 Saga与TCC模式选择、补偿及监控指南
Saga与TCC模式选择、补偿及监控指南





(一) Saga模式与TCC模式的选择
一、核心差异对比
| 维度 | Saga模式 | TCC模式 |
|---|---|---|
| 事务模型 | 本地事务+补偿机制 | 预留资源+确认/取消机制 |
| 实现复杂度 | 较低(只需设计补偿操作) | 较高(需设计Try/Confirm/Cancel三阶段) |
| 性能影响 | 较低(异步执行补偿) | 较高(需预留资源,同步执行Try阶段) |
| 适用场景 | 长业务流程、允许短暂不一致 | 资金类、强一致性要求的场景 |
| 失败处理 | 补偿操作可能失败(需重试机制) | 资源预留可能失败(需严格超时控制) |
二、选择决策树
文章中的mermaid 经常报错 直接生成图片 贴出来
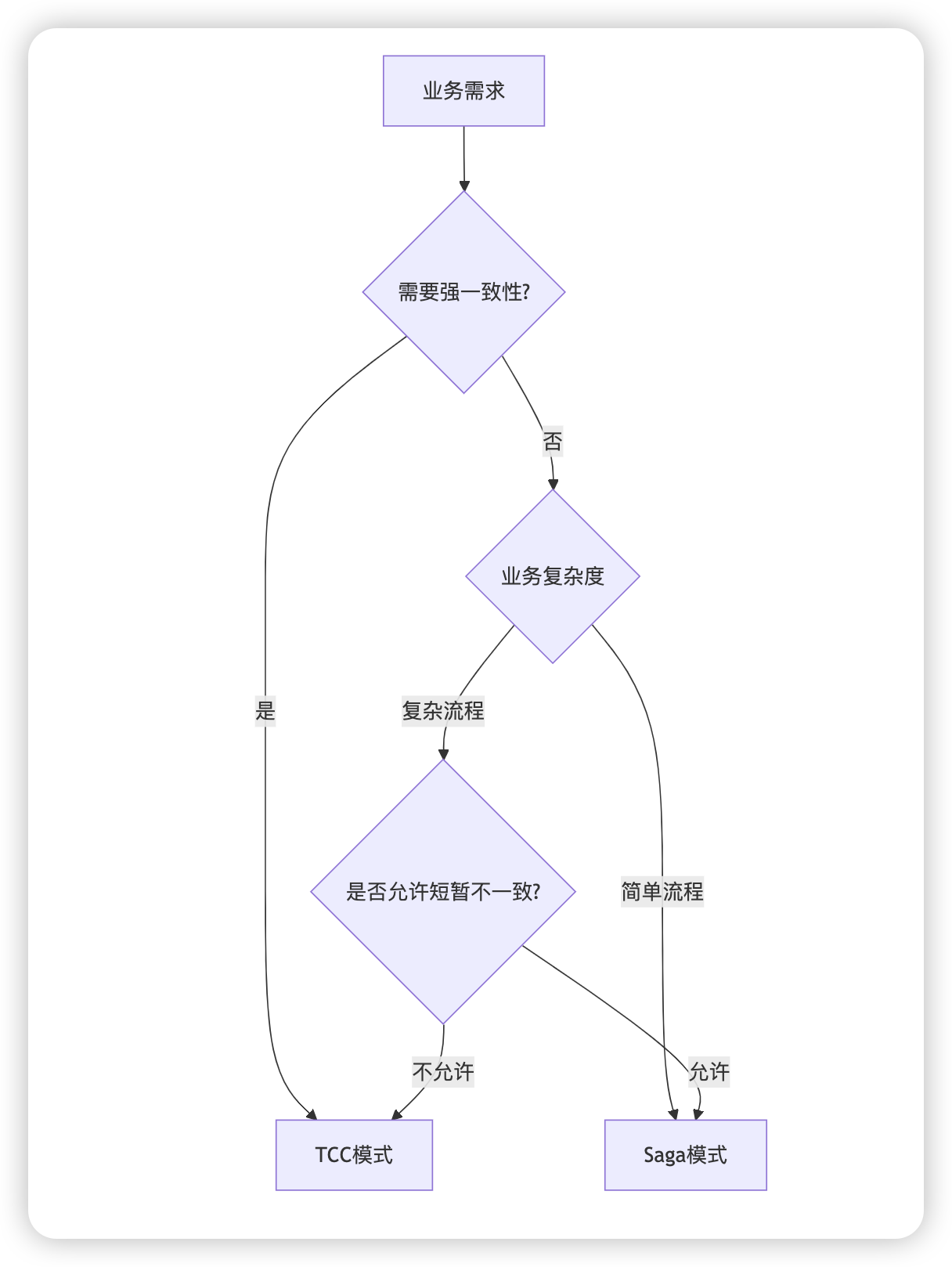
三、具体选择建议
1. 优先选择Saga模式的场景
✅ 典型业务案例:
- 电商下单流程(订单→库存→支付)
- 订单取消/退款流程
- 供应链管理(订单生成→物流调度→库存更新)
✅ 选择理由:
-
业务流程长且复杂:
- 涉及多个服务协作,TCC的Try阶段会显著增加系统复杂度
- Saga的补偿机制更适合处理长链条业务
-
允许短暂不一致:
- 如订单创建后库存扣减可能延迟,但最终会一致
- 用户体验可接受短暂延迟(如"您的订单正在处理中")
-
性能要求高:
- Saga的异步补偿不会阻塞主流程
- 避免TCC的Try阶段资源预留带来的性能开销
-
补偿操作可控:
- 补偿逻辑相对简单(如"取消订单"、“恢复库存”)
- 不需要复杂的预留资源管理
2. 必须选择TCC模式的场景
✅ 典型业务案例:
- 跨行转账
- 支付系统(资金冻结→支付→解冻)
- 库存预售系统(锁定库存→支付→确认订单)
✅ 选择理由:
-
强一致性要求:
- 资金操作必须保证"要么全部成功,要么全部失败"
- 不允许出现资金不一致的情况
-
资源预留必要:
- 需要先冻结资源(如资金、库存)再确认
- 避免超卖或资金超额扣除
-
业务风险高:
- 失败可能导致重大损失(如资金损失、库存混乱)
- TCC的严格三阶段能最大限度降低风险
-
补偿成本高:
- 补偿操作可能比正向操作更复杂(如资金退回)
- TCC的Try阶段能提前发现潜在问题
3. 混合使用策略
在实际项目中,可以结合两种模式的优势:
- 核心资金流用TCC:保证强一致性
- 非核心业务流用Saga:提高系统吞吐量
- 示例:
- 支付系统(TCC) + 订单处理(Saga)
- 库存锁定(TCC) + 物流调度(Saga)
四、关键决策因素
-
一致性要求:
- 强一致性 → TCC
- 最终一致性 → Saga
-
业务复杂度:
- 简单流程 → Saga
- 复杂流程 → TCC(或混合)
-
性能需求:
- 高吞吐量 → Saga
- 低延迟关键操作 → TCC
-
补偿成本:
- 补偿简单 → Saga
- 补偿复杂 → TCC
-
失败容忍度:
- 不允许任何不一致 → TCC
- 允许短暂不一致 → Saga
五、实际项目建议
-
新项目:
- 先评估业务一致性要求
- 优先尝试Saga模式(实现简单)
- 对关键路径可逐步引入TCC
-
已有项目改造:
- 分析现有业务流程的失败影响
- 对高风险操作逐步迁移到TCC
- 保持其他部分使用Saga
-
混合架构设计:
- 使用TCC处理资金、库存等核心资源
- 使用Saga处理订单、物流等非核心流程
- 通过事件总线连接两种模式
六、总结
- 选Saga:当业务允许短暂不一致、流程复杂但补偿可控、需要高吞吐量时
- 选TCC:当业务要求强一致性、涉及资金/库存等关键资源、补偿成本高时
- 混合使用:根据业务模块的重要性和一致性要求灵活选择
最终选择应基于:
- 业务的一致性需求
- 系统的性能要求
- 补偿操作的复杂度
- 团队的技术能力和维护成本
(二) Saga模式与TCC模式补偿机制的具体差异
1. 补偿触发时机
| 模式 | 触发条件 | 典型场景 |
|---|---|---|
| Saga | 正向操作失败时触发补偿 | 订单创建失败 → 补偿:取消订单 |
| TCC | Confirm阶段失败时触发补偿 | 支付确认失败 → 补偿:释放冻结资金 |
2. 补偿操作设计
| 维度 | Saga模式 | TCC模式 |
|---|---|---|
| 操作性质 | 直接撤销正向操作 | 释放预留资源 |
| 操作复杂度 | 较简单(直接回滚) | 较复杂(需管理预留状态) |
| 示例 | 订单取消 → 恢复库存 | 支付失败 → 解冻资金 |
3. 补偿执行方式
| 特性 | Saga模式 | TCC模式 |
|---|---|---|
| 执行顺序 | 逆向执行(从后往前) | 正向执行(按Try顺序) |
| 幂等性要求 | 必须幂等(可能重试) | 必须幂等(可能重试) |
| 超时处理 | 无严格超时 | 需严格超时控制(防止资源永久锁定) |
4. 补偿可靠性保障
| 机制 | Saga模式 | TCC模式 |
|---|---|---|
| 状态跟踪 | 依赖事件日志或状态机 | 依赖Try/Confirm状态标记 |
| 失败重试 | 可重试补偿操作 | 可重试Confirm操作 |
| 死信处理 | 补偿失败进入死信队列 | Confirm失败进入死信队列 |
5. 典型实现差异
Saga补偿示例(订单取消):
// 正向操作
public void createOrder(Order order) {
orderRepository.save(order); // 1. 创建订单
inventoryService.decreaseStock(order.getProductId(), order.getQuantity()); // 2. 扣减库存
}
// 补偿操作(逆向执行)
public void cancelOrder(Order order) {
inventoryService.increaseStock(order.getProductId(), order.getQuantity()); // 1. 恢复库存
orderRepository.delete(order); // 2. 删除订单
}
TCC补偿示例(支付处理):
// Try阶段
public void tryPayment(Payment payment) {
accountService.freezeFunds(payment.getUserId(), payment.getAmount()); // 冻结资金
}
// Confirm阶段
public void confirmPayment(Payment payment) {
accountService.confirmPayment(payment.getUserId(), payment.getAmount()); // 确认支付
}
// 补偿操作(释放预留资金)
public void cancelPayment(Payment payment) {
accountService.unfreezeFunds(payment.getUserId(), payment.getAmount()); // 解冻资金
}
6. 关键差异总结
| 对比维度 | Saga模式 | TCC模式 |
|---|---|---|
| 补偿本质 | 撤销已执行的操作 | 释放预留的资源 |
| 执行时机 | 正向失败后立即执行 | Confirm失败后执行 |
| 资源占用 | 不占用额外资源 | 需临时占用资源(Try阶段) |
| 实现难度 | 较简单(直接回滚) | 较复杂(需管理预留状态) |
| 适用场景 | 允许短暂不一致的业务 | 强一致性要求的业务 |
7. 实际选择建议
-
选Saga补偿:
- 业务允许短暂不一致
- 补偿操作简单直接(如恢复库存、取消订单)
- 不需要严格资源预留控制
-
选TCC补偿:
- 业务要求强一致性(如资金操作)
- 需要精确控制资源占用(防止超卖/资金超额)
- 补偿操作复杂(如资金退回涉及多账户)
两种模式的补偿机制本质都是"撤销正向操作的影响",但实现方式和适用场景有显著差异,需根据业务一致性要求和资源管理需求选择。
(三) Saga模式与TCC模式补偿失败的处理机制对比
1. 补偿失败后的处理流程差异
| 处理阶段 | Saga模式 | TCC模式 |
|---|---|---|
| 首次补偿失败 | 触发重试机制(可配置重试次数) | 触发重试机制(通常有限次数) |
| 重试失败后 | 进入死信队列/人工干预 | 进入死信队列/人工干预 |
| 最终处理 | 可能需要人工介入或业务降级 | 必须人工介入或业务降级 |
2. 关键处理机制对比
Saga模式补偿失败处理:
- 自动重试:
- 补偿操作失败后自动重试(可配置重试次数和间隔)
- 示例:订单取消补偿失败后,系统每5分钟重试一次
- 死信队列:
- 达到最大重试次数后进入死信队列
- 需要人工介入处理(如客服手动取消订单)
- 业务降级:
- 可允许部分补偿失败(如只补偿部分操作)
- 示例:订单取消时库存补偿失败,但订单状态已更新
TCC模式补偿失败处理:
- 严格重试:
- Confirm阶段补偿失败必须立即重试(通常无重试次数限制)
- 因为资金/资源可能一直处于锁定状态
- 超时控制:
- 必须设置严格的超时时间(防止资源永久锁定)
- 超时后强制释放资源(可能造成业务损失)
- 人工干预:
- 重试失败后必须人工介入处理
- 必须确保资金/资源最终释放(如银行转账必须完成)
3. 典型处理代码示例
Saga补偿失败处理:
// 补偿操作执行器
public class CompensationExecutor {
private int maxRetries = 3;
private long retryInterval = 300000; // 5分钟
public void executeWithRetry(CompensationAction action) {
int retryCount = 0;
while (retryCount < maxRetries) {
try {
action.execute();
return; // 补偿成功
} catch (Exception e) {
retryCount++;
if (retryCount >= maxRetries) {
// 进入死信队列
deadLetterQueue.add(action);
break;
}
// 等待重试
Thread.sleep(retryInterval);
}
}
}
}
TCC补偿失败处理:
// TCC补偿处理器
public class TccCompensationHandler {
private long timeout = 60000; // 1分钟超时
public void handleCompensation(TccAction action) {
long startTime = System.currentTimeMillis();
while (true) {
try {
action.compensate();
return; // 补偿成功
} catch (Exception e) {
long elapsed = System.currentTimeMillis() - startTime;
if (elapsed > timeout) {
// 超时强制释放资源
forceReleaseResources(action);
break;
}
// 等待后重试
Thread.sleep(1000);
}
}
}
private void forceReleaseResources(TccAction action) {
// 强制释放资源的实现
// 可能导致业务损失(如资金部分退回)
}
}
4. 核心差异总结
| 对比维度 | Saga模式 | TCC模式 |
|---|---|---|
| 重试策略 | 可配置有限重试 | 必须持续重试直到成功 |
| 超时控制 | 无严格超时 | 必须设置严格超时 |
| 最终处理 | 允许部分失败 | 必须完全成功 |
| 业务影响 | 可接受部分不一致 | 不允许任何不一致 |
| 人工介入 | 可延迟处理 | 必须尽快处理 |
5. 实际应用建议
-
Saga模式:
- 适合对最终一致性容忍度高的业务
- 补偿失败后可接受短暂不一致
- 可通过死信队列异步处理失败补偿
-
TCC模式:
- 必须确保补偿最终成功
- 需要严格监控补偿失败情况
- 补偿失败可能导致业务风险(如资金锁定)
-
混合策略:
- 对关键资源使用TCC补偿
- 对非关键操作使用Saga补偿
- 设置不同的失败处理策略
两种模式在补偿失败处理上的根本区别在于:Saga允许一定程度的不一致和延迟处理,而TCC必须确保补偿最终成功且不能有资源长期锁定。选择时需根据业务的一致性要求和风险承受能力决定。
(四) 微服务架构中监控Saga和TCC事务执行状态的方法
1. 通用监控指标
| 指标类型 | Saga模式监控点 | TCC模式监控点 |
|---|---|---|
| 事务状态 | 当前阶段(进行中/已完成/失败) | Try/Confirm/Cancel阶段状态 |
| 执行时间 | 各阶段耗时 | Try/Confirm/Cancel各阶段耗时 |
| 失败次数 | 补偿操作失败次数 | Confirm/Cancel失败次数 |
| 重试次数 | 补偿操作重试次数 | Confirm/Cancel重试次数 |
| 超时情况 | 补偿操作超时次数 | Confirm/Cancel超时次数 |
2. Saga模式监控实现
(1)状态跟踪机制
// 使用状态机跟踪事务状态
public enum SagaState {
CREATED, IN_PROGRESS, COMPLETED, FAILED, COMPENSATING
}
// 事务上下文携带状态信息
public class SagaContext {
private String transactionId;
private SagaState state;
private List<SagaStep> steps;
// getters/setters...
}
// 状态变更事件发布
public class SagaStateChangeListener {
@EventListener
public void handleStateChange(SagaStateChangeEvent event) {
// 发送状态变更到监控系统
monitoringService.reportSagaState(event.getTransactionId(), event.getState());
}
}
(2)日志与追踪
- 使用分布式追踪系统(如Zipkin/SkyWalking):
- 为每个Saga事务生成唯一TraceID
- 记录各步骤的执行时间和状态
- 日志集中收集:
- 记录事务ID、步骤、状态变更
- 关联业务日志和错误日志
(3)监控看板关键指标
- 事务成功率 = 成功事务数 / 总事务数
- 平均执行时间 = 总执行时间 / 成功事务数
- 补偿失败率 = 补偿失败次数 / 总补偿次数
- 当前进行中事务数
3. TCC模式监控实现
(1)阶段状态监控
// 记录TCC各阶段状态
public class TccTransaction {
private String transactionId;
private Map<String, TccPhaseStatus> phaseStatuses; // 服务ID -> 阶段状态
public enum TccPhaseStatus {
TRYING, CONFIRMED, CANCELLED, FAILED
}
}
// 监控阶段状态变更
public class TccPhaseMonitor {
public void reportPhaseStatus(String transactionId, String serviceId, TccPhaseStatus status) {
// 上报到监控系统
monitoringService.reportTccPhaseStatus(transactionId, serviceId, status);
}
}
(2)资源锁定监控
- 监控Try阶段锁定的资源:
- 锁定资源数量
- 锁定时长
- 未释放的资源(可能泄漏)
- 设置资源超时告警:
- Try阶段超过阈值未进入Confirm/Cancel
(3)监控看板关键指标
- Try阶段成功率 = 成功进入Confirm的事务数 / 总Try事务数
- Confirm阶段成功率 = 成功确认的事务数 / 总Confirm事务数
- Cancel阶段成功率 = 成功取消的事务数 / 总Cancel事务数
- 当前锁定资源数
- 最长未释放资源时长
4. 统一监控方案
(1)监控系统集成
- 使用Prometheus + Grafana:
- 收集事务状态、耗时等指标
- 配置告警规则(如失败率超过阈值)
- 使用ELK日志系统:
- 收集事务执行日志
- 支持按事务ID查询完整执行链路
(2)告警机制
- Saga告警:
- 补偿失败告警
- 事务长时间未完成告警
- 补偿重试次数过多告警
- TCC告警:
- Try阶段长时间未确认告警
- Confirm/Cancel失败告警
- 资源锁定超时告警
(3)可视化看板
- 事务执行状态分布图
- 各阶段耗时统计
- 失败事务详情查询
- 资源锁定状态监控
5. 最佳实践建议
-
事务标识:
- 为每个Saga/TCC事务生成唯一ID
- 在所有日志和监控数据中携带该ID
-
状态上报:
- 每个服务在状态变更时主动上报监控系统
- 使用异步方式避免影响业务性能
-
告警分级:
- 关键失败(如资金操作失败)立即告警
- 非关键失败(如库存补偿失败)可延迟告警
-
根因分析:
- 记录完整的执行链路
- 支持从事务ID回溯所有操作步骤
-
定期报告:
- 生成每日/每周事务执行报告
- 分析失败模式和性能瓶颈
6. 技术选型建议
| 需求 | 推荐工具 |
|---|---|
| 分布式追踪 | Zipkin/SkyWalking/Jaeger |
| 指标收集 | Prometheus + Grafana |
| 日志收集 | ELK Stack (Elasticsearch+Logstash+Kibana) |
| 告警系统 | AlertManager/Prometheus Alertmanager |
| 可视化看板 | Grafana/Kibana |
通过以上方法,可以全面监控Saga和TCC事务的执行状态,及时发现和处理异常情况,保障分布式事务的可靠性。


















 4938
4938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









