




本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/b57doMQci9fppxZEDOcgyA

精简阅读版本
本文主要解决了什么问题
-
1. 微创手术视频语义分割的高精度需求问题:微创手术(MIS)过程中产生大量视频数据,但现有方法在处理这些数据时面临性能瓶颈,尤其是在遮挡、纹理变化和动态光照等复杂场景下。
-
2. 传统模型性能瓶颈问题:如U-Net、S3Net等模型在手术分割任务中难以突破平均IoU 75%的上限。
-
3. Prompt依赖问题:当前先进的分割模型(如SAM系列)依赖人工Prompt,难以适应长时间手术视频的自动化分析。
-
4. 密集标注耗时问题:手术视频数据标注工作量大且耗时,亟需减少对人工标注的依赖。
本文的核心创新是什么
-
1. 提出CLIP-RL框架:将CLIP(对比语言图像预训练)与强化学习(RL)结合,构建端到端的语义分割模型,无需依赖Prompt。
-
2. 基于强化学习的自适应残差校正机制:通过RL Agent动态调整分割输出,提升分割边界精度,尤其在区分手术器械与邻近组织时具有临床意义。
-
3. 课程学习策略引导训练过程:采用渐进式训练策略,先强调分割损失,再逐步引入强化学习损失,提升模型训练稳定性和最终性能。
-
4. 多分辨率编码器-解码器结构优化:利用冻结的CLIP视觉Transformer作为编码器,结合轻量级解码器,有效提取语义信息并恢复空间细节。
结果相较于以前的方法有哪些提升
-
1. 在EndoVis 2017数据集上达到74.12% mIoU,优于当前主流模型如TransUNet、SurgicalSAM等。
-
2. 在EndoVis 2018数据集上实现81% mIoU和88% Dice分数,显著优于SegFormer、AdaptiveSAM和nn-UNet等SOTA模型。
-
3. 在多个手术器械和解剖结构类别中表现最优,如IS(0.93)、夹具(0.85)、小肠(0.97)等。
-
4. 具备良好的鲁棒性:在遮挡、动态光照、纹理变化等挑战性场景下仍保持稳定性能。
局限性总结
-
1. 对特定类别分割效果有限:如在EndoVis 2018数据集中,CLIP-RL在CK(Cooking Kit)和Thread类别上的表现弱于SegFormer,说明某些复杂结构仍存在优化空间。
-
2. 未充分利用视频时序信息:当前模型主要基于单帧图像处理,未考虑手术视频中的时间连续性和动态变化,限制了对运动模式的建模能力。
-
3. 模型复杂度与实时性问题:虽然模型在性能上表现优异,但其基于CLIP的架构可能在计算资源和推理速度方面存在限制,影响临床实时应用。
-
4. 泛化能力需进一步验证:目前评估仅基于EndoVis两个数据集,未来需在更多手术类型和设备来源的数据上验证模型泛化能力。
深入阅读版本
导读
理解手术场景能够为患者提供更优质的医疗服务,尤其是在微创手术(MIS)过程中产生的海量视频数据。处理这些视频能够为训练复杂模型生成宝贵资源。本文介绍了CLIP-RL,一种专为手术场景语义分割设计的全新对比语言图像预训练模型。CLIP-RL提出了一种新的分割方法,该方法结合了强化学习和课程学习,能够在整个训练流程中持续优化分割 Mask 。CLIP-RL在不同光学设置下表现出鲁棒性能,如遮挡、纹理变化和动态光照等,这些均构成显著挑战。CLIP模型作为强大的特征提取器,能够捕捉丰富的语义上下文,从而增强器械与组织的区分度。强化学习模块通过迭代动作空间调整,动态优化预测结果。作者在EndoVis 2018和EndoVis 2017数据集上评估了CLIP-RL。CLIP-RL达到了81%的平均IoU(IoU),优于当前最优模型,并在EndoVis 2017数据集上取得了74.12%的平均IoU。这一卓越性能得益于对比学习与强化学习及课程学习的结合。
1. 引言
微创手术(MIS)已在多个专科领域取代了传统开腹手术[1],这得益于其显著的优势,如减少出血量[2]、减轻术后疼痛[3]以及更快的恢复时间[4][5]。MIS通过高分辨率手术摄像头[6]生成大量视觉数据,为通过计算机辅助分析[8][9]提升手术效果和进行手术培训提供了前所未有的机遇。然而,场景的巨大多样性以及视频的庞大体积[10],这些视频有时可能长达数小时,使得数据标注[12]工作既费力又耗时[11]。
近年来,分割方法的新进展表明传统卷积方法已经遇到了性能 Bottleneck 。大多数基础模型未能超过平均IoU(mIoU)75%,例如S3Net [13]、MATIS Frame [14]和U-Net [15]。随着视觉语言模型(VLMs)的革新,分割一切模型(SAM)[16]已成为最先进的方法,在 Mask 生成方面表现出色。该模型已被针对不同领域进行微调,许多适配方案专门为手术领域定制,如Track Anything [17]、PerSAM [18]和SurgicalSAM [19]。然而,它们对 Prompt 的依赖性使得分析长时间的手术视频变得不切实际 [20]。
为解决密集分割工作中的劳动密集问题,作者提出了一种利用预训练的视觉语言模型(VLM)进行手术器械分割的新框架,从而最大限度地减少人工标注的需求。CLIP-RL结合了基于ResNet的CLIP模型和轻量级解码器,并呈现了一种受强化学习启发的自适应机制。
2. 背景和相关工作
语义图像分割在医学影像(例如肿瘤检测)[21]和机器人技术(例如手术辅助)[22]中应用广泛。传统方法,如阈值处理和边缘检测[23],在处理复杂纹理和光照变化时存在困难。基于深度学习的方法,特别是卷积神经网络(CNN)和视觉Transformer(ViT),通过捕捉图像的层次化和上下文特征,显著提升了分割效果。
A. 卷积神经网络用于分割
卷积神经网络(CNNs)通过捕捉空间层次结构革新了分割技术。U-Net [15] 是一种编码器-解码器模型,在医学影像中广泛用于精确分割 [24], [25]。然而,CNNs 在处理长距离依赖和全局上下文理解方面存在困难。
B. 用于分割的视觉Transformer
ViTs [26] 使用自注意力机制来捕获局部和全局特征。ViTs 在具有大空间上下文的任务中(例如全身MRI分割[27])表现出优于CNN的性能。Segmenter和SETR [28], [29] 等模型实现了当前最佳性能,但需要大量数据集和高计算资源,限制了其实时应用。
C. 混合CNN-Transformer架构
混合模型结合卷积神经网络(CNN)进行局部特征提取与Transformer进行全局推理。TransUNet提升了医学分割(例如前列腺MRI)的性能[30][31]。SegFormer用Transformer替代卷积解码器,在多种领域(如航空图像分割)中取得了稳健的结果[32]。
D. 视觉语言模型(VLMs)用于分割
视觉语言模型(VLMs)将文本描述与图像数据相结合,提升了泛化能力和可解释性。CLIP实现了零样本分割,辅助罕见肿瘤检测[33]。BLIP增强了医学标注的自监督学习[34]。在机器人手术中,VLMs支持实时解剖结构高亮,优化手术决策[35]。这些模型推动分割技术向更可解释的AI驱动应用方向发展。
CLIP-RL采用冻结的CLIP编码器作为编码器-解码器分割网络的核心。CLIP的对比学习范式在特征空间中聚类语义相似的图像,同时将不相似的图像推开,从而生成鲁棒、可迁移的表示[19][37]。Radford等人(2021)证明CLIP在超过30个分类数据集上实现了强大的零样本迁移,其性能往往与特定任务模型相当甚至超越[33]。相比之下,如DINOv2[9]等自监督视觉Transformer在ImageNet的线性 Prob 评估中达到85.8%的Top-1准确率,但并未利用任何语言监督[9]。重要的是,在一个涵盖117个分类数据集的行业基准测试中,CLIP RN50×4-highres在80%的任务中表现最佳,而DINOv2仅占20%[7]。因此,CLIP提供了一种真正的零 Prompt 特征提取器——类似于纯视觉方法——同时展现出卓越的迁移性能。
3. 方法
A. 方法概述
CLIP-RLCLIP-RL集成了两个关键组件,如图1所示:一个多分辨率编码器-解码器分割网络和一个基于强化学习(RL)的模块。CLIP模型作为模型的编码器,捕获输入特征。
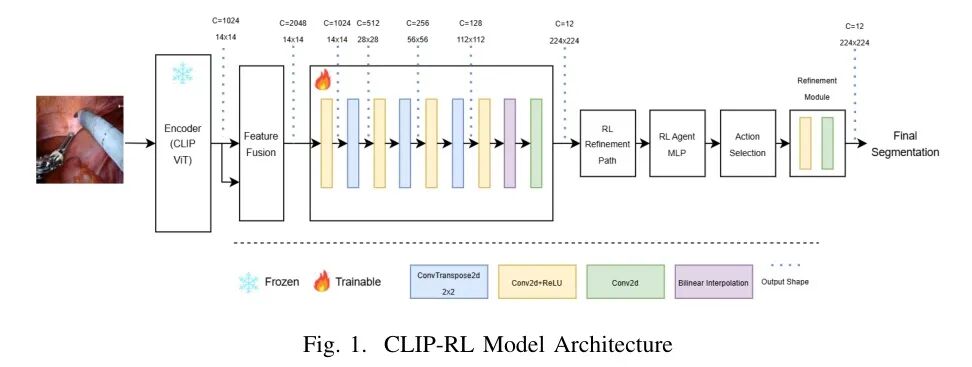
生成的特征图被传递到一个轻量级解码器以生成分割logit。最后,基于强化学习的细化模块作为一个自适应决策者,通过应用残差校正[38]来调节初始分割输出。训练过程由一个混合损失函数指导,该函数结合了传统的分割损失(交叉熵和Dice损失)以及从强化学习中推导出的策略梯度损失。采用课程学习策略[39]逐渐将训练重点从分割专业化过渡到全模型协作,以确保在复杂的手术场景中实现鲁棒性能。
B. 详细设计

混合损失的课程学习

C. 实现细节

4. 实验 & 结果
作者在两个公开的机器人辅助手术数据集上评估了作者提出的框架:EndoVis 2017 [44] 和 EndoVis 2018 [45]。EndoVis 2017 数据集提供了一个成熟的基准,专注于微创手术中的工具分割。EndoVis 2018 数据集通过包含手术器械和解剖结构的标注,提供了更全面的挑战。在作者的研究中,作者使用 EndoVis 2018 来执行整体场景分割。这种双任务设置至关重要,因为作者需要准确界定手术器械与附近组织之间的细微界限。作者遵循了 MICCAI 社区提供的数据训练和测试划分。验证集占专门训练数据集的 20%,并随机划分。模型在 Paperspace 上使用 Gradient 进行 V100 训练。
A. 结果
作者使用标准的分割指标报告了作者的定量结果,包括整体模型的平均IoU(mIoU)、每类mIoU和Dice系数。CLIP-RL优于SOTA模型,即使那些使用 Prompt 的模型也不例外。
EndoVis 2017数据集被用于评估CLIP-RL的性能。这是一个机器人器械分割数据集,是先前挑战赛的一部分。CLIP-RL与当前最优模型(SOTA)进行了比较:TransUNet [30]、SurgicalSAM [19]、PerSAM和ISINet [46]。表1展示了整体mIoU和分类mIoU。CLIP-RL始终优于 Baseline 模型,实现了74.12%的整体mIoU。该模型在多个器械类别中表现出色,在7个类别中的5个中取得了最高的mIoU:PF(67.9)、LND(78.43)、GR(60.78)、MCS(89.25)和UP(67.39)。虽然S3Net在BF(75.0)上记录了最高的mIoU,而TrackAnything(5 Points)在VS(83.68)上领先,但CLIP-RL在这些类别中取得了第二高的性能。结果突出了作者多分辨率特征提取、基于RL的精炼以及课程学习策略在提高分割精度方面的优势。

EndoVis 2018是一个整体手术场景分割挑战赛,其中同时分割手术工具和解剖结构。结果表明,CLIP-RL在分割性能上优于当前最先进的模型。如表2所示,CLIP-RL实现了最高的平均IoU(0.81)和Dice分数(0.88),优于SegFormer(0.75 mIoU,0.82 Dice)、AdaptiveSAM(0.65 mIoU,0.69 Dice)和nn-UNet(0.61 mIoU,0.73 Dice)。图3展示了CLIP-RL的分割 Mask 与真实值。可以看出,CLIP-RL正确分割了所有工具,除了线这一对模型具有挑战性的类别。
表3中的逐类分析进一步支持了这一观点,CLIP-RL在11个类别中的8个类别中取得了最高的mIoU,特别是在器械分割(IS: 0.93)、夹具(0.85)和小肠等软组织结构(0.97)方面表现突出。此外,它在IC、IW、SN、SI和UP类别中表现出色,增强了其泛化能力。然而,SegFormer在CK(0.63 vs. 0.67)和Thread(0.58 vs. 0.66)类别中表现优于CLIP-RL,这表明了进一步优化的空间。这些结果表明,CLIP-RL的整体性能在大多数类别以及总体性能方面均优于U-Net、TransUNet和SegFormer。这些结果突出了CLIP-RL作为手术视频分割的SOTA解决方案,展示了其对器械和解剖结构的精确识别能力。
B. 消融研究
为评估作者提出框架中不同组件的影响,作者通过逐步添加关键模块——课程学习(Curriculum Learning)和强化学习(Reinforcement Learning, RL)——进行了消融研究。不包含这些组件的 Baseline 模型作为参考。
表4所示的结果表明,通过提供一种渐进式训练策略,从而增强模型在复杂区域上的收敛性,Curriculum Learning的添加提升了mIoU和Dice分数。进一步集成强化学习使模型能够动态调整其预测,从而带来额外的性能提升。
5. 结论
在这项工作中,作者提出了CLIP-RL,一个用于手术图像分割的新型框架,该框架集成了多分辨率编码器-解码器网络和基于强化学习(RL)的细化模块。通过利用冻结的CLIP视觉Transformer,CLIP-RL能够有效捕捉细粒度的空间细节和High-Level语义信息,确保解剖结构和手术器械的准确分割。强化学习(RL)模块通过自适应残差校正机制进一步细化分割预测,允许动态调整以提升分割精度。
为确保训练稳定性和最大化性能,作者采用了一种课程学习策略,逐步将学习重点从分割精度过渡到全模型协作。这种方法有效地平衡了传统分割损失(交叉熵损失和Dice损失)与策略梯度优化,使强化学习Agent能够以结构化的方式优化预测。
实验结果表明,CLIP-RL在手术分割任务中优于现有最先进模型,在mIoU和Dice分数方面均取得了更优的结果。视觉语言预训练、强化学习和课程学习的结合使CLIPRL特别适用于手术视频分析所面临的挑战,其中精度和适应性至关重要。
未来的工作将包括将CLIP-RL扩展到多模态融合,并整合额外的手术线索,例如时间视频信息和器械运动学,以提高动态手术环境中的分割精度。
参考
[1]. CLIP-RL: Surgical Scene Segmentation Using Contrastive Language-Vision Pretraining & Reinforcement Learning
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









