




 本文由多位数据竞赛专家分享数据探索的重要性与方法,包括赛前数据分析、模型分析,涉及异常值处理、变量分布、相关性分析等方面。通过数据探索,可以了解数据特性,发现隐藏价值,为模型建立和优化提供关键信息。
本文由多位数据竞赛专家分享数据探索的重要性与方法,包括赛前数据分析、模型分析,涉及异常值处理、变量分布、相关性分析等方面。通过数据探索,可以了解数据特性,发现隐藏价值,为模型建立和优化提供关键信息。

为了帮助更多竞赛选手入门进阶比赛,通过数据竞赛提升理论实践能力和团队协作能力。DataFountain 和 Datawhale 联合邀请了数据挖掘,CV,NLP领域多位竞赛大咖,将从赛题理解、数据探索、数据预处理、特征工程、模型建立与参数调优、模型融合六个方面完整解析数据竞赛知识体系,帮助竞赛选手从0到1入门和进阶竞赛。
下面是大咖分享
???
数据挖掘方向
杰少 ID:尘沙杰少
简介:南京大学计算机系毕业,现任趋势科技资深算法工程师。20多次获得国内外数据竞赛奖项,包括KDD2019以及NIPS18 AutoML等。
1. 数据探索的意义?
数据探索作为大数据竞赛最为核心的模块之一,贯穿整个比赛的始终。
数据探索可以主要划分为两块,一块是赛前对于数据的探索,一块是对于模型的预测结果的分析,而这两大块又可以继续细化为很多细节。
赛前数据的探索可以帮助我们更好地了解数据的性质以及干净程度,包括数据的大小,数据的缺失值的分布,训练集与测试集的分布差异等,这些可以为我们的数据预处理带来非常大的参考;同时,数据集中的奇异现象又会进一步促进我们对其进行研究与观察,更好地了解业务,并构建相应强特征;而对模型的分析部分,则可以帮助我们了解模型哪些数据做的好,哪些数据做的不好,通过此类反馈,我们就可以对错误的数据展开研究,挖掘我们所遗漏的部分,进一步提升我们模型的预测性能。
2. 数据探索需要做什么?
此处我把数据探索模块展开成两块,赛前数据分析以及模型的分析。
(1)赛前数据分析
全局分析:包括数据的大小,整体数据的缺失情况等;通过全局的分析,我们可以知道我们数据的整体情况,决定我们采用什么样的机器等等;
单变量分析:包括每个变量的分布,缺失情况等;通过单变量分析,我们可以进一步的了解每个变量的分布情况,是否有无用的变量(例如全部缺失的列),是否出现了某些分布奇怪的变量等.
多变量分析:包括特征变量与特征变量之间的分析以及特征变量与标签之间的分析等;通过多变量分析,很多时候我们可以直接找到一些比较强的特征,此外变量之间的关系也可以帮助我们做一些简单的特征筛选。
训练集与测试集的分布分析:寻找差异大的变量,这些差异大的变量往往是导致线下和线上差异的核心因素,这有利于我们更好的设计线下的验证方法。
(2)模型的分析
模型特征重要性分析:LGB/XGB等的importance、LR、SVM的coeff等;特征重要性可以结合业务理解,有些奇怪的特征在模型中起着关键的作用,这些可以帮助我们更好地理解我们的业务,同时如果有些特征反常规,我们也可以看出来;可能这些就是过拟合的特征等等;
模型分割方式分析:可视化模型的预测,包括LGB的每一颗数等;这些可以帮助我们很好的理解我们的模型,模型的分割方式是否符合常理也可以结合业务知识一起分析,帮助我们更好的设计模型;
模型结果分析:这个在回归问题就是看预测的结果的分布;分类一般看混淆矩阵等。这么做可以帮助我们找到模型做的不好的地方,从而更好的修正我们的模型。
因为每个比赛的分析的重点都不太一样,上面提到的是几乎适用于80%比赛的框架,今后有机会会结合相应的比赛一并分享。谢谢大家的阅读。
作者公众号:kaggle竞赛宝典

王贺 ID:鱼遇雨欲语与余
简介:武汉大学硕士,2019年腾讯广告算法大赛冠军选手,京东算法工程师,一年内获得两冠四亚一季的佳绩。
数据探索
数据探索也被称为EDA,我们首先要知道在EDA的过程中,在拿到一份新的数据集时,需要理解数据集,熟悉数据集的规模,查看数据的统计分布,了解特征之间的相关性等。具体需要解决哪些问题:
1. 确定问题,确定输入输出原始特征以及数据的类型
2. 发现缺失值、异常值
3. 连续型变量和类别型变量分布
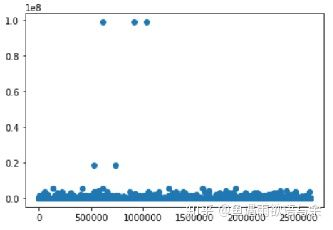
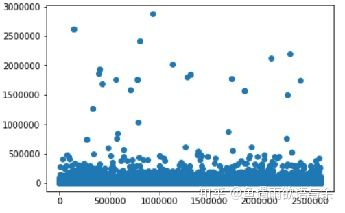
异常值观察处理
常见的是通过可视化的方式进行异常值的观察,就是用箱形图和散点图来观察。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3549
3549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









