






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/1jZN7FkOyyB4-7pRslKuaw
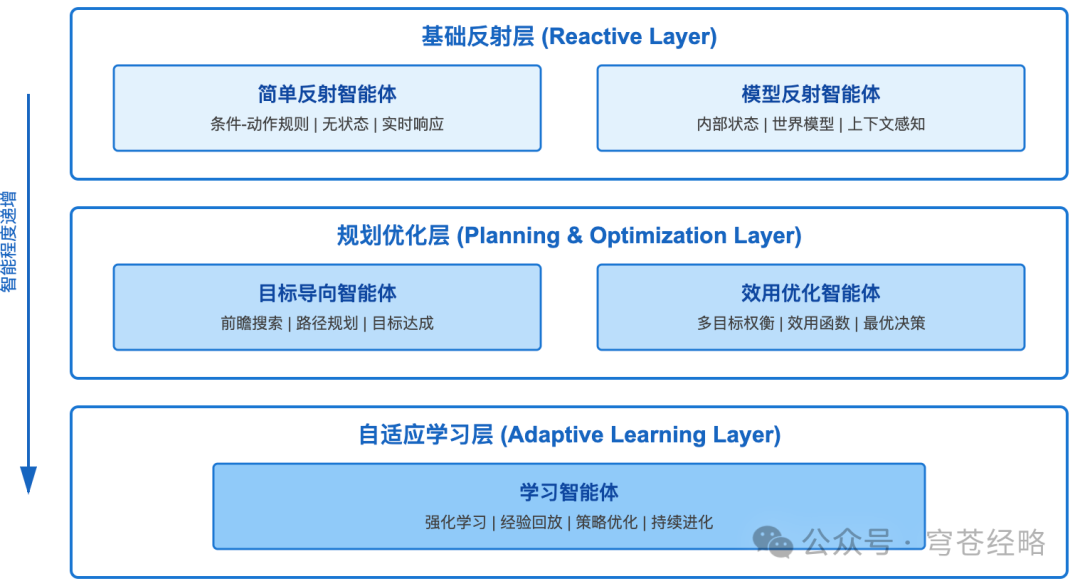
今天,来简单梳理一下Russell和Norvig在《人工智能:一种现代方法》中提出的智能体分类体系。
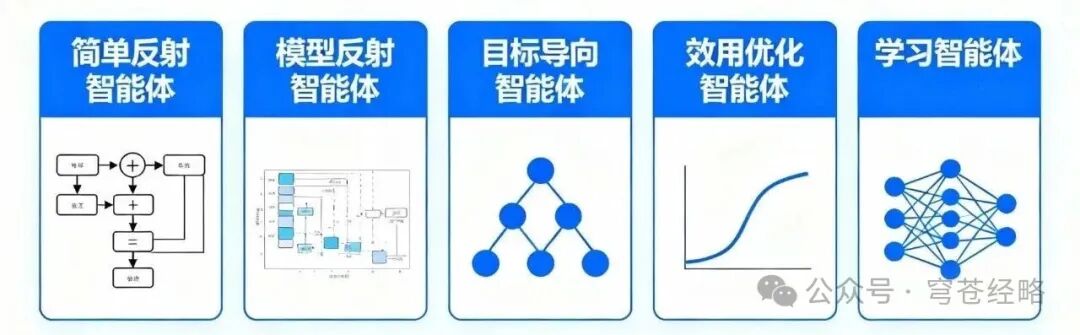
五种智能体类型构成了从基础到高级的完整技术谱系,如下图所示:
1、类型一:简单反射智能体(Simple Reflex Agent)
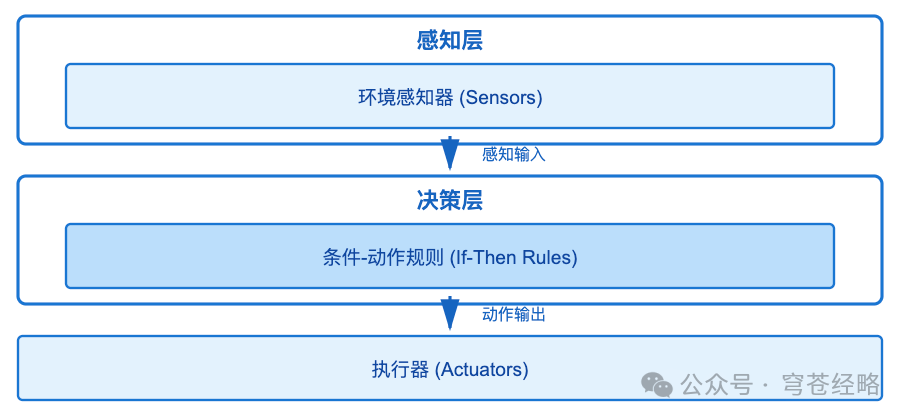
1)技术特征:
- 无状态设计
:不存储任何历史信息
- 即时响应
:决策延迟通常在毫秒级
- 规则驱动
:"If 温度<18°C Then 启动加热"
- 确定性行为
:相同输入必然产生相同输出
2)实际案例:
恒温器是最经典的简单反射智能体。它通过温度传感器感知环境,当读数低于设定值时触发加热器,达到目标温度后关闭。这种设计在结构化、可预测的环境中非常高效,但面对动态场景时表现不佳——比如无法预测即将到来的冷空气,也不会记住上次加热的效果。
3)局限性分析:
由于缺乏记忆和适应能力,简单反射智能体会重复犯错。例如,如果预设规则不完善(比如没有考虑湿度因素),系统将持续做出次优决策,永远无法自我修正。
2、类型二:模型反射智能体(Model-Based Reflex Agent)
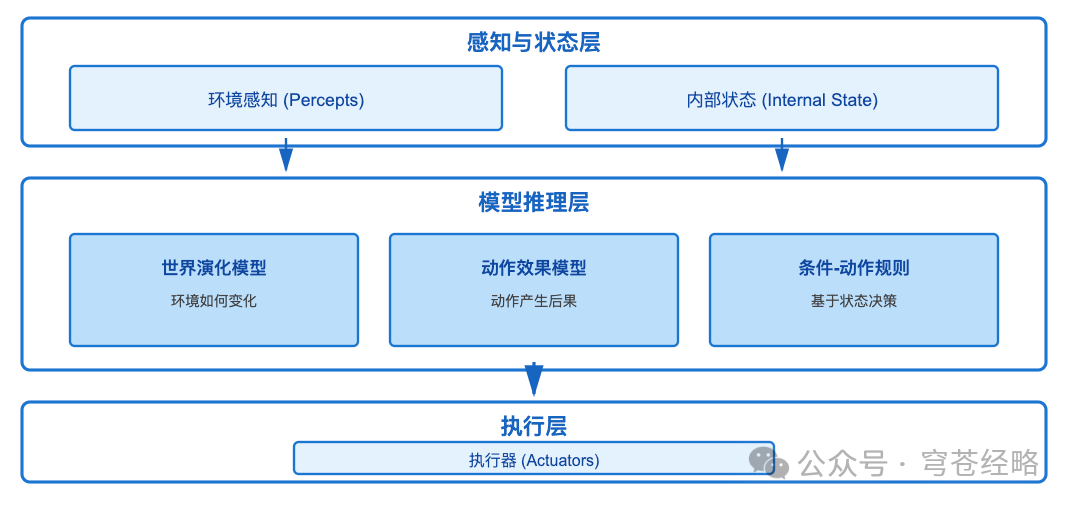
1)技术特征:
- 内部状态维护
:存储"我在哪里"、"我做过什么"
- 世界模型
:理解"环境如何变化"
- 动作模型
:预测"我的动作会产生什么后果"
2)技术实现:
以扫地机器人为例,其内部状态包含:
-
已清洁区域地图
-
障碍物位置记录
-
当前电量和位置
决策逻辑变为:"如果我认为当前区域脏且未清洁过,则启动吸尘;如果前方有障碍物,则绕行"。
关键是"我认为"——智能体通过内部模型推理无法直接观测的环境状态。比如转过墙角后,它仍然"记得"墙后的布局,这就是模型推理能力。
3)对比优势:
| 维度 | 类型一简单反射 | 类型二模型反射 |
|---|---|---|
| 记忆能力 | 无 | 有(内部状态) |
| 推理能力 | 无 | 有(模型预测) |
| 适应性 | 低 | 中 |
| 计算开销 | 极低 | 低-中 |
| 应用场景 | 恒温器、简单传感器 | 扫地机器人、导航系统 |
3、类型三:目标导向智能体(Goal-Based Agent)
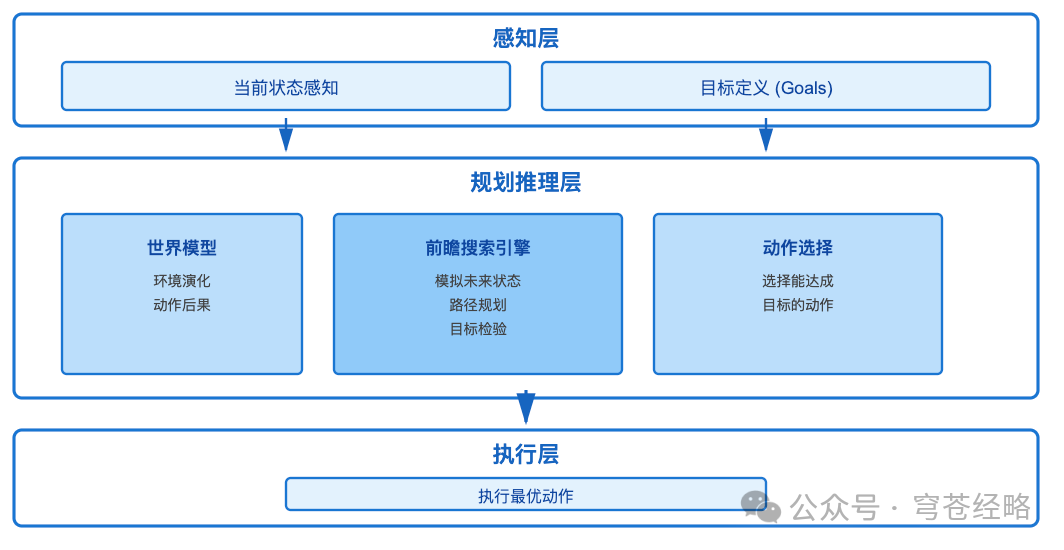
1)核心机制:
- 目标定义
:"到达地点X"、"完成任务Y"
- 前瞻搜索
:模拟多步动作序列
- 目标检验
:评估未来状态是否满足目标
2)自动驾驶案例:
目标:"安全到达目的地X"
决策过程:
-
当前状态:主街道,车速60km/h
-
候选动作:左转、直行、右转
-
未来预测:
- 左转 → 进入高速 → 30分钟后到达X ✓ - 直行 → 继续主街 → 45分钟后到达X ✓ - 右转 → 偏离路线 → 无法到达X ✗
-
选择:左转(时间最短且满足目标)
3)与模型反射的本质区别:
-
模型反射:"当前情况下做什么"(reactive)
-
目标导向:"为了达成目标应该做什么"(proactive)
目标导向智能体具备规划能力,能够牺牲短期利益换取长期目标。
4、类型四:效用导向智能体(Utility-Based Agent)
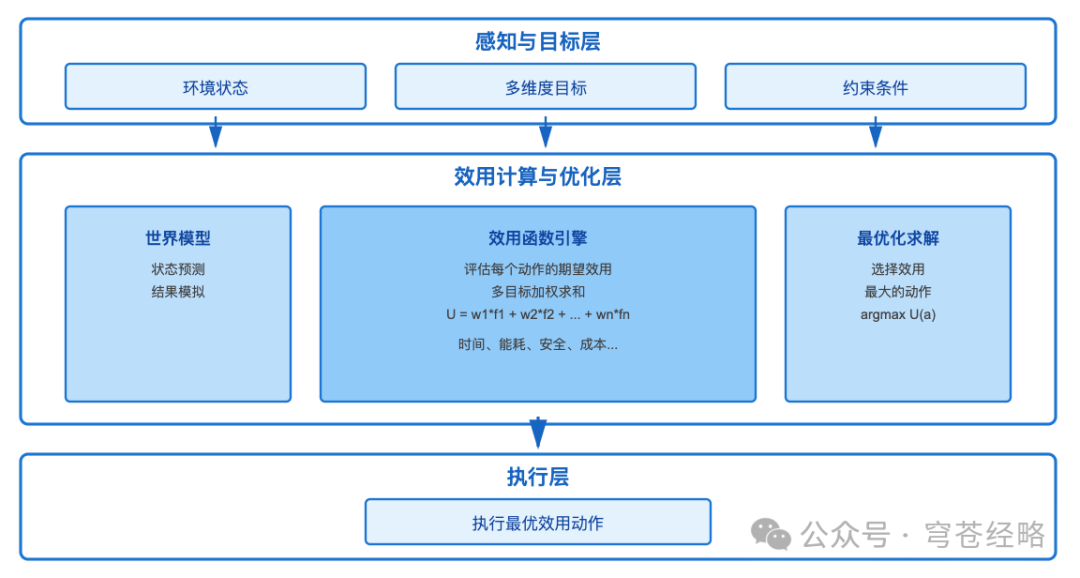
1)优化维度扩展:
不仅问"能否达成目标",更问"哪种方式最优"
2)实战应用:
无人机配送系统需要在多个维度上优化:
- 速度
:客户满意度要求
- 能耗
:电池续航限制
- 安全
:避开人群密集区
- 天气
:规避强风区域
目标导向智能体只会选择"能送达的路径",而效用导向智能体会选择"综合评分最高的路径"——可能稍慢但更安全、更省电。
3)决策对比:
| 智能体类型 | 送货路径选择逻辑 |
|---|---|
| 类型三 目标导向 | 任何能送达的路径都可以 |
| 类型四 效用导向 | 选择时间、能耗、安全综合最优的路径 |
4)技术挑战:
-
效用函数设计需要领域专家知识
-
多目标权重调整需要大量实验
-
计算复杂度随状态空间指数增长
5、类型五:学习智能体(Learning Agent)
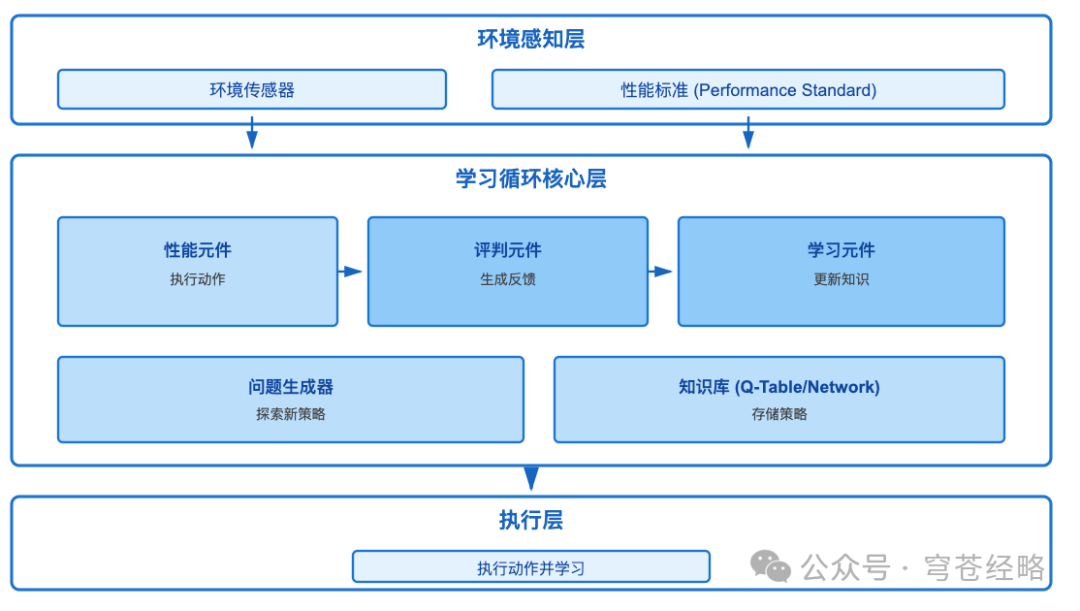
1)四大核心组件:
(1)性能元件(Performance Element)
-
功能:基于当前知识选择动作
-
类比:棋手根据已学策略下棋
(2)评判元件(Critic)
-
功能:观察动作结果,对比性能标准,生成反馈信号
-
输出:奖励值(+10表示好,-5表示差)
-
类比:教练评价棋手表现
(3)学习元件(Learning Element)
-
功能:根据反馈更新知识库
-
方法:强化学习、深度学习、进化算法
-
类比:棋手总结经验,改进策略
(4)问题生成器(Problem Generator)
-
功能:建议探索未尝试的动作
-
策略:ε-greedy探索、上置信界算法
-
类比:教练建议尝试新开局
2)AlphaGo案例深度剖析:
性能元件:当前局面下的落子决策网络
评判元件:对局结果(赢+1,输-1)
学习元件:通过数百万局自我对弈,持续优化策略网络参数
问题生成器:在训练中引入随机性,探索非常规下法
关键突破:从零知识到超越人类,完全通过自我博弈学习。
3)学习范式对比:
| 学习类型 | 数据来源 | 典型算法 | 应用场景 |
|---|---|---|---|
| 监督学习 | 标注样本 | 神经网络、决策树 | 图像分类、语音识别 |
| 强化学习 | 环境反馈 | Q-Learning、PPO | 游戏AI、机器人控制 |
| 无监督学习 | 无标注数据 | K-Means、自编码器 | 异常检测、数据聚类 |
4)局限性:
- 数据密集
:需要海量交互数据
- 训练耗时
:AlphaGo训练数月
- 泛化挑战
:在训练环境外可能失效
- 安全隐患
:探索过程可能产生危险行为
6、五大智能体类型选型决策树
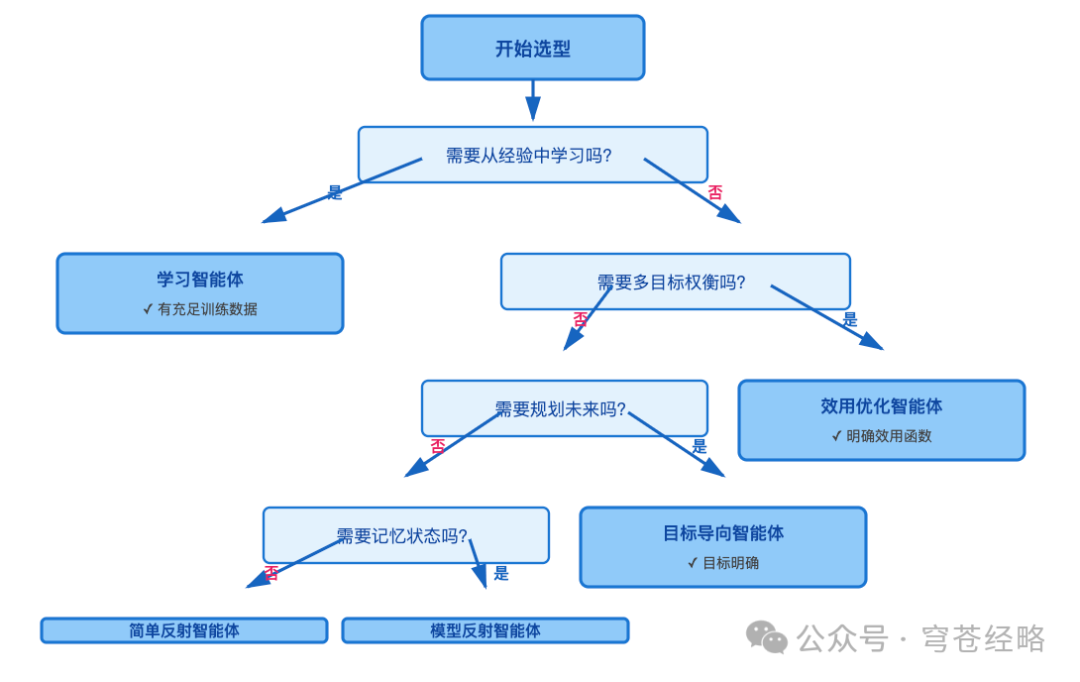
-
性能对比矩阵
| 维度 | 1简单反射 | 2模型反射 | 3目标导向 | 4效用优化 | 5学习智能体 |
|---|---|---|---|---|---|
| 响应延迟 | <1ms | <10ms | 10-100ms | 100ms-1s | 变化大 |
| 内存占用 | 极小(<1MB) | 小(1-10MB) | 中(10-100MB) | 大(100MB-1GB) | 极大(>1GB) |
| 适应性 | 无 | 低 | 中 | 中 | 高 |
| 可解释性 | 高 | 高 | 中 | 低 | 极低 |
| 开发成本 | 低 | 中 | 中高 | 高 | 极高 |
| 维护成本 | 低 | 中 | 中 | 中高 | 高 |
AI智能体从简单到复杂的五大类型,每种类型都有其适用场景和技术特点。技术选型时,需要平衡性能需求、成本预算和开发周期。渐进式演进比激进跃迁更稳妥,从解决80%标准场景的简单智能体开始,逐步升级到处理边缘情况的学习系统。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









