






本文来源公众号“Ai学习的老章”,仅用于学术分享,侵权删,干货满满。
原文链接:阿里Qwen3 全部情报汇总,本地部署指南,性能全面超越 DeepSeek R1

R2 还没落地,Qwen3 来了。
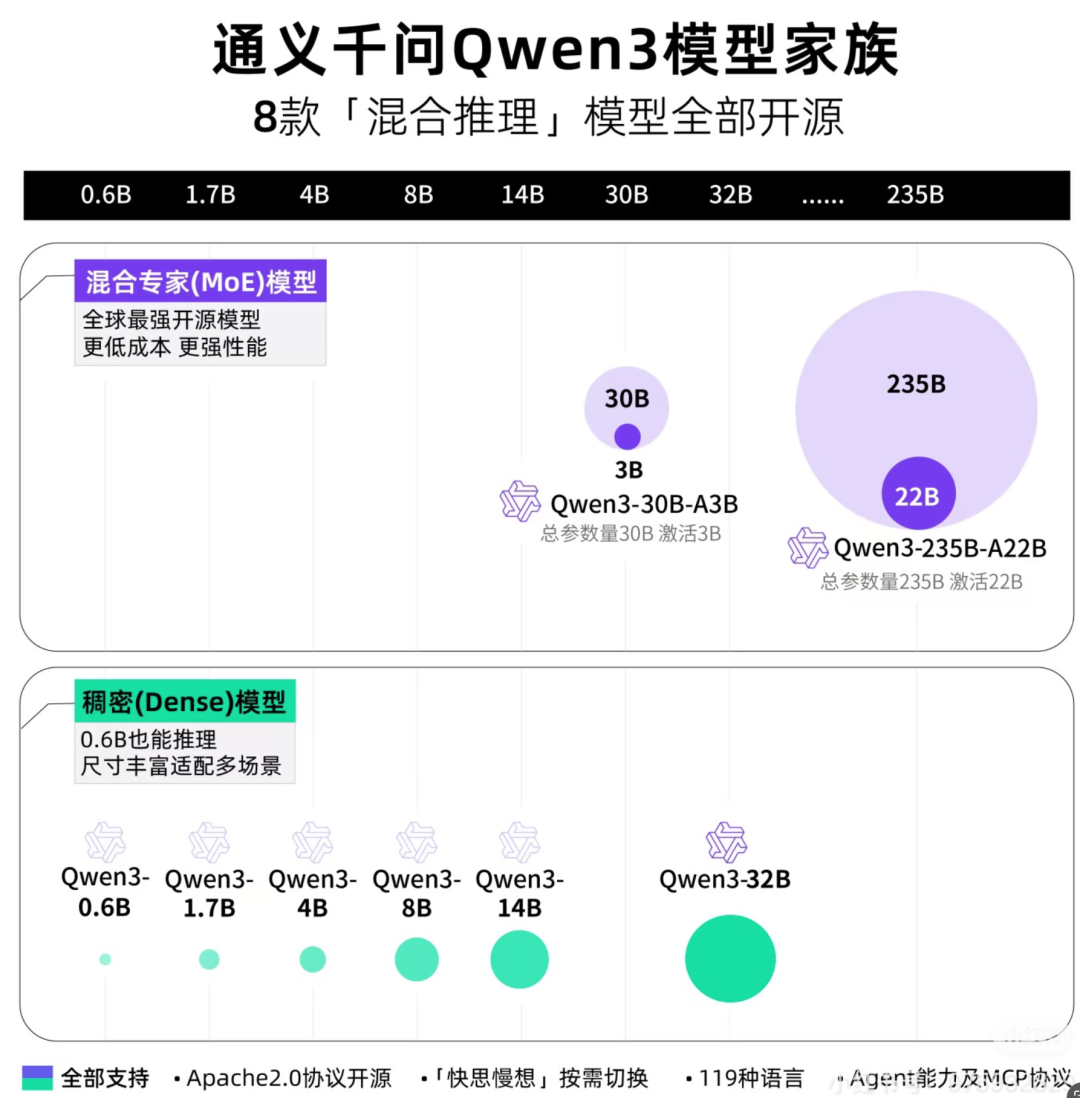
开源 8 款模型:6 款 Dense 模型 +2 款 MoE 模型
技术细节大家可以看看 Qwen 技术博客,建议点开看看,干货很多:https://qwenlm.github.io/blog/qwen3/

8 个不同尺寸的模型,照顾到了所有场景:
6 款 Dense 模型:
0.6B、1.7B、4B、8B、14B、32B
2 款 MoE 模型:
Qwen3-235B-A22B (MoE, 总大小 235B, 激活参数 22B, 上下文 128K)
Qwen3-30B-A3B (MoE, 总大小 30B, 激活参数 3B, 上下文 128K)
混合思维模式,搭载了 thinking 开关,可以直接手动控制要不要开启 thinking
最大的这个 Qwen3-235B-A22B 在强劲性能的基础上,部署成本仅为 Deepseek R1 的 35%。
Qwen3-30B-A3B 的激活参数只有 3B,性能却可以跟 QWQ-32B 打平,成本只有 10%,可以在消费级显卡上部署。
0.6B 的小参数模型适合在移动设备上部署。
在性能上 Qwen 3 的每个尺寸得分都是同尺寸开源最强。
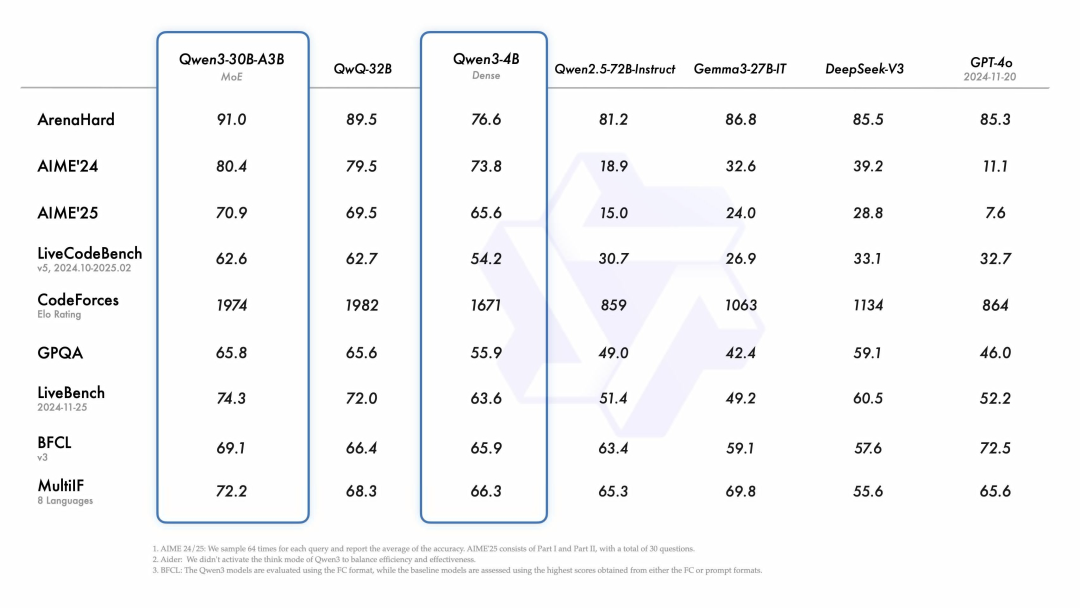
Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 相比,表现出极具竞争力的结果。
此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹
正如博客所说,Qwen 朋友圈非常强大,昨晚已发布,一众伙伴就 0day 级支持
你可以在 Qwen 官网直接与 Qwen3v 不同参数模型直接对话:https://chat.qwen.ai/

本地部署
ollama
模型页:https://ollama.com/library/qwen3
运行:ollama run qwen3
其他尺寸,在后面加参数即可,比如:ollama run qwen3:32b
可以在提示词后输入 /no_think 来切换 Ollama 中的无思考模式。
备注⚠️:ollama 运行的是量化版,效果有折扣
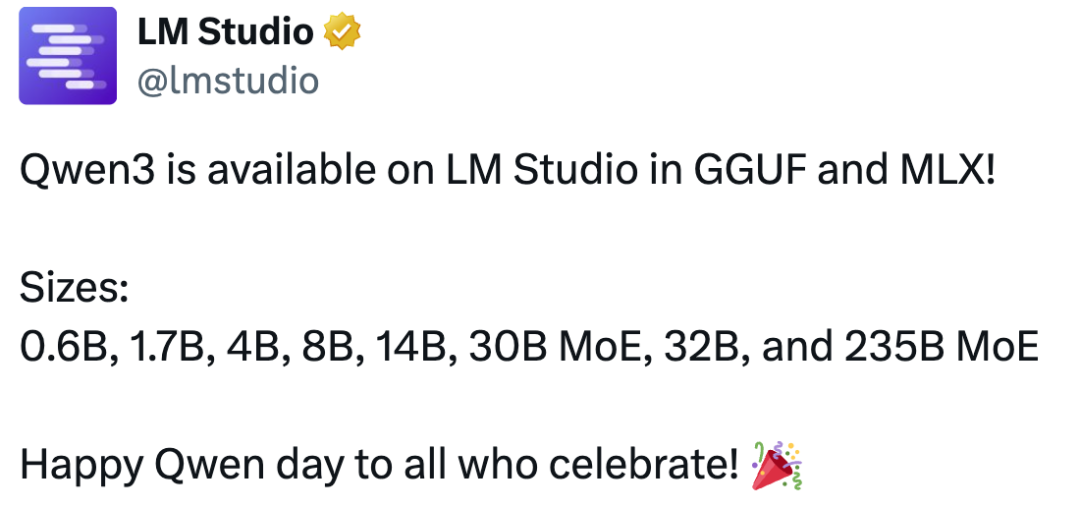
LM Studio
地址:https://lmstudio.ai/
vLLM

需要升级到 v0.8.4 以上,最好 v0.8.5
地址:https://github.com/vllm-project/vllm/issues/17327
vllm serve Qwen/Qwen3-235B-A22B-FP8 --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 4
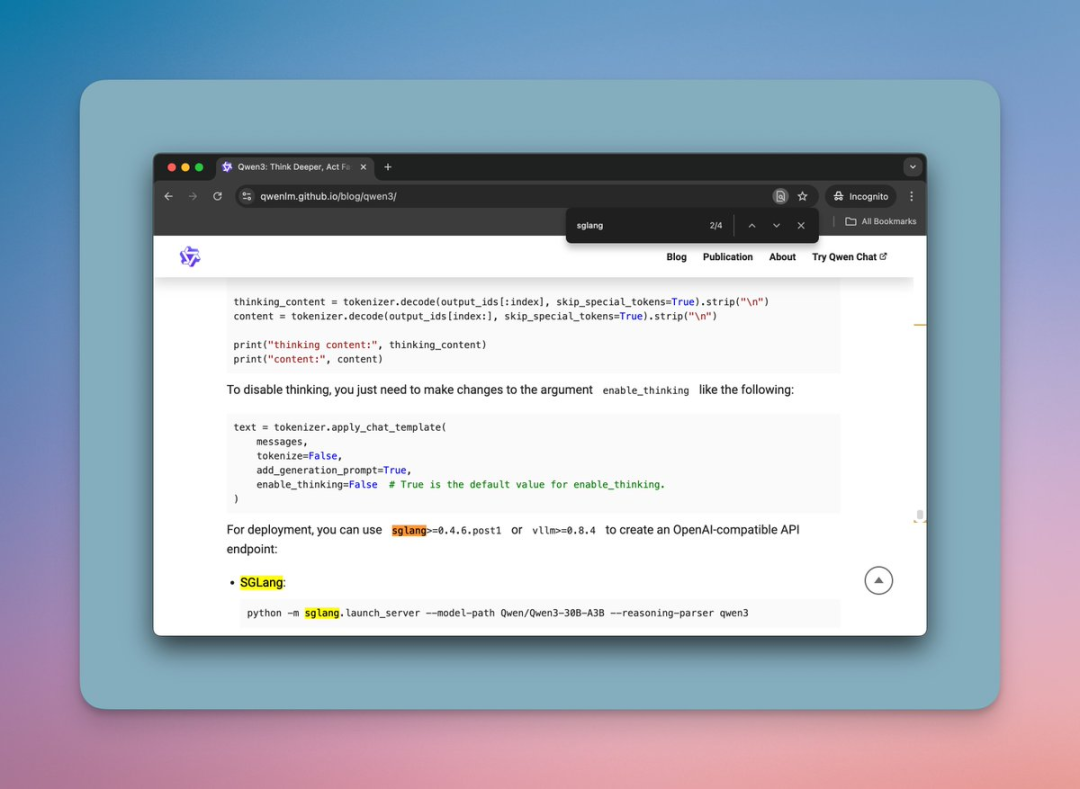
SGLang
需要升级到SGLang 0.4.6.post1
地址:https://github.com/sgl-project/sglang
pip3 install "sglang[all]>=0.4.6.post1"
python3 -m sglang.launch_server --model Qwen/Qwen3-235B-A22B --tp 8 --reasoning-parser qwen3
python3 -m sglang.launch_server --model Qwen/Qwen3-235B-A22B-FP8 --tp 4 --reasoning-parser qwen3
CPU 部署
llama.cpp
可以用 llama.cpp 运行起 Qwen3 量化版本、动态量化版本!
地址:https://huggingface.co/collections/unsloth/qwen3-680edabfb790c8c34a242f95
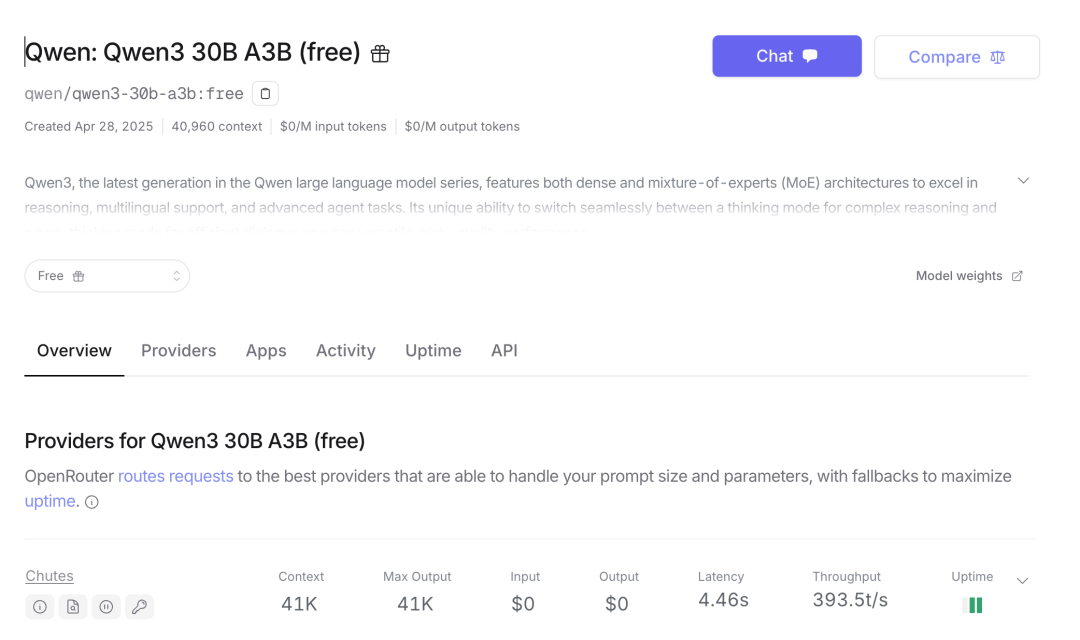
OpenRouterAI
openrouter 提供了免费的 API
地址:https://openrouter.ai/models?order=newest&q=qwen3
KTransformer
Xeon 铂金 4 代 + 4090 运行 Qwen3-235B-A22B 单个请求可以达到 13.8 token/s, 4 个请求并行可以达到总计 24.4 token/s
地址:http://github.com/kvcache-ai/ktransformers/blob/main/doc/en/AMX.md
Mac
Mac 上也可以跑 Qwen3 了
地址:https://github.com/ml-explore/mlx-lm/commit/5c2c18d6a3ea5f62c5b6ae7dda5cd9db9e8dab16
pip install -U mlx-lm
# or
conda install -c conda-forge mlx-lm
支持设备
-
iPhone: 0.6B, 4B
-
Macbook: 8B, 30B, 3B/30B MoE
-
M2, M3 Ultra: 22B/235B MoE
Qwen3 优点还有很多,我正在下载,随后再发本地部署后的测试情况:
-
Qwen3 是全球最强开源模型,性能全面超越 DeepSeek R1,国内第一个敢说全面超越 R1 的模型,之前都是比肩
-
Qwen3 是国内首个混合推理模型,复杂答案深度思考,简单答案直接秒回,自动切换,提升智力 + 节省算力双向奔赴
-
模型部署要求大幅降低,旗舰模型仅需 4 张 H20 就能本地部署,部署成本估算下来是能比 R1 下降超 6 成
-
Agent 能力大幅提升,原生支持 MCP 协议,提升了代码能力,国内的 Agent 工具都在等它
-
支持 119 种语言和方言,包括爪哇语、海地语等地方性语言,全世界都可以用上 AI
-
训练数据 36 万亿 token,相比 Qwen2.5 直接翻倍,不仅从网络抓取内容,还大量提取 PDF 的内容、大量合成代码片段
-
模型部署要求大幅降低,旗舰模型仅需 4 张 H20 就能本地部署,是 R1 的三分之一
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









