






本文来源公众号“数据派THU”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/zBGNR6WEATOSM2RV9RWDNQ
在大型语言模型的预训练中,数据质量一直被视为模型性能的决定性因素。传统做法是尽可能过滤掉“坏数据”(如毒性内容),以避免模型生成有害输出。然而,这篇论文提出了一个反直觉的观点:在预训练中适度加入有毒数据,反而能通过后训练技术(如推理时干预)更有效地降低模型毒性,同时保持模型的一般能力。

-
论文:When Bad Data Leads to Good Models
-
链接:https://arxiv.org/pdf/2505.04741
论文通过严谨的玩具实验和真实模型实验,揭示了数据组成如何影响模型内部表示的“纠缠”程度,并证明有毒数据能帮助模型更清晰地学习毒性概念,从而在后训练中更容易被“矫正”。这一发现不仅挑战了数据过滤的常规做法,还为预训练与后训练的协同设计提供了新思路。
研究动机:为什么重新审视“坏数据”?
传统上,LLM预训练会严格过滤毒性数据,以减少模型生成有害内容的风险。然而,这种做法可能导致两个问题:
-
数据多样性下降:模型无法全面学习现实世界的复杂性。
-
概念表示不完整:毒性概念可能与其他特征“纠缠”在一起,难以在后训练中精准控制。
论文引入了一个新视角:将预训练和后训练视为一个整体系统。作者假设,增加预训练中的毒性数据比例,可以提升模型的“对齐能力”,即在后训练中更容易被引导至无害方向。这一想法受到近期研究的启发:对齐算法(如RLHF)往往只是“绕过”而非“消除”毒性机制,因此强化模型对毒性的内部表示可能更有效。
如果模型无法真正“忘记”毒性,不如让它更好地“理解”毒性,从而在后训练中更可控。
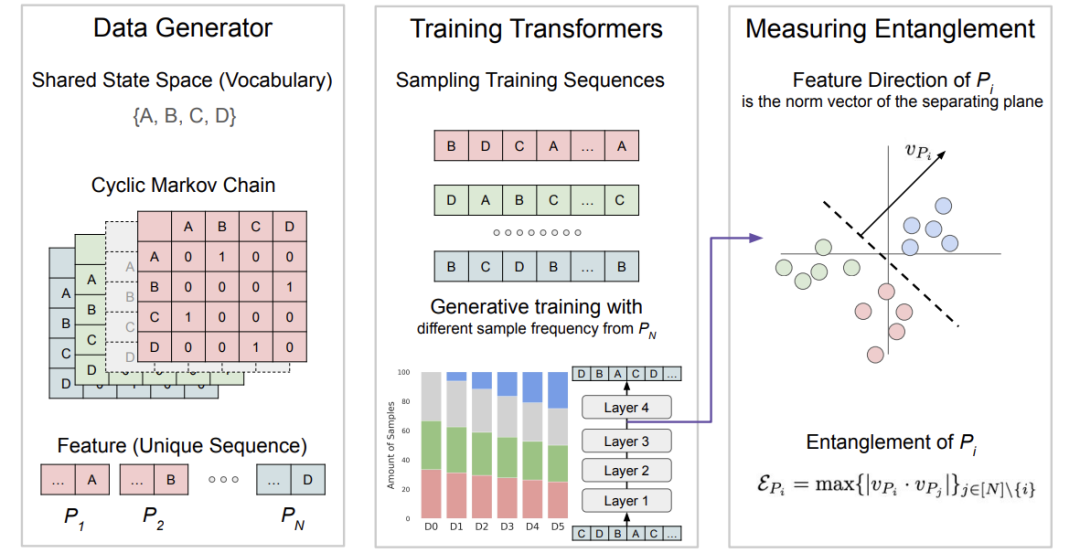
理论框架:从玩具实验看特征纠缠
为了验证数据组成如何影响特征表示,作者设计了一个玩具实验,基于Elhage等人提出的“叠加假设”:当特征数量超过神经元数量时,模型会将多个特征的表示压缩到同一维度中,导致“纠缠”。
特征纠缠的度量
论文定义了一个数学公式来衡量特征的纠缠程度:

可以这么理解:就像在一间拥挤的房间里,每个人都在同时说话。如果某个人(特征)的声音与其他人的声音重叠度很高,你就很难单独听清他。纠缠度量就是衡量这种“重叠度”。
玩具实验设计
作者使用一个4层Transformer,在由多个马尔可夫链生成的序列数据上训练,其中某些特征(序列)被故意 underrepresented。通过调整这些特征的数据比例,观察其纠缠度的变化。
实验结果显示,随着 underrepresented 特征的数据比例增加,其纠缠度显著下降(见下图)。
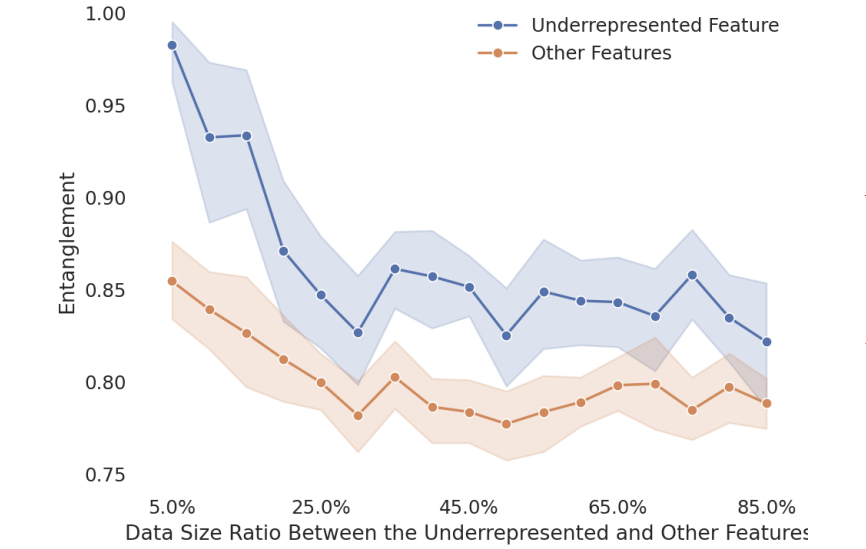
启示:如果预训练数据中毒性内容过少,毒性概念可能与其他特征高度纠缠,导致后训练中任何干预都会“误伤”其他能力。相反,增加毒性数据可以使毒性表示更独立,便于精准控制。
真实模型实验:Olmo-1B与有毒数
为了在真实场景中验证这一假设,作者训练了一系列Olmo-1B模型,使用不同比例的“干净数据”(C4)和“有毒数据”(4chan)。毒性数据比例从0%逐步增加到25%,同时保持干净数据量不变,以排除数据量减少的干扰。
基础模型评估
作者使用MMLU(通用能力基准)和Toxigen(毒性检测数据集)评估模型:
-
通用能力:适度增加毒性数据对MMLU分数影响很小,甚至略有提升。
-
毒性检测:随着毒性数据增加,模型对毒性内容的识别能力显著提升。
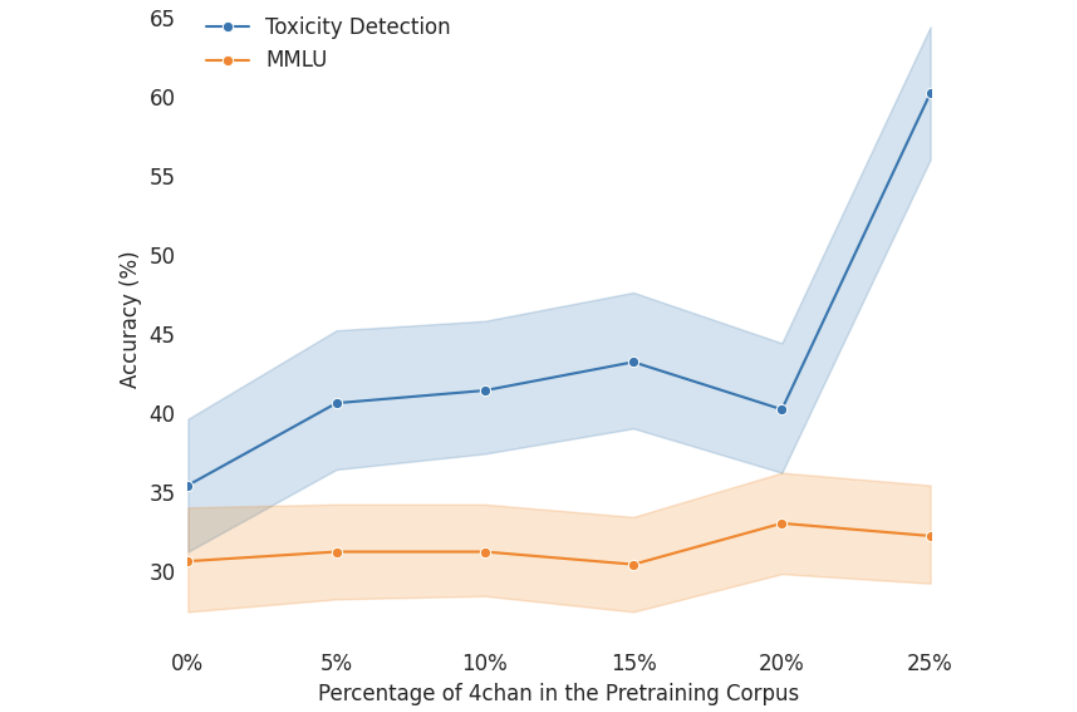
发现:毒性数据并未导致模型能力崩溃,反而提升了其对毒性概念的理解。
核心发现:有毒数据如何改善概念表示
线性探测实验
作者在模型各层的注意力头上训练线性分类器,判断输入是否具有毒性。结果显示,加入毒性数据的模型在探测准确率上显著更高,且出现更多“高准确率头”。
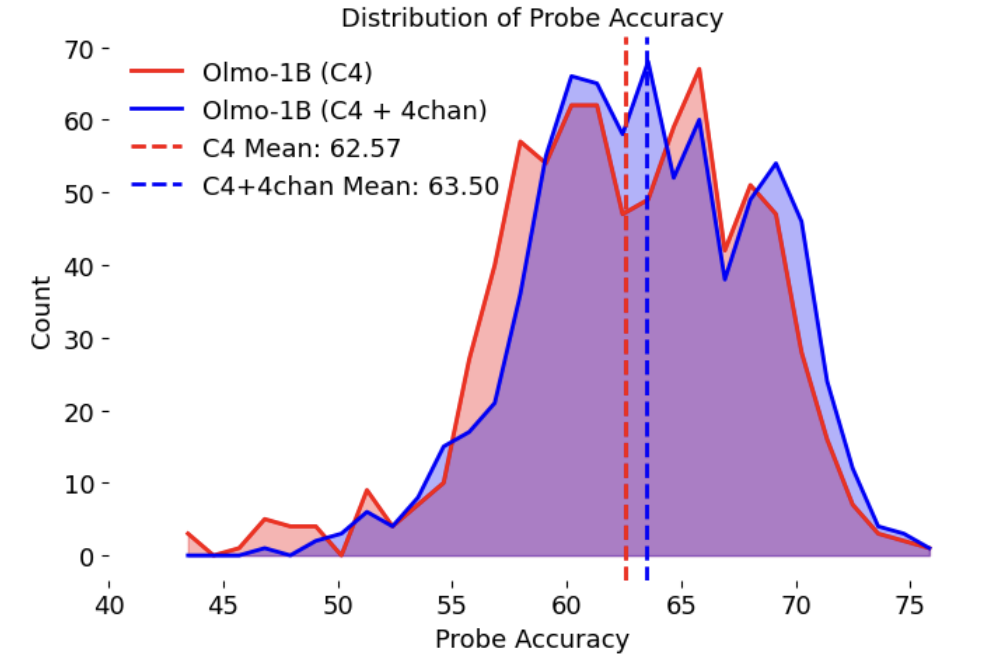
意义:这些“高准确率头”就像模型的“毒性传感器”,在后训练干预中可以精准定位,减少对一般能力的损害。
口头化实验
通过Logit Lens技术,作者找出与毒性方向最接近的50个词。结果显示,加入毒性数据的模型能识别更多真实毒性词汇(如“stupid”、“Jew”、“hate”),而仅训练在干净数据上的模型则更多与中性词关联。
证据:毒性数据帮助模型建立了更准确、更线性的毒性表示。
后训练对齐:推理时干预(ITI)的效果
推理时干预是一种在生成过程中调整模型激活值的技术。作者通过识别与毒性相关的方向,在解码时“推开”激活值,从而降低毒性输出。
干预强度设置
-
弱(4)、中(8)、强(12)三种干预强度。
-
干预头部固定为30个高准确率头。
结果分析
-
无干预时:毒性数据比例越高,基础模型毒性越强。
-
应用ITI后:毒性数据比例在10%左右时,模型毒性显著降低,形成“微笑曲线”。
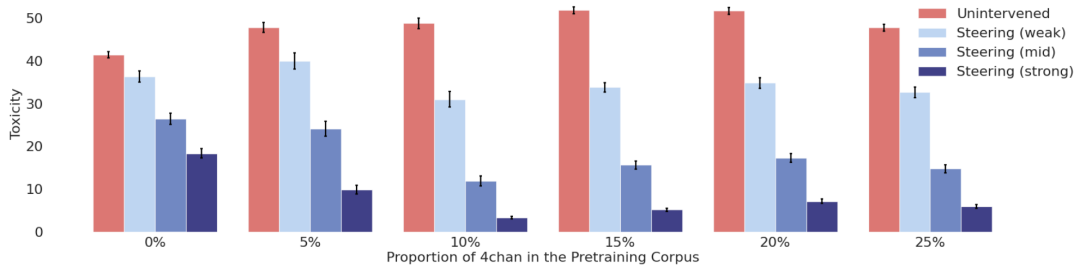
发现:坏数据(毒性内容)在预训练中帮助模型建立了更清晰的毒性表示,使得后训练干预更有效。
实验验证:与其他方法的对比
作者将“预训练加毒”方法与多种基线方法对比,包括:
-
提示工程:使用无害提示词。
-
MEDA/INST:在数据中添加毒性标注。
-
SFT/DPO:监督微调与直接偏好优化。
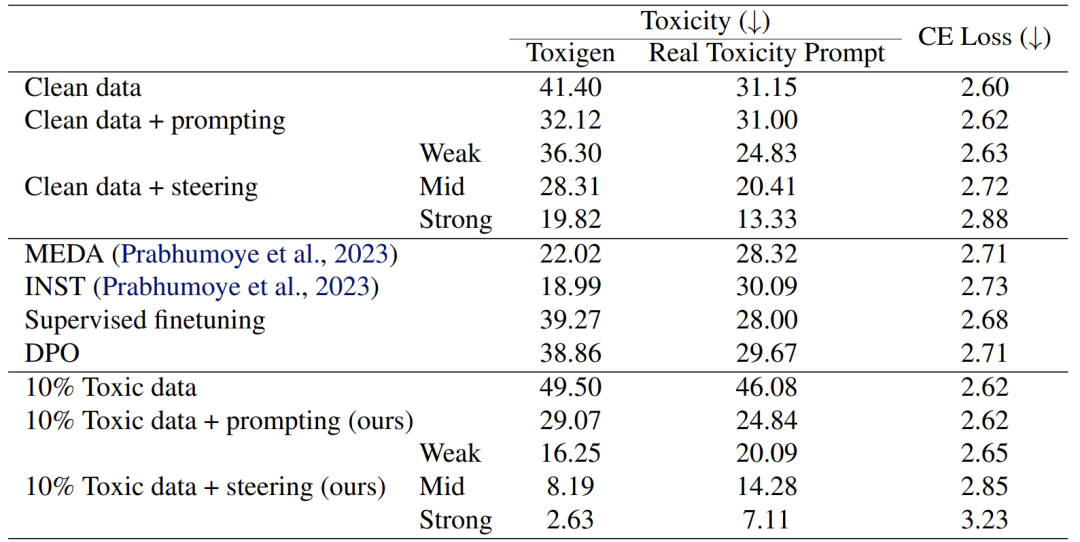
结果显示:
-
在10%毒性数据 + 弱干预下,模型在Toxigen和Real Toxicity Prompts上的毒性最低,且交叉熵损失(衡量能力损失)最小。
-
在红队测试中,该组合对GCG攻击的抵抗能力最强。

优势:该方法在降低毒性的同时,最大程度保留了模型的一般能力,且无需在数据中插入人工标注。
结论
这篇论文通过严谨的理论分析和实验验证,颠覆了“坏数据必须过滤”的传统认知。研究发现:
-
适度增加毒性数据可以帮助模型建立更清晰、更易控制的毒性表示。
-
在后训练干预下,这些模型更容易被“ detoxify”,同时保持强大的一般能力。
这项工作呼吁社区以更系统、更实证的视角看待数据筛选,将预训练与后训练视为一个整体,追求最终部署效果的最优解。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 6550
6550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









