






本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/EBT-BCvQiYe7ygOxnIPffA
极市导读
清华大学等机构的研究者们提出了 SLAM-Former:它将传统 SLAM 的前端实时跟踪与后端全局优化功能集成到一个 Transformer 模型中,通过前后端的协同机制实现了高效、准确的定位与建图。在多个主流 SLAM 数据集上,SLAM-Former 展现了卓越的轨迹精度和重建质量,同时保持了超过 10Hz 的实时运行速度,为端到端 SLAM 系统的发展开辟了新方向。
搞SLAM(即时定位与地图构建)的同学都知道,传统方法通常是个“流水线”作业,分成前端和后端两个模块。前端负责实时追踪相机位置、处理传感器数据,后端则负责优化轨迹、闭环检测,修正累积误差。这种分体式设计虽然经典,但也带来了模块间协作复杂、误差传递等问题。
今天,CV君要给大家聊一篇超酷的工作,来自清华大学等机构的研究者们提出了一个名为 SLAM-Former 的新东西,它的核心思想有点颠覆:把整个SLAM的功能,全都塞进一个Transformer里!
没错,你没听错,就是一个统一的模型,同时搞定前端的实时跟踪和后端的全局优化。听起来是不是很带感?我们一起来看看他们是怎么做到的。

-
论文标题:SLAM-Former: Putting SLAM into One Transformer
-
作者:Yijun Yuan, Zhuoguang Chen, Kenan Li, Weibang Wang, Hang Zhao
-
机构:清华大学
-
论文地址:https://arxiv.org/abs/2509.16909
-
项目地址:https://tsinghua-mars-lab.github.io/SLAM-Former/
传统SLAM的“分工”与SLAM-Former的“大一统”
在传统的视觉SLAM系统中,通常是这样的工作模式:
-
前端(Frontend):像个侦察兵,负责处理实时的图像流,快速估算相机每时每刻的相对运动,这个过程叫作视觉里程计(Visual Odometry)。它追求速度,但不可避免地会产生累积误差。
-
后端(Backend):像个指挥官,它会拿到前端的数据,进行全局分析。比如,当相机回到一个去过的地方时,后端需要识别出“哦,我来过这里”(闭环检测),然后通过全局优化(如Bundle Adjustment或姿态图优化)来修正整个轨迹和地图,消除前端的累积误差。
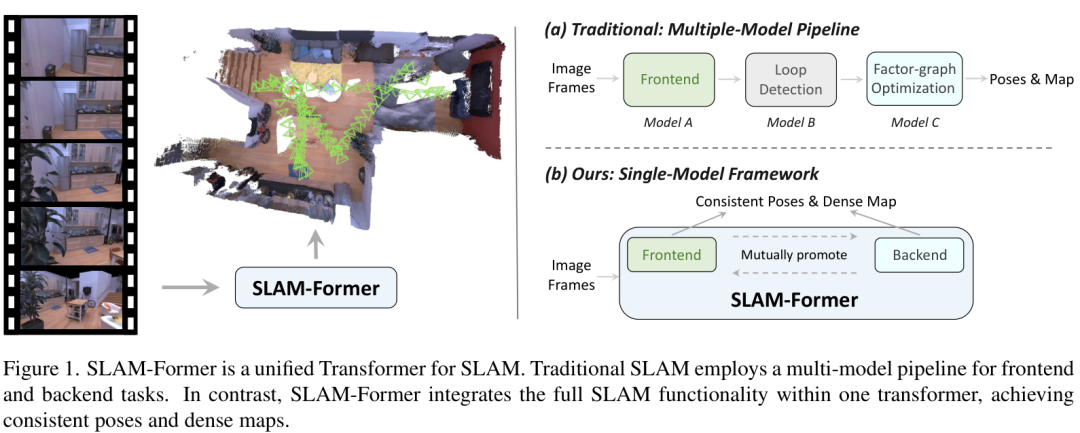
这种前后端分离的模式虽然有效,但就像两个部门协作,总需要数据交接和磨合。而SLAM-Former的目标就是打破这种隔阂,让整个系统成为一个有机的整体。
SLAM-Former:一个模型,两种角色
SLAM-Former巧妙地设计了一个统一的Transformer架构,让它能同时扮演前端和后端的角色,并且这两个角色还能“互相促进”。
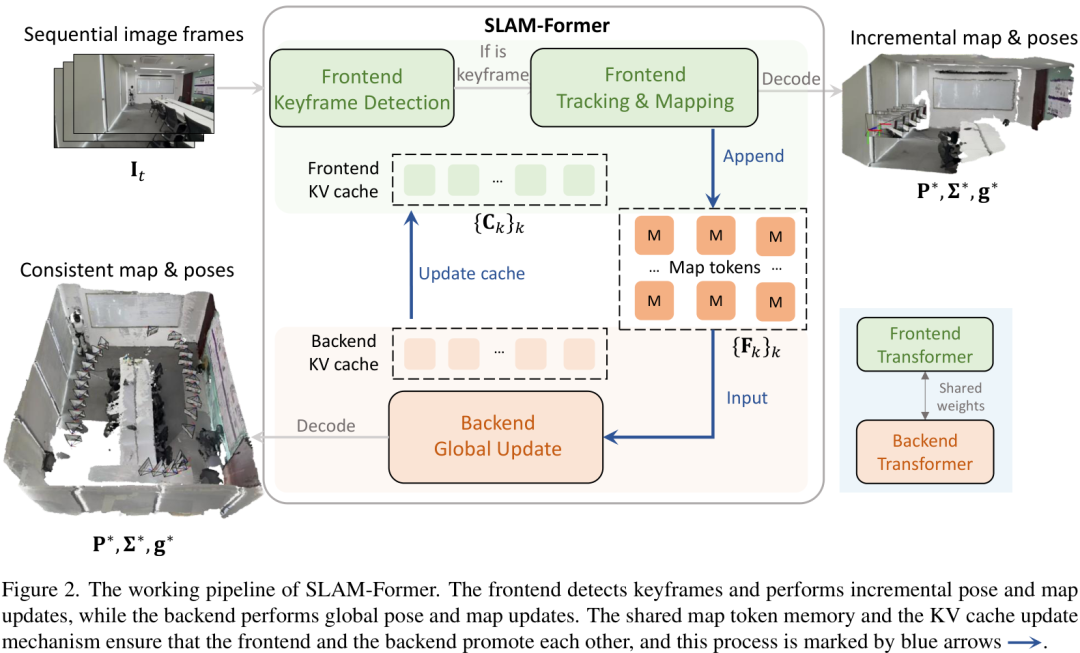
上图就是SLAM-Former的工作流程,我们可以看到:
-
输入:连续的图像帧(Sequential image frames)。
-
前端角色:当新的图像帧进来时,模型会进行关键帧检测,并执行增量式的跟踪和建图(Frontend Tracking & Mapping)。这个过程是实时的,保证了系统的效率。
-
后端角色:每隔一段时间(比如每T个关键帧),模型就会启动“全局更新”(Backend Global Update)。它会利用强大的全局注意力机制(Full Attention)来审视过去所有的关键帧和地图信息,进行一次彻底的优化,修正漂移,确保全局地图的一致性。
-
核心机制:互相促进:最妙的地方在于,前端和后端不是孤立的。后端优化后的结果(比如更准确的地图信息)会通过更新共享的KV缓存(KV cache)反馈给前端。这样,前端在处理新图像时,就有了更精确的先验知识,从而能更准确地进行跟踪。反过来,前端提供的连续、有序的帧信息也帮助后端更好地理解场景的拓扑结构,进行更有效的优化。
统一模型的训练策略
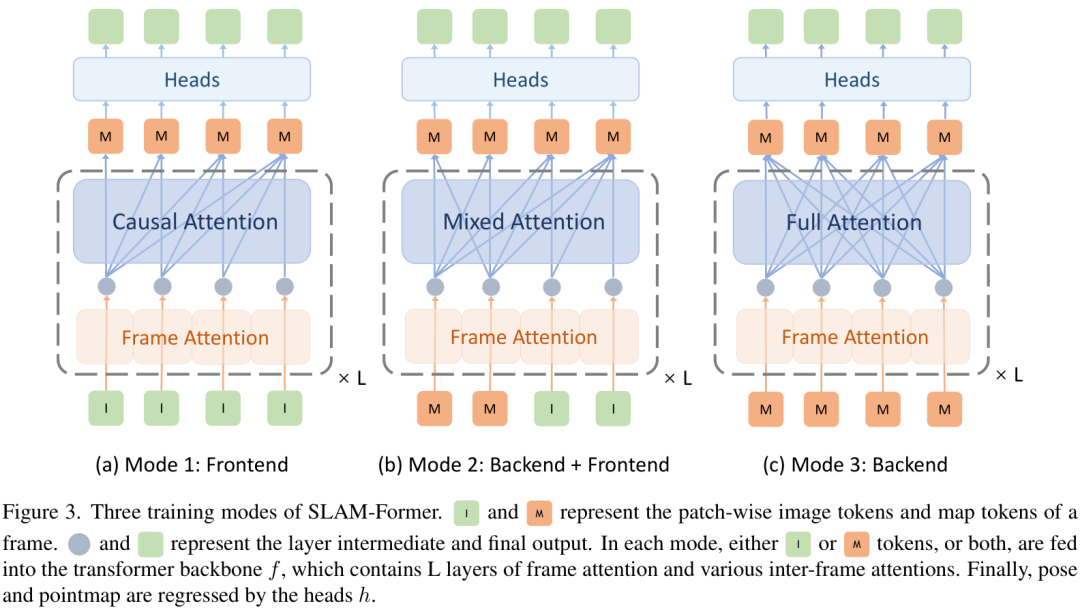
为了让一个模型同时学会前端和后端两种能力,作者设计了三种训练模式,并在一次迭代中交替进行:
-
模式1:前端训练(Causal Attention):模拟在线跟踪场景,模型只能看到当前和过去的帧,不能“预知未来”。
-
模式2:后端+前端协同训练(Mixed Attention):一部分信息使用全局注意力(模拟后端优化),另一部分新来的信息使用因果注意力(模拟前端利用后端优化结果进行跟踪)。
-
模式3:后端训练(Full Attention):模型可以“纵览全局”,对所有输入信息进行无限制的注意力计算,专注于全局一致性的优化。
通过这种联合训练,SLAM-Former学会了在不同模式下无缝切换,实现了“一机两用”。
实验效果:精度与质量齐飞
理论说得再好,还得看疗效。作者在多个主流的SLAM benchmark上进行了测试,包括TUM RGB-D、7-Scenes和Replica。
轨迹精度(ATE)
在轨迹精度方面,SLAM-Former展现了非常强的竞争力。
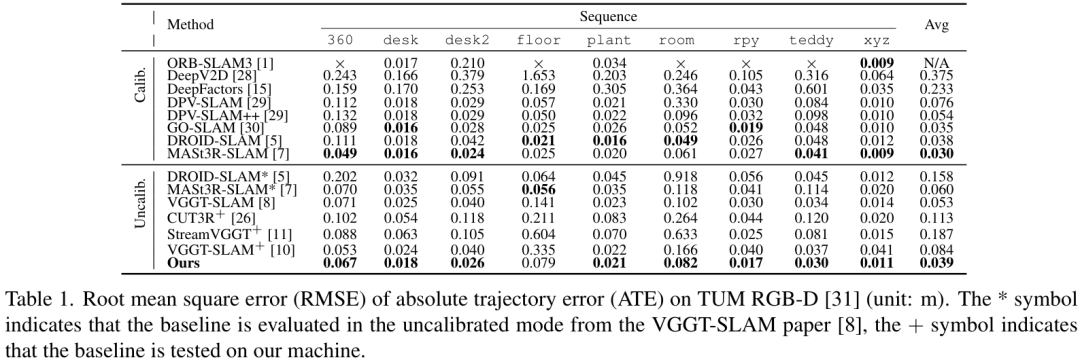
在TUM RGB-D数据集上,SLAM-Former的平均ATE(绝对轨迹误差)达到了 0.039m,优于很多SOTA方法。
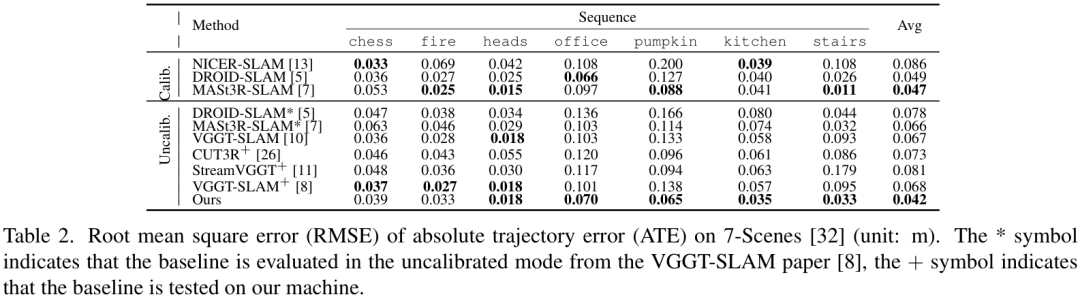
在更具挑战性的7-Scenes数据集上,它的表现同样出色,平均ATE为 0.042m,全面超越了对比的基线模型。
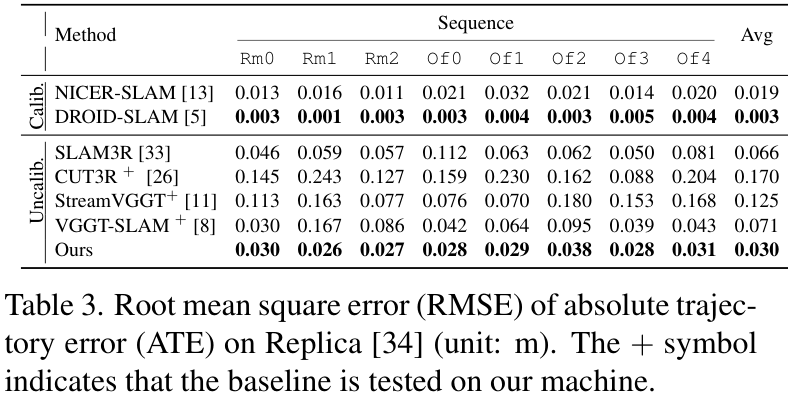
在Replica合成数据集上,也取得了极具竞争力的结果。
重建质量
除了轨迹精度高,建图的质量也非常关键。

从上图的定性比较可以看出,像StreamVGGT和VGGT-SLAM等方法在重建的场景中出现了明显的结构错误和错位(红框部分),而SLAM-Former得益于其全局一致性优化,重建的结构非常完整和准确。
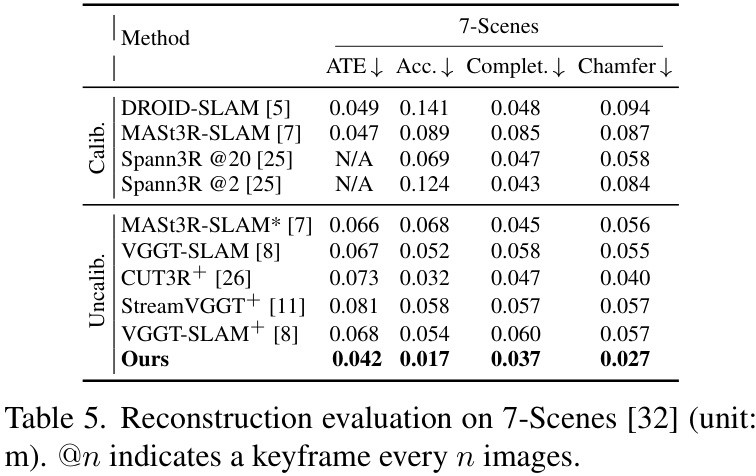
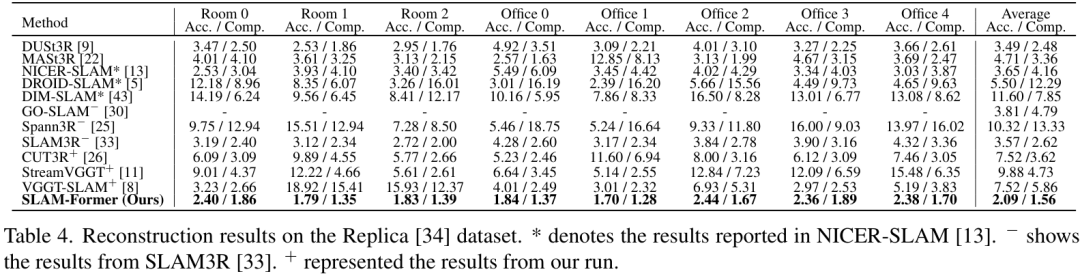
在7-Scenes和Replica数据集上的量化指标也证明了这一点,SLAM-Former在重建的准确性(Acc.)、完整性(Comp.)和Chamfer距离上都大幅领先。例如,在7-Scenes上,其重建准确度达到了 0.017m,比其他方法高出约 50% 。
前后端协同作用的威力
为了证明前后端“互相促进”的有效性,作者做了一个消融实验。
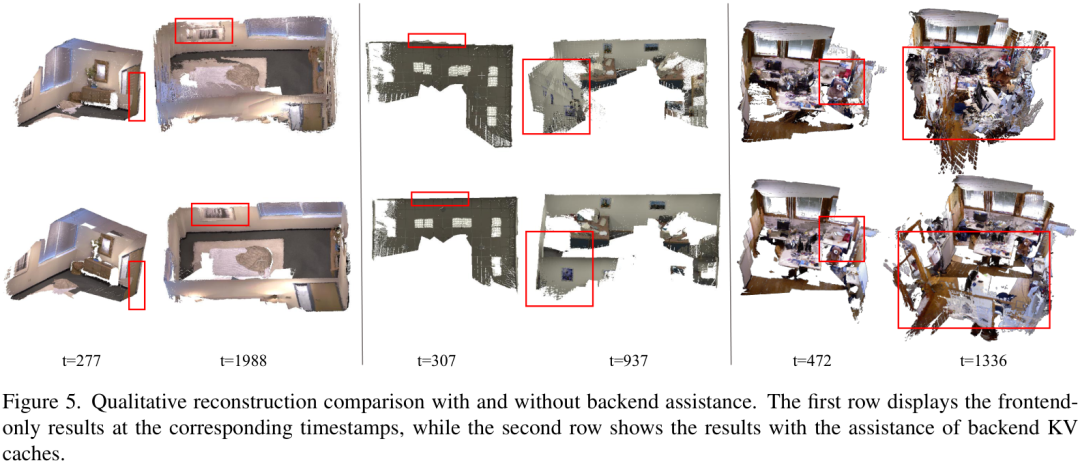
上图展示了有无后端辅助的重建效果对比。第一行是只有前端工作时的结果,可以看到随着时间推移,模型累积了误差,导致重建结果(如墙面)严重变形。而第二行加入了后端优化后,重建的场景始终保持着良好的一致性和准确性。

同样,如果只给后端一堆无序的关键帧(不带前端提供的时序信息),像VGGT和Pi3这样的模型会产生混乱的重建结果。而SLAM-Former的后端因为利用了前端的隐式顺序,能够生成更连贯、准确的地图。
运行效率
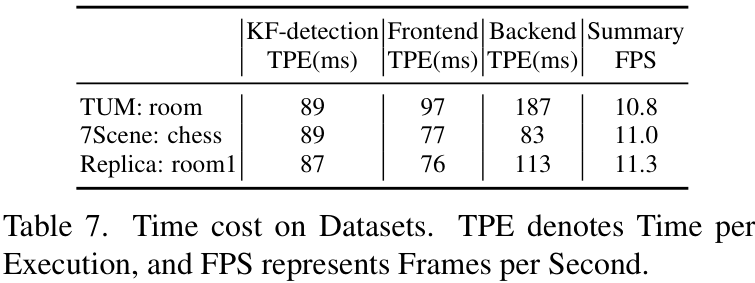
最后,谈谈速度。SLAM-Former在单个RTX 4090 GPU上,整体运行速度 超过10Hz,满足了实时性的要求。
总结
小编认为,SLAM-Former为视觉SLAM领域带来了一个非常简洁且强大的新范式。它用一个统一的Transformer模型取代了传统复杂的双模块流水线,不仅简化了系统设计,还通过巧妙的前后端协同机制,实现了性能上的巨大提升。这种“大一统”的思想,无疑为未来端到端的SLAM系统发展指明了一个极具潜力的方向。
当然,作者也提到了一些局限性,比如后端全局注意力的二次方复杂度问题。但他们也指出了未来可以探索的方向,如稀疏注意力等。大家对这个统一的SLAM范式怎么看?欢迎在评论区留下你的看法!
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









