




本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/mqp8X8CebvmuCZhFJIm26w
jina-vlm 模型概述
jina-vlm 是一个由 Jina AI(位于柏林)提出的 2.4B 参数视觉-语言模型(VLM),它在多语言视觉问答(VQA)方面,在同等规模(2B 级)的开放 VLMs 中取得了最先进的(state-of-the-art)性能。
https://huggingface.co/jinaai/jina-vlm
https://arxiv.org/pdf/2512.04032
jina-vlm 采用了典型的 VLM 架构,并结合了以下关键组件:
-
视觉编码器 (Vision Encoder): 采用 SigLIP2-So400M/14-384。
-
语言骨干 (Language Backbone): 采用 Qwen3-1.7B-Base。
-
连接器 (Connector): 采用注意力池化连接器 (attention-pooling connector) 。
jina-vlm 在八个通用 VQA 基准测试中取得了最高的平均分数 (72.3),显示出其在处理图表、文档、场景文本和 OCR 等多样化视觉问题方面的强大能力。
| Model | Params | VQA Avg | MMMB | MM-Bench | RealWorld QA |
|---|---|---|---|---|---|
| jina-vlm | 2.4B | 72.3 | 78.8 | 74.3 | 68.2 |
| Qwen2-VL-2B | 2.2B | 66.4 | 71.3 | 69.4 | 62.9 |
| Qwen3-VL-2B | 2.2B | 71.6 | 75.0 | 72.3 | 63.9 |
| InternVL3-2B | 2.2B | 69.2 | 73.6 | 71.9 | 64.3 |
| InternVL3.5-2B | 2.2B | 71.6 | 74.6 | 70.9 | 62.0 |
jina-vlm 模型架构
jina-vlm 的架构设计旨在高效地处理任意分辨率图像,同时最大限度地减少输入到语言模型的视觉 tokens 数量。
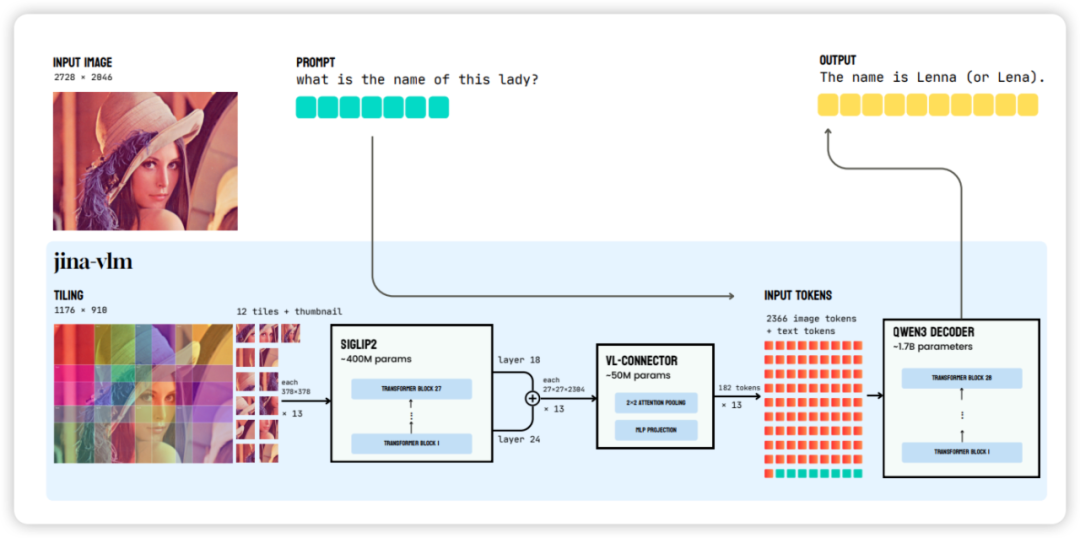
-
视觉编码器: 使用 SigLIP2-So400M/14-384(27 层,400M 参数)。它将 像素的输入图像处理成 的 补丁网格。
-
任意分辨率处理: 采用重叠图像平铺 (overlapping image tiling) 策略:
-
图像被分解成重叠的 像素图块(tiles)。相邻图块重叠 112 像素,步长为 266 像素。
-
每个图块独立通过编码器处理。
-
一个全局缩略图 (global thumbnail)(将完整图像缩放至 378)也被处理以提供上下文。
-
默认配置: 训练时使用 12 个图块 + 1 个缩略图。这使得模型能够处理高达 像素的有效分辨率。图块数量可以增加,内存消耗与图块数量呈线性关系。
-
连接器的主要目标是将高维度的视觉特征高效地压缩并映射到语言模型的嵌入空间。

语言解码器 (Language Decoder) 初始化自 Qwen3-1.7B-Base,该基础版本经验证优于其指令微调版本。并引入了三个特殊 tokens 来组织视觉输入:<image> 和 </image> 用于定界图像和缩略图序列;<patch_end> 标记补丁网格中的行边界。
最终注意力池化带来了显著的计算优势:
| Metric | No Pooling | With Pooling | Reduction |
|---|---|---|---|
| Visual tokens | 9,477 | 2,366 | 4.0× |
| LLM prefill FLOPs | 27.2 TFLOPs | 6.9 TFLOPs | 3.9× |
| KV-cache memory | 2.12 GB | 0.53 GB | 4.0× |
jina-vlm 模型训练
训练分为两个阶段,两个阶段都更新模型的所有组件(编码器、连接器和解码器),不进行冻结。总数据量约 5M 多模态样本和 12B 文本 tokens,涵盖 30 多种语言。
阶段 1: 对齐训练 (Alignment Training)
-
目标: 侧重于跨语言语义基础(semantic grounding),而非特定任务。
-
数据: 主要使用 caption 数据集(如 PixmoCap、PangeaIns),涵盖自然场景、文档、信息图表和图表。
-
文本保留: 包含 15% 的纯文本数据(来自 PleiAS/common corpus),以减轻对纯文本任务性能的退化。
-
学习率 (LR): 连接器 (Con.) 使用更高的学习率和更短的 Warmup 时间,以更快地将视觉和语言空间对齐。
阶段 2: 指令微调 (Instruction Fine-Tuning)
-
目标: 训练模型以执行 VQA 和推理任务的指令。
-
数据: 结合了各种公共数据集集合(如 LLaVA OneVision、Cauldron、Cambrian、PangeaIns、FineVision)和纯文本指令数据。混合数据涵盖 VQA、文档理解、OCR、数学和推理。
-
批次策略: 首先使用 单源批次 (single-source batches) 训练 30K 步(可能因数据混合的异构性更有效),然后使用 混合源批次 (mixed-source batches) 训练 30K 步。
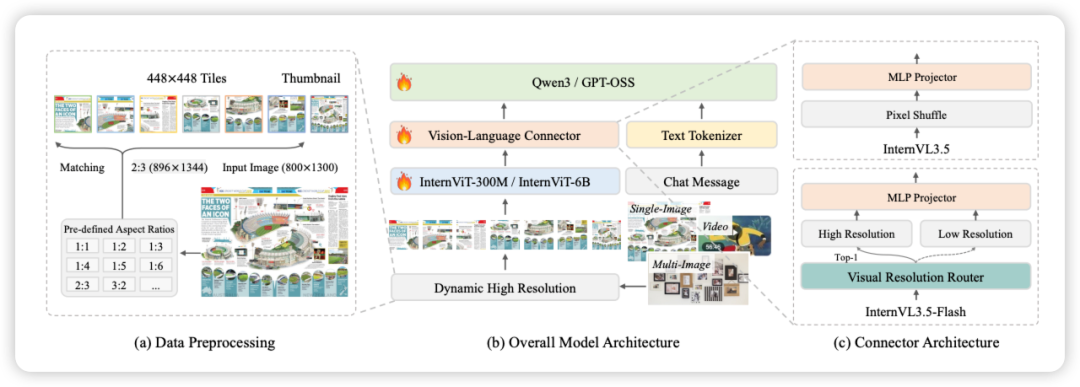
InternVL3.5 模型概述
https://arxiv.org/pdf/2508.18265
https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B
InternVL3.5 系列在继承前作 “ViT–MLP–LLM” 架构范式的基础上,着重在效率、推理和通用性上进行了升级。该系列包括密集型(Dense)和专家混合型(MoE)模型,参数规模从 1.1B 到 240.7B 不等。
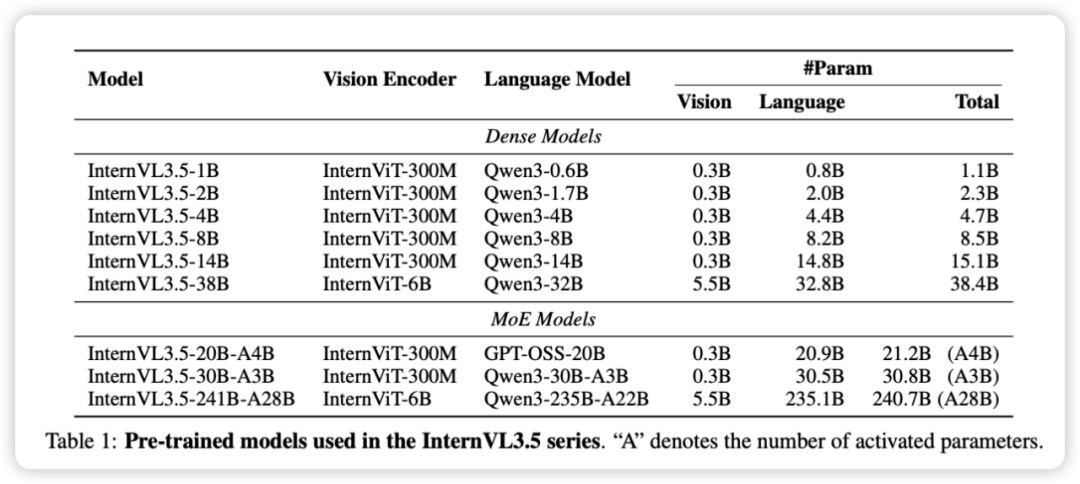
| 模型类型 | 视觉编码器 | 语言模型 | 总参数 |
|---|---|---|---|
| 密集型 (Dense) | InternViT-300M / InternViT-6B | Qwen3 系列 | 1.1B 至 38.4B |
| MoE 型 | InternViT-300M / InternViT-6B | GPT-OSS / Qwen3 | 21.2B 至 240.7B |
预训练 (Pre-Training)
采用下一词元预测损失 (Next Token Prediction, NTP),同时更新所有模型参数(ViT、MLP、LLM)。为避免长短回复的偏置,采用了平方平均 (square averaging) 的方法对 NTP 损失进行重新加权。

后训练 (Post-Training)
后训练分为三个阶段:监督微调 (SFT)、级联强化学习 (Cascade RL) 和 视觉一致性学习 (ViCO)。
视觉一致性学习 (Visual Consistency Learning, ViCO) 将 ViR 模块集成到 InternVL3.5 中,创建高效的 InternVL3.5-Flash 版本。训练整个模型以最小化不同视觉压缩率下响应分布的散度(KL 散度),确保压缩后性能不下降。参考模型始终使用 256 tokens 进行推理。
测试时间扩展 (Test-Time Scaling, TTS)
TTS 是一种在推理时增强推理能力的有效方法,它同时提高了推理深度和推理广度。
-
深度思维 (Deep Thinking): 激活 Thinking 模式,引导模型在生成最终答案前进行多步骤的分解和推理。
-
并行思维 (Parallel Thinking): 采用 Best-of-N (BoN) 策略
InternVL3.5 实验
主要基于 XTuner 框架,集成了 FSDP、数据打包、FP8 训练、FlashAttention-3 和 MoE 训练优化。在线 RL 阶段使用 verl 代码库。
视觉处理、特征传输和语言处理被组织成异步三阶段管线,实现计算重叠,最大化并行性和硬件利用率。视觉计算可以与 LLM 的 Prefilling 和 Decoding 阶段并行执行,极大地缓解了阻塞和资源冲突,提高了吞吐量和响应速度。
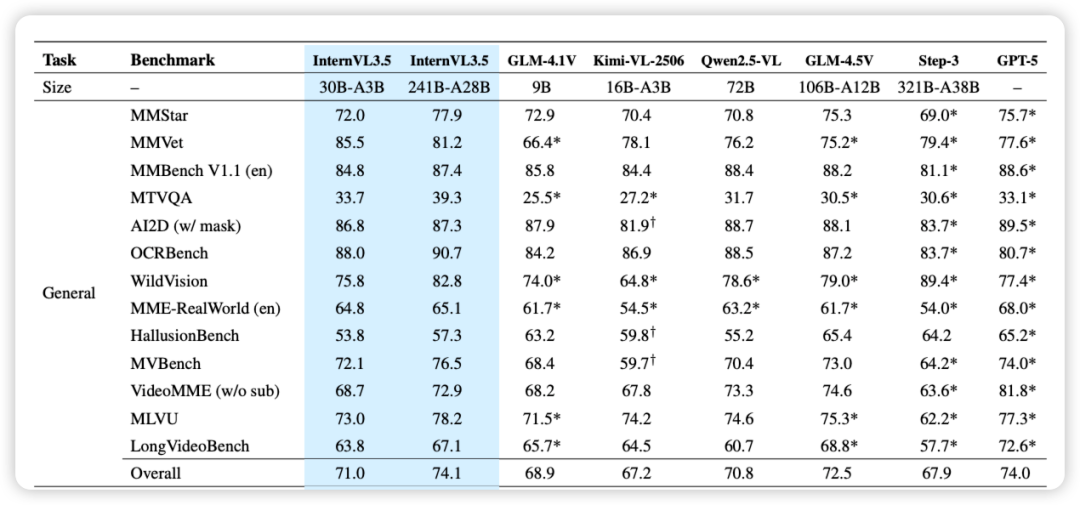
InternVL3.5 在 35 个基准测试中,按四大任务类型进行了全面评估:通用任务、推理任务、以文本为中心的任务和 Agent 任务。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









