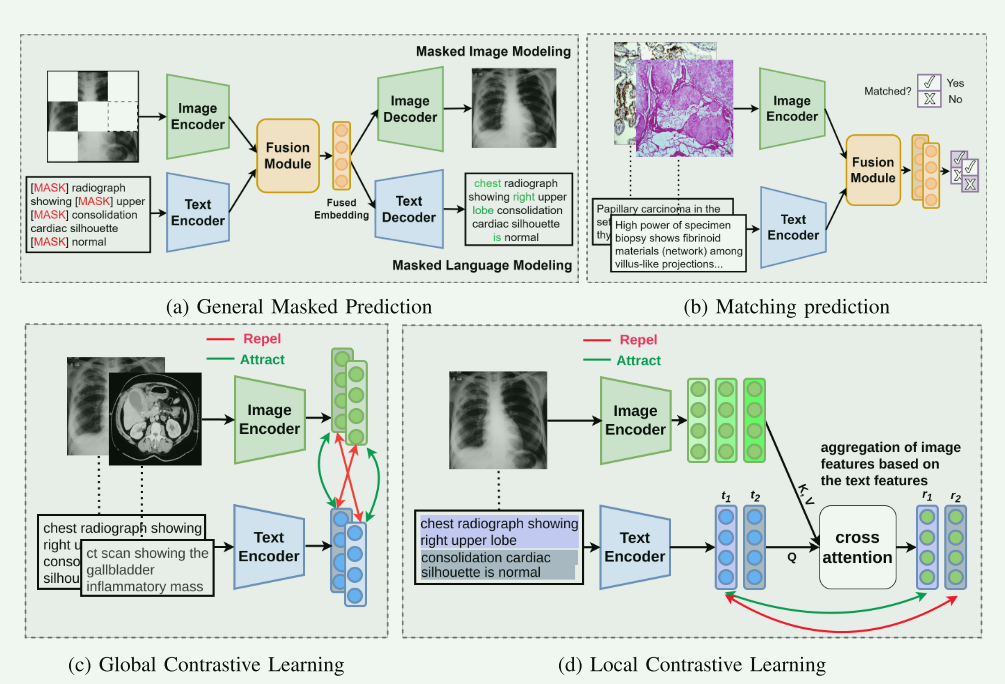
A. 掩码预测:
-
常用模型:这种方法常用于BERT-like的模型,其中模型被训练来预测在文本或图像中被随机掩盖的部分。Masked Prediction的常用任务如:Masked Language Modeling (MLM)、Masked Image Modeling (MIM)。代表模型:MMBERT
-
优点
- 上下文理解:掩码预测方法强迫模型关注上下文信息来预测被掩盖的部分。这种方法特别适合于学习深层次的上下文依赖关系,从而增强模型的理解能力
- 深度特征学习:通过预测掩码部分,模型能够学习到数据的深层特征和细节。这对于理解复杂的医学图像和报告中的微妙差异尤其有用
- 鲁棒性:掩码预测方法提高了模型对不完整或缺失信息的处理能力,从而提升了模型在现实世界应用中的鲁棒性。
- 强大的语言模型:在文本处理方面,掩码预测类似于BERT架构,已被证明在多种自然语言处理任务中非常有效。
-
缺点
1.侧重单一模态:掩码预测方法可能过分侧重于在单一模态(如文本或图像)内的特征学习,而不是跨模态(即图像和文本之间)的特征关联。
- 计算开销:这种方法可能需要较大的计算资源,特别是在处理大型医学数据集时,因为需要生成和处理大量的掩码变体。
- 局限性于特定上下文:虽然这种方法在学习上下文信息方面非常有效,但它可能不适用于需要全局理解或跨多个上下文的任务。
- 预训练与下游任务不一致:在预训练和下游阶段之间会出现轻微的域间隙,预训练阶段需要屏蔽输入,而下游任务涉及未屏蔽输入。因此,仅依赖于掩蔽预测目标的方法缺乏下游zero-shot能力。
B. 对比学习:
-
常用模型:使用诸如Siamese网络架构的模型,这些模型通过比较正负样本对来学习区分特征。代表模型ConVIRT、PubMedCLIP、BiomedCLIP、IMITATE、GLORIA、LIMITR、LRCLR、LOVT、MedCLIP、KoBo
-
优点
- 区分能力:对比学习通过区分正负样本对,强化了模型的区分能力。这对于理解和区分医学图像和文本中的细微差异尤其有价值。
- 有效的特征提取:这种方法有效于提取和学习有区分性的特征,这在大规模未标注的医学数据集中尤为重要。
- 鲁棒性和泛化能力:对比学习增强了模型对于不同样本的泛化能力,并提高了在面对新数据时的鲁棒性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6691
6691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









