






本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/j2ZMLT3JoB2VWAOsBfHmgg

论文链接:https://arxiv.org/pdf/2509.16117
Git链接:https://research.nvidia.com/labs/dir/DiffusionNFT/
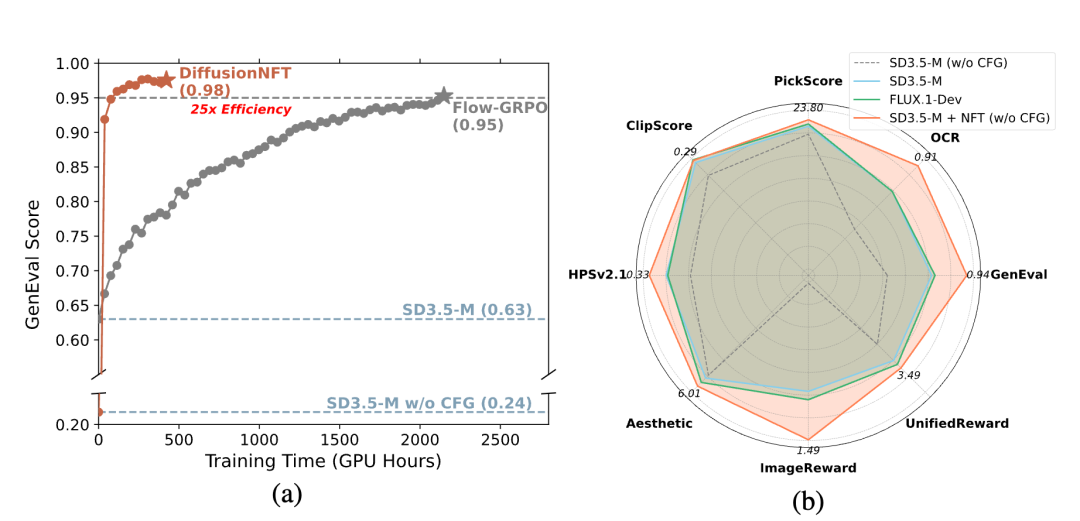
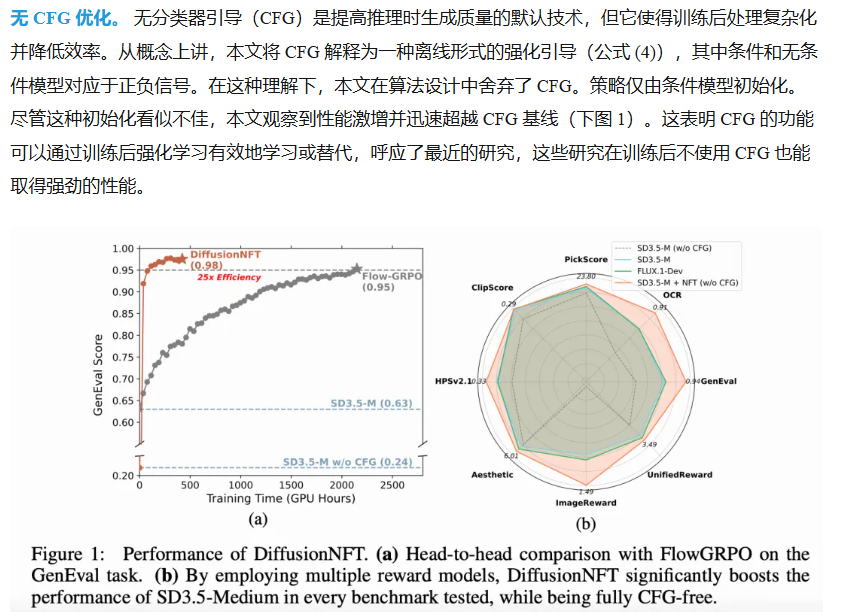
DiffusionNFT 的性能。(a)在 GenEval 任务上与 FlowGRPO 的头对头比较。(b)通过采用多种奖励模型,DiffusionNFT显著提高了SD3.5-Medium 在每个测试基准测试中的性能,同时完全无需 CFG
亮点直击
一种新的在线强化学习(RL)范式:扩散负面感知微调(DiffusionNFT)。DiffusionNFT 并不基于策略梯度框架,而是通过流匹配目标直接在前向扩散过程中进行策略优化。
通过在多个奖励模型上对 SD3.5-Medium进行后训练来评估 DiffusionNFT。整个训练过程刻意在无 CFG 的环境中进行。尽管这导致初始性能显著降低,但 DiffusionNFT 在域内和域外奖励上显著提高了性能,迅速超越 CFG 和 GRPO 基线。
在单一奖励设置中与 FlowGRPO 对比。四个任务中,DiffusionNFT 一直表现出 3 倍到 25 倍的效率,并取得更好的最终得分。
总结速览
解决的问题
-
在线强化学习(RL)在扩散模型中的应用面临挑战,主要由于难以处理的似然性。
-
现有方法如离散化反向采样过程存在求解器限制、前向-反向不一致性,以及与无分类器引导(CFG)的复杂整合。
提出的方案
-
引入扩散负面感知微调(DiffusionNFT),一种新的在线RL范式,通过流匹配直接在前向过程中优化扩散模型。
-
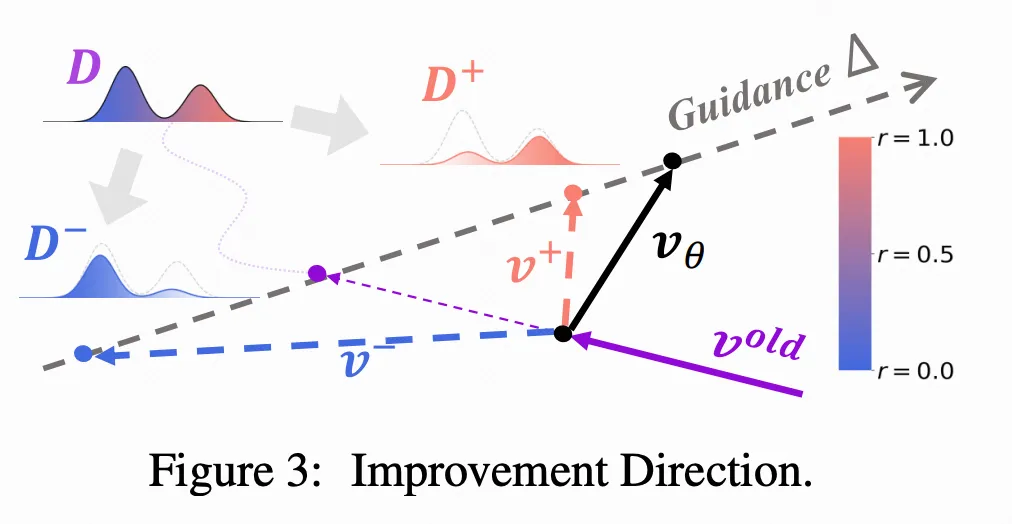
DiffusionNFT 通过对比正负生成来定义隐式的策略改进方向,将强化信号自然融入监督学习目标中。
应用的技术
-
使用流匹配目标进行策略优化,而非传统的策略梯度框架。
-
允许使用任意黑箱求解器进行训练,消除对似然性估计的需求。
-
采用隐式参数化技术,整合强化引导到优化策略中。
-
仅需干净的图像用于策略优化,而不需存储整个采样轨迹。
达到的效果
-
DiffusionNFT 的效率比 FlowGRPO 高达 25 倍,并且无需使用 CFG。
-
在多个基准测试中显著提升了 SD3.5-Medium 的性能。
-
例如,在 1000 步内将 GenEval 得分从 0.24 提高到 0.98,而 FlowGRPO 在超过 5000 步和额外的 CFG 使用下仅达到 0.95。
-
证明了在无 CFG 环境中,DiffusionNFT 在域内和域外奖励上显著提高了性能。
扩散强化通过负面感知微调
问题设置

带有前向过程的负面感知扩散强化

定理 3.2(策略优化)。考虑训练目标:

1. 前向一致性。 与在反向扩散过程中构建 RL 的策略梯度方法(例如,FlowGRPO)不同,DiffusionNFT 在前向过程中定义了一个典型的扩散损失。这保留了本文称之为前向一致性的特性,即扩散模型底层概率密度对 Fokker-Planck 方程的遵从性,确保所学习的模型对应于一个有效的前向过程,而不是退化为级联高斯分布。
2. 求解器灵活性。 DiffusionNFT 完全解耦了策略训练和数据采样。这使得在整个采样过程中可以充分利用任何黑箱求解器,而不是依赖于一阶随机微分方程(SDE)采样器。它还消除了在数据收集过程中存储整个采样轨迹的需要,只需要用于训练的干净图像及其相关的奖励。
3. 隐式指导整合。 直观地说,DiffusionNFT 定义了一个指导方向 并将其应用于旧的策略 (方程 (6))。然而,它并不是学习一个独立的指导模型 并采用指导采样,而是采用一种隐式参数化技术,使得强化指导可以直接整合到学习的策略中。这种技术受到最近无指导训练进展的启发,允许本文在单一策略模型上持续进行 RL,这对于在线强化至关重要。
4. 无需似然性公式。 以前的扩散 RL 方法在本质上受到其对似然性近似的限制。无论是通过变分界限近似边际数据似然并应用 Jensen 不等式以降低损失计算成本,还是离散化反向过程以估计序列似然,它们不可避免地在扩散后训练中引入系统性估计偏差。相比之下,DiffusionNFT 本质上是无需似然性的,避开了这些妥协。
实现
本文在算法 1 中提供了 DiffusionNFT 的伪代码。

下面,本文详细说明关键的设计选择。

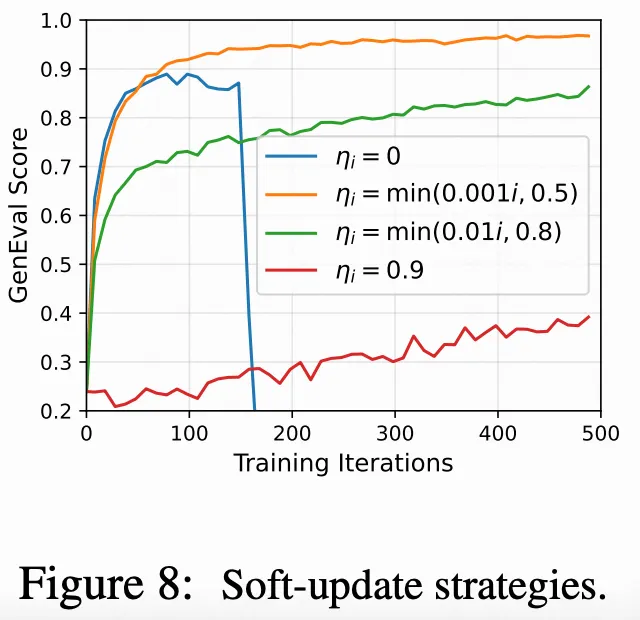
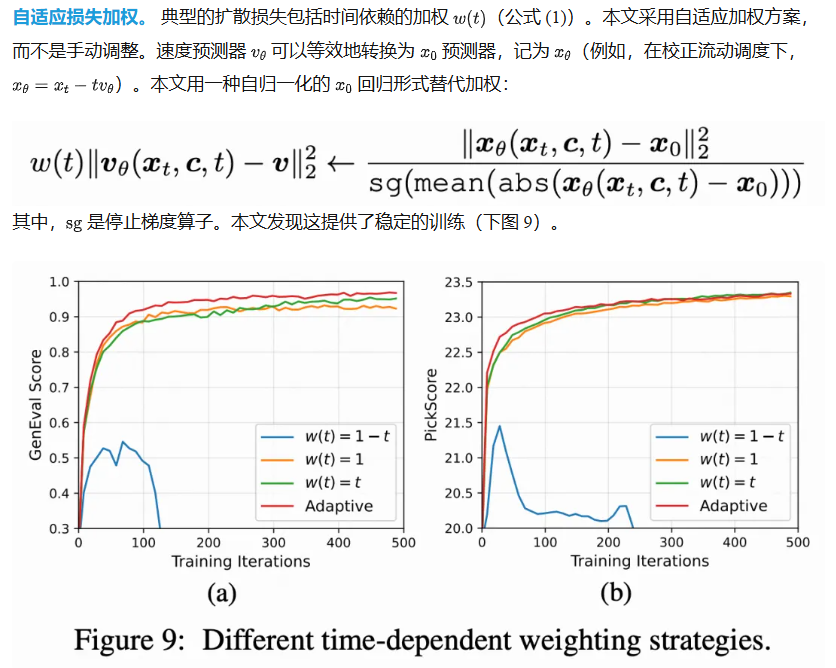
验
本文从三个角度展示 DiffusionNFT 的潜力:(1)多奖励联合训练以实现强大的无 CFG 性能,(2)与 FlowGRPO 在单一奖励上的正面对比,以及(3)关键设计选择的消融研究。
实验设置
本文的实验基于 SD3.5-Medium,分辨率为 512×512,大多数设置与 FlowGRPO 一致。
奖励模型。 (1)基于规则的奖励,包括用于组合图像生成的 GenEval 和用于视觉文本渲染的 OCR,其中部分奖励分配策略遵循 FlowGRPO。(2)基于模型的奖励,包括 PickScore 、ClipScore、HPSv2.1 、Aesthetics、ImageReward 和 UnifiedReward,用于衡量图像质量、图像-文本对齐和人类偏好。
提示数据集。 对于 GenEval 和 OCR,本文使用 FlowGRPO 的相应训练和测试集。对于其他奖励,本文在 Pick-a-Pic 上训练,并在 DrawBench 上评估。
训练和评估。 本文使用 LoRA 进行微调(a=64,r=32)。每个 epoch 包含 48 组,组大小为 G=24。本文使用 10 步采样进行正面对比和消融研究,而在多奖励训练中使用 40 步以获得最佳视觉质量。评估使用 40 步一阶 ODE 采样器进行。
多奖励联合训练
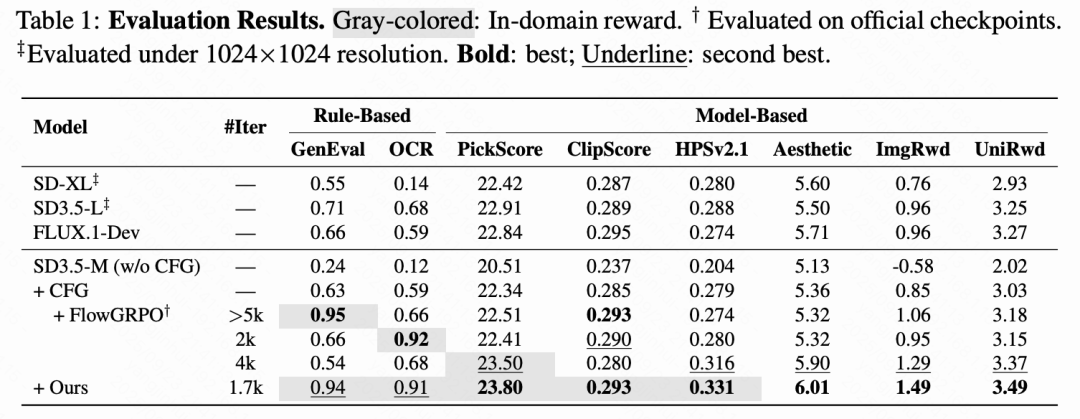
本文首先评估 DiffusionNFT 在全面增强基础模型方面的有效性。从无 CFG 的 SD3.5-M(25 亿参数)开始,本文联合优化五个奖励:GenEval、OCR、PickScore、ClipScore 和 HPSv2.1。由于奖励基于不同的提示,本文首先在 Pick-a-Pic 上使用基于模型的奖励进行训练,以增强对齐和人类偏好,然后是基于规则的奖励(GenEval,OCR)。在域外评估中,本文使用 Aesthetics、ImageReward 和 UnifiedReward。
如下表 1 所示,本文最终的无 CFG 模型不仅在域内和域外指标上超越了 CFG,并且匹配仅适用于单一奖励的 FlowGRPO,还优于基于 CFG 的更大模型,如 SD3.5-L(80 亿参数)和 FLUX.1-Dev(120 亿参数)。下图 5 中的定性比较展示了本文方法的卓越视觉质量。

正面对比
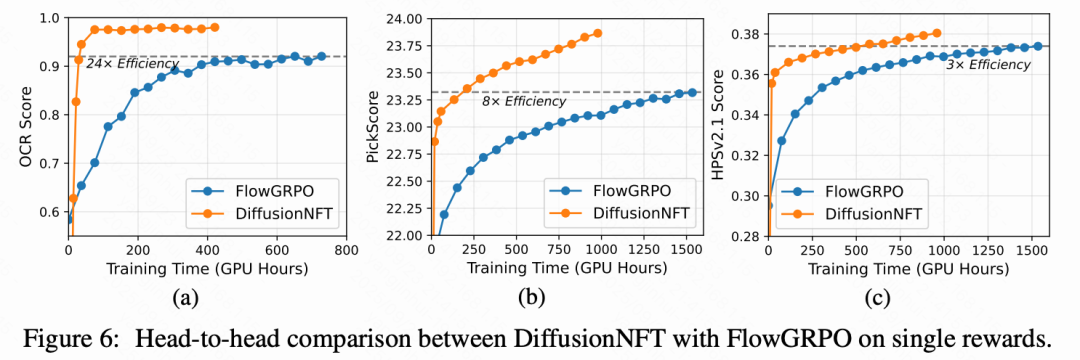
本文与 FlowGRPO 在单一训练奖励上进行正面对比。如上图 1(a) 和下图 6 所示,本文方法在挂钟时间方面效率提高了 3 到 25 倍,仅需约 1000 次迭代即可实现 GenEval 得分 0.98。这表明在本文的框架下,无 CFG 模型可以快速适应特定的奖励环境。
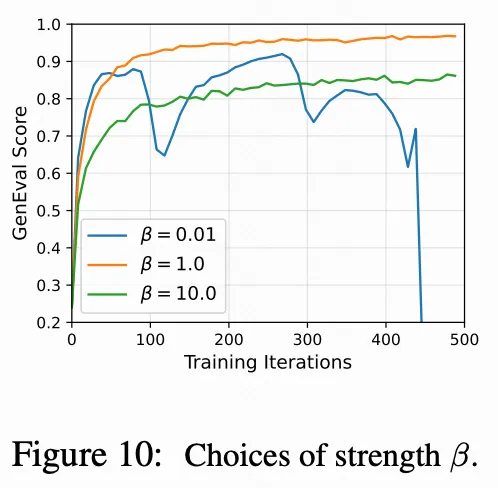
消融实验
本文分析了核心设计选择的影响:
负损失。 负面感知组件在 DiffusionNFT 中至关重要。没有对 的负策略损失,发现奖励几乎在在线训练中瞬间崩溃,这突显了负信号在扩散 RL 中的关键作用。这一现象与 LLMs 中的观察结果不同,在 LLMs 中,RFT 仍然是一个强有力的基线。
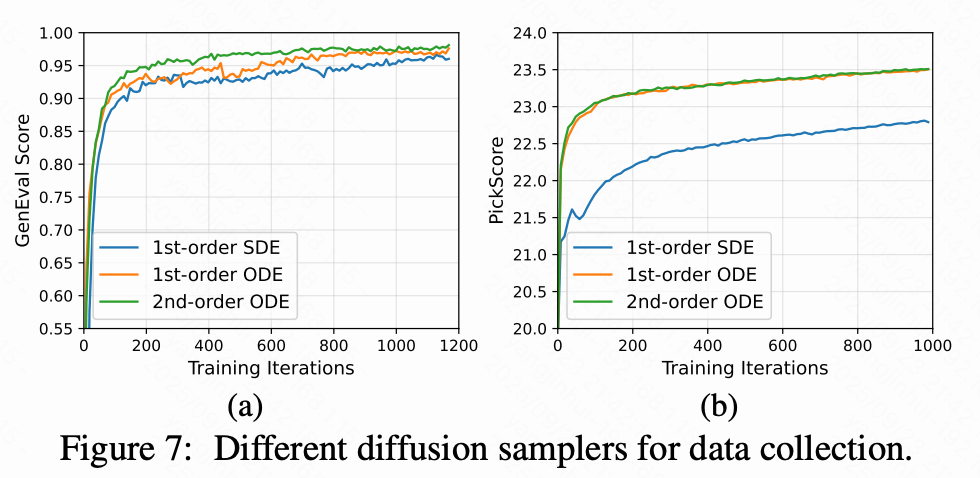
扩散采样器。 DiffusionNFT 中的在线样本既用于奖励评估,也用作训练数据,因此质量至关重要。下图 7 显示 ODE 采样器优于 SDE 采样器,尤其是在对噪声敏感的 PickScore 上。二阶 ODE 在 GenEval 上略优于一阶 ODE,而在 PickScore 上表现相当。

结论
Diffusion Negative-aware FineTuning(DiffusionNFT),这是一种用于扩散模型在线强化学习的新范式,直接作用于前向过程。通过将策略改进表述为正负生成之间的对比,DiffusionNFT 无缝地将强化信号整合到标准扩散目标中,消除了对似然估计和基于 SDE 的反向过程的依赖。实证上,DiffusionNFT 展示了强大且高效的奖励优化,效率比 FlowGRPO 高达 25 倍,同时生成单一的全能模型,在各种域内和域外奖励上超过 CFG 基线。相信这项工作代表了在扩散中统一监督学习和强化学习的一步,并突出了前向过程作为可扩展、高效且理论上有原则的扩散 RL 的有前途的基础。
参考文献
[1] DIFFUSIONNFT: ONLINE DIFFUSION REINFORCEMENT WITH FORWARD PROCESS
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









