




本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/te_NG7iyuNC1qBAy08280w
大模型驱动下基金产品的长周期申购和赎回预测
-
赛题名称:AFAC2025挑战组 基金产品的长周期申购和赎回预测
-
赛题类型:时序预测(Time Series Forecasting)/ 回归预测(Regression)
-
赛题任务:利用提供的20只基金的历史申购和赎回时间序列及有限的平台侧关键特征
赛题背景
作为一站式理财服务平台,蚂蚁财富为广大投资者提供了便捷且高效的基金交易功能,每天支撑大规模基金申购和赎回交易。精准预测基金产品在未来一段时间的申购量和赎回量具有重大意义:从平台角度,定量把握基金产品的申赎情况,一方面能够科学地指导平台落实各项流动性管理动作,从而降低由平台垫资而产生的资金成本,另一方面能够揭示行业板块间的资金流向,有针对性地部署申赎预警和运营策略,从而避免AUM流失。
从用户角度,根据基金产品的申赎数据,可以提前提示相关机构锁定基金份额、做好交易准备,同时结合投资研判给到的干预策略,有效降低用户的收益摩擦、保证用户的收益体感。
赛题任务
本赛题提供 20 只基金的历史申购和赎回时间序列以及有限个平台侧关键特征(数据样例见 任务数据 部分),参赛者需要(1)借助大模型自行获取和构造其他有效特征,(2)训练 1 个时序模型,有效建模产品收益和市场行情波动,预测每只基金在 2025/7/25 - 2025/7/31 7 天内每天的申购量和赎回量。
特征构造应尽可能使用大模型:金融类特征(如产品收益、行情等)强制要求使用大模型构造;非金融类特征(如是否交易日等)可以手动构造。 我们最终结合大模型使用能力和模型预测精度综合判定参赛者成绩。
需要注意的是,参赛者只能使用开源大模型(< 64B),最终成绩综合申赎预测精度和大模型使用能力综合判定。
赛题数据集
任务数据本赛题数据集为 fund_apply_redeem_series.csv,此数据表包含 7 列数据,涵盖 3 类信息:
-
基金code(fund_code),参赛者可以根据基金code检索并构造相关特征;
-
基金的历史申购和赎回序列数据,2024/4/8 以来每日(transaction_date)申购量(apply_amt)和赎回量(redeem_amt);
-
平台侧关键特征,包括 3 个核心交易页面的曝光uv。
特别指出的是,在比赛期间,我们会按日上传最新的基金申赎数据(最后一次上传数据的日期为 2025/7/25,对应交易日期为 2025/7/24),参赛者需要定时关注,尽量使用最完整的数据进行建模,测试集和评测集可自行按照时间滑动构造。
| 序号 | 字段 | 描述 | 数据类型 |
|---|---|---|---|
| 1 | fund_code | 基金code | string |
| 2 | transaction_date | 交易日期 | string |
| 3 | apply_amt | 申购金额 | double |
| 4 | redeem_amt | 赎回金额 | double |
| 5 | uv_key_page_1 | 申赎核心页面 1 曝光uv | double |
| 6 | uv_key_page_2 | 申赎核心页面 2 曝光uv | double |
| 7 | uv_key_page_3 | 申赎核心页面 3 曝光uv | double |
赛题评分方法
评价指标:WMAPE(Weighted Mean Absolute Percentage Error,加权平均绝对百分比误差)。

优胜方案
🏆一等奖:fundlove


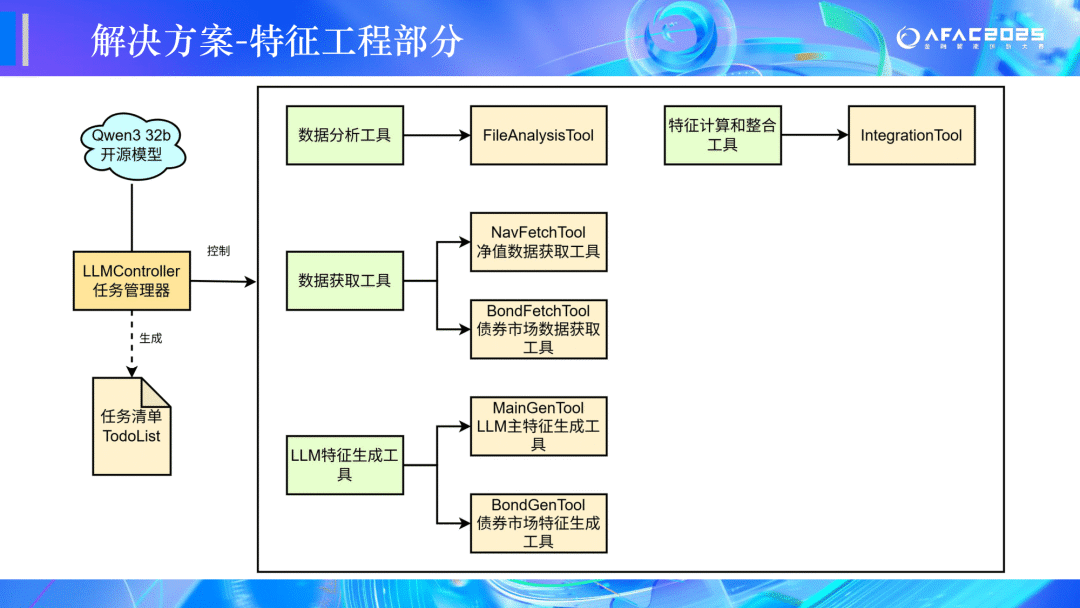


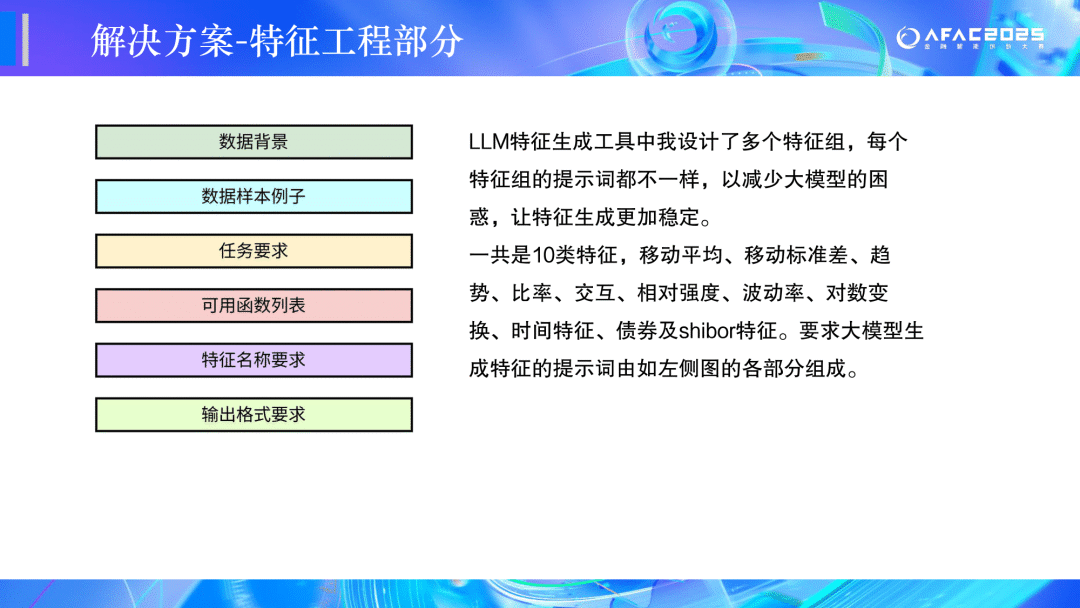
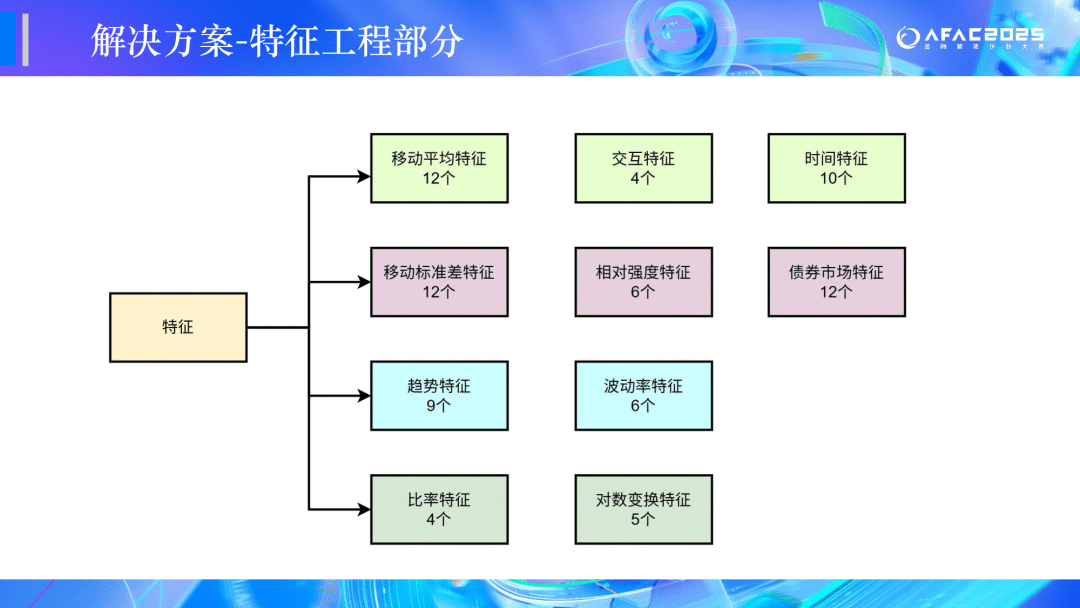
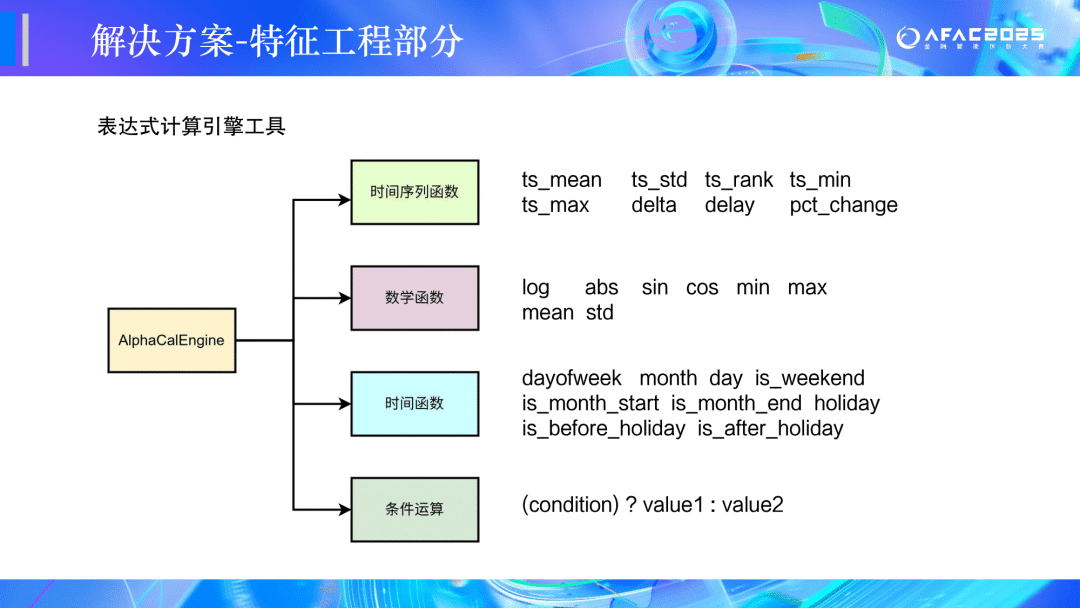
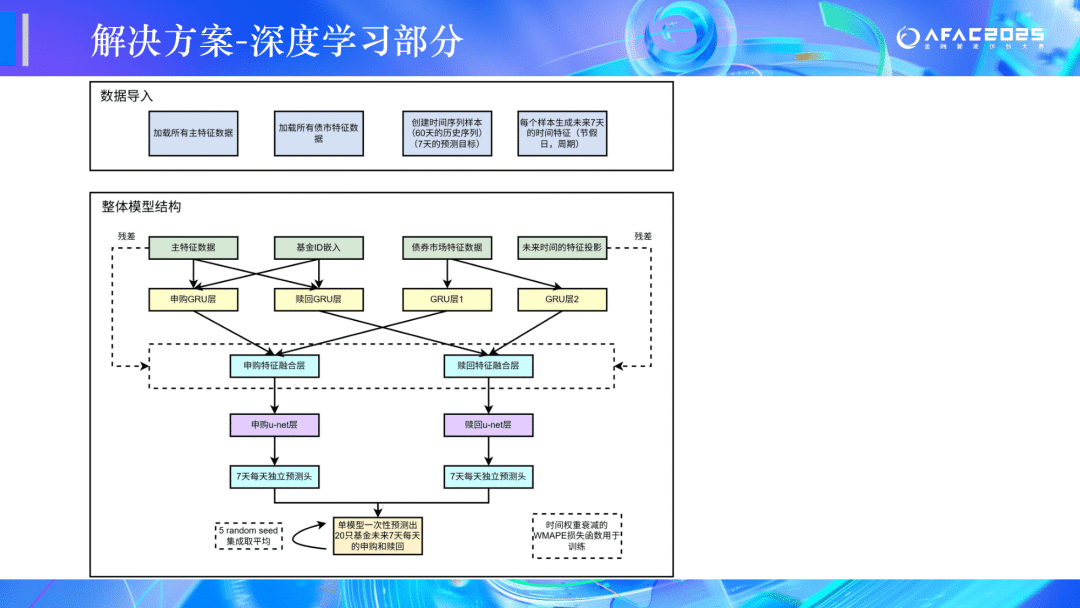
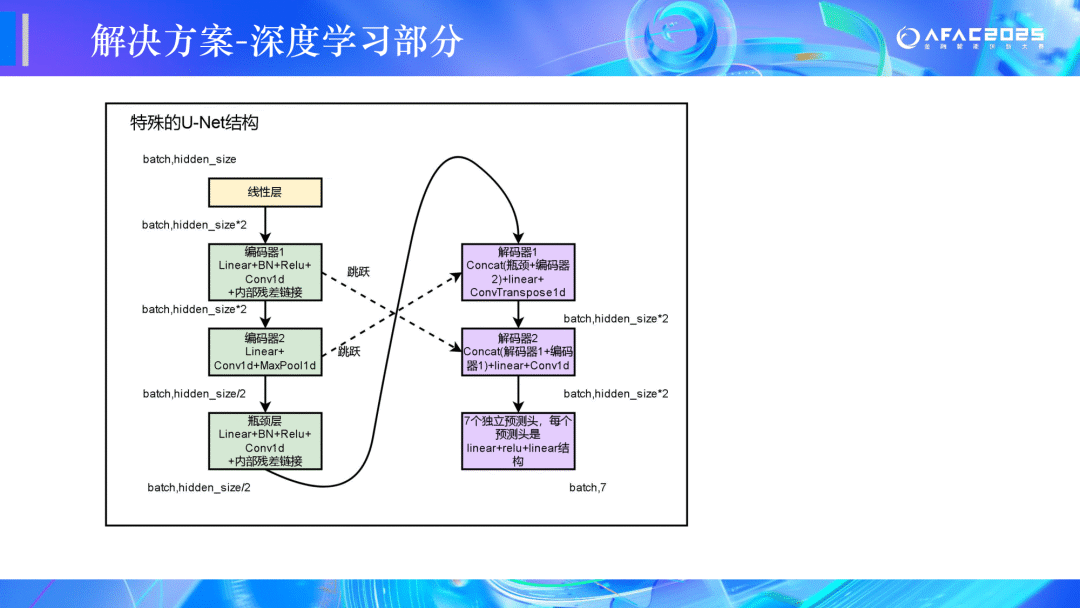
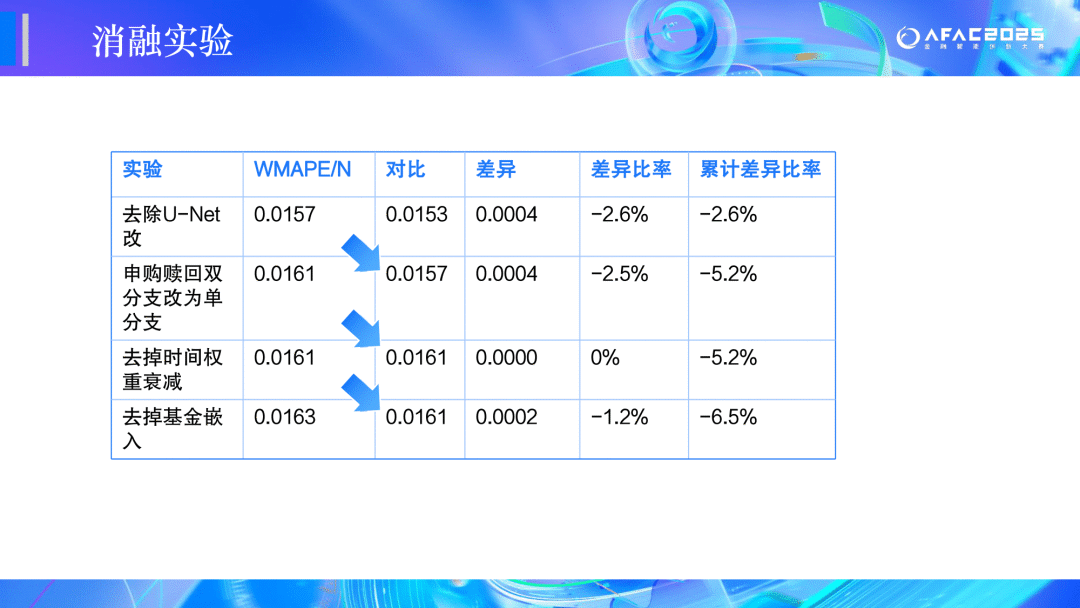
🏆二等奖:CEDC冲冲冲
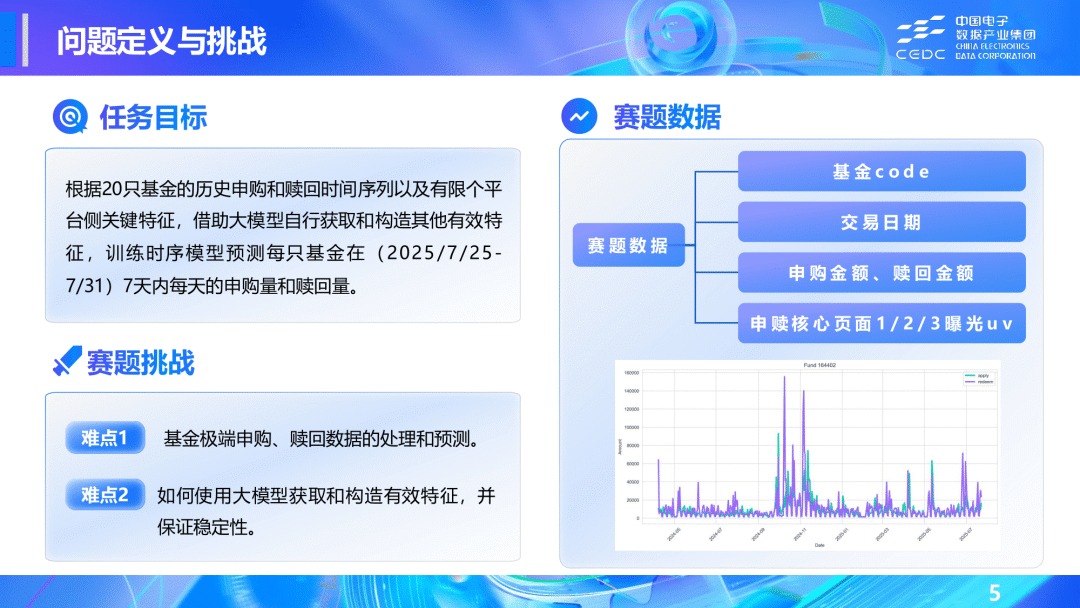
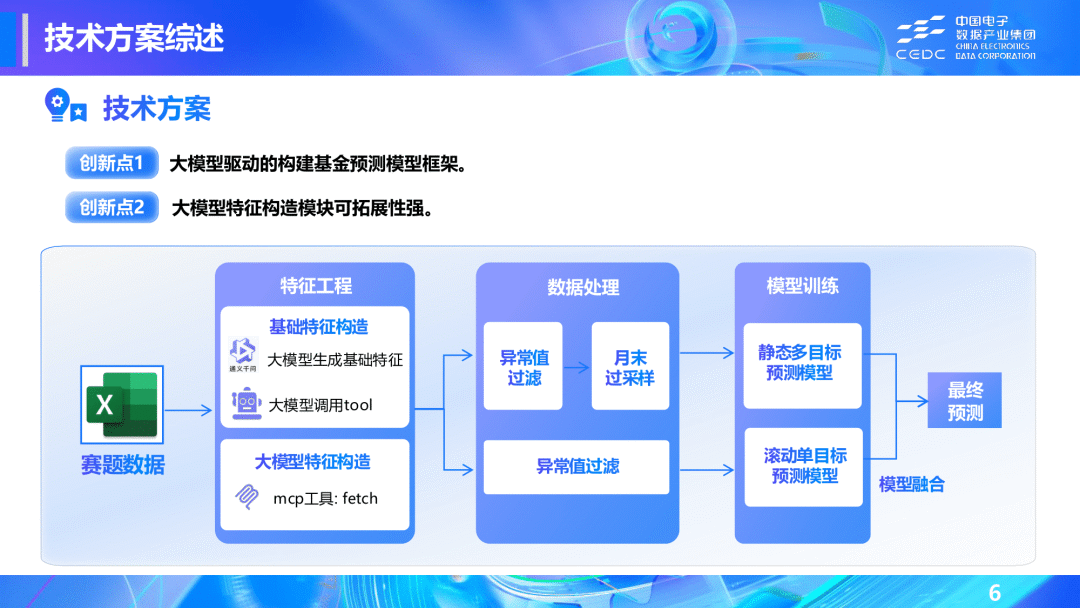

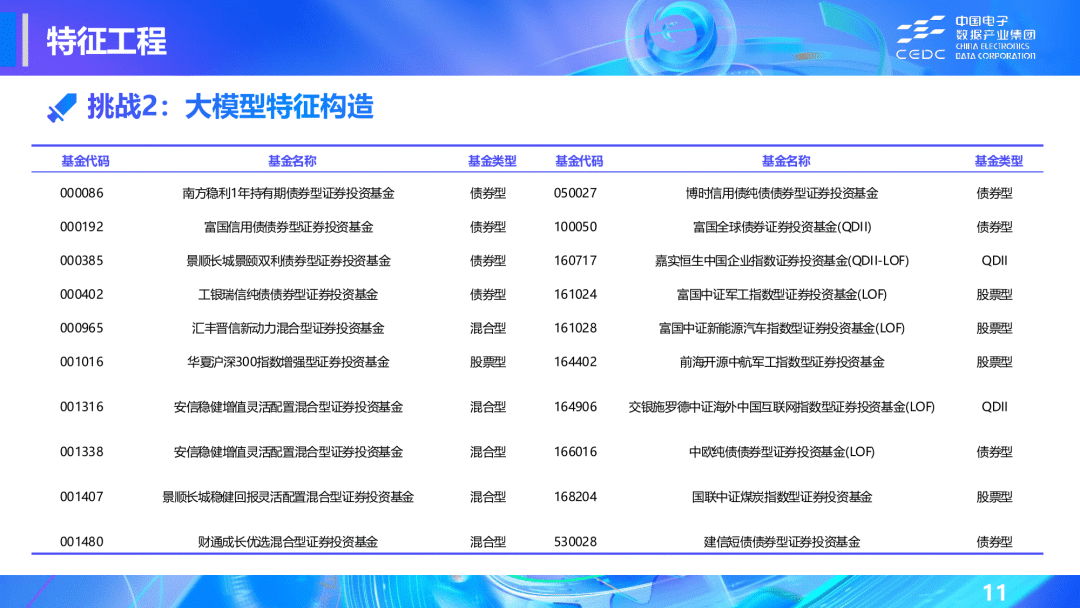
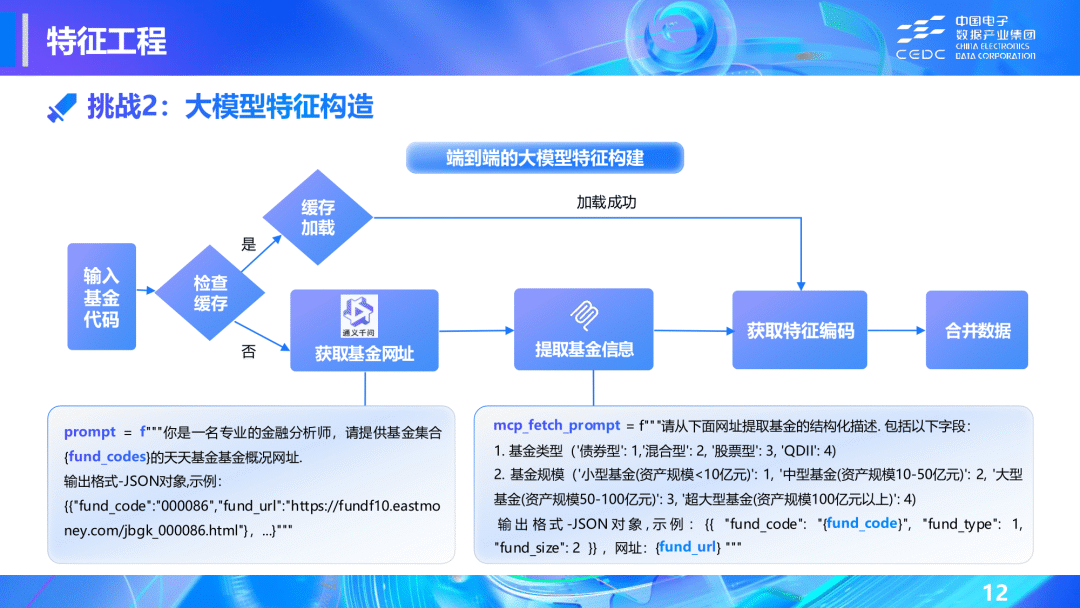

🏆 二等奖:allin
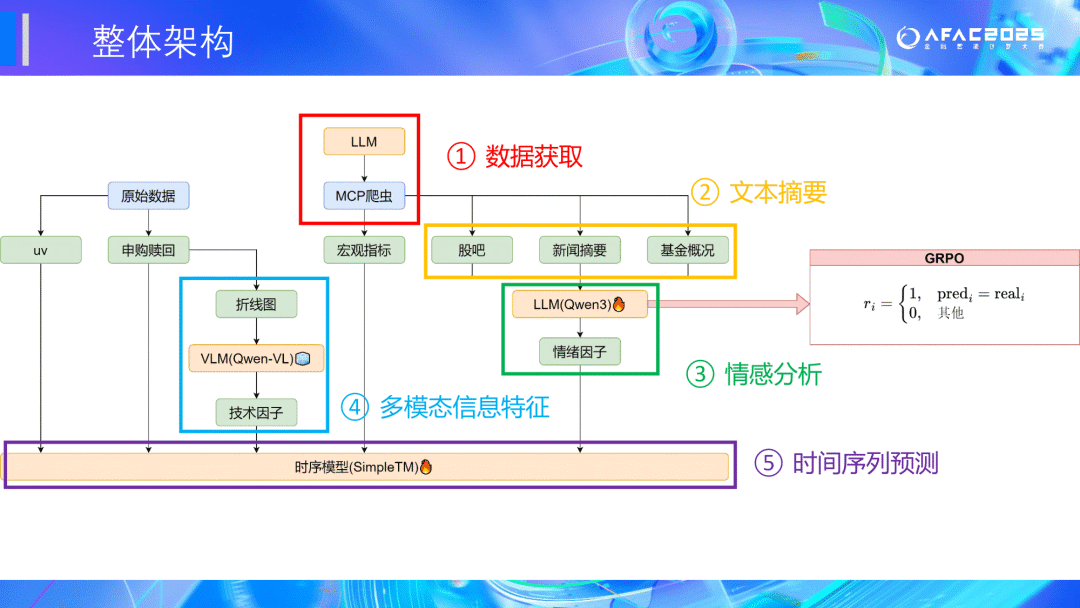
🏆三等奖:晨曦组
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









