




 本文详细介绍了CTC(Connectionist Temporal Classification)的概念,它是一种用于序列到序列学习的无序时间同步方法。CTC允许输入和输出序列在时间上不同步,并探讨了解码过程中的选项,如选择最可能的符号和外部约束。文章还讨论了在没有时间信息的情况下如何找到最佳对齐方式,以及如何通过前向和后向算法来计算概率。CTC训练过程中可能出现的问题,如重复解码问题,也得到了解决。
本文详细介绍了CTC(Connectionist Temporal Classification)的概念,它是一种用于序列到序列学习的无序时间同步方法。CTC允许输入和输出序列在时间上不同步,并探讨了解码过程中的选项,如选择最可能的符号和外部约束。文章还讨论了在没有时间信息的情况下如何找到最佳对齐方式,以及如何通过前向和后向算法来计算概率。CTC训练过程中可能出现的问题,如重复解码问题,也得到了解决。
Sequence to sequence
- Sequence goes in, sequence comes out
- No notion of “time synchrony” between input and output
- May even nots maintain order of symbols (from one language to another)
With order synchrony
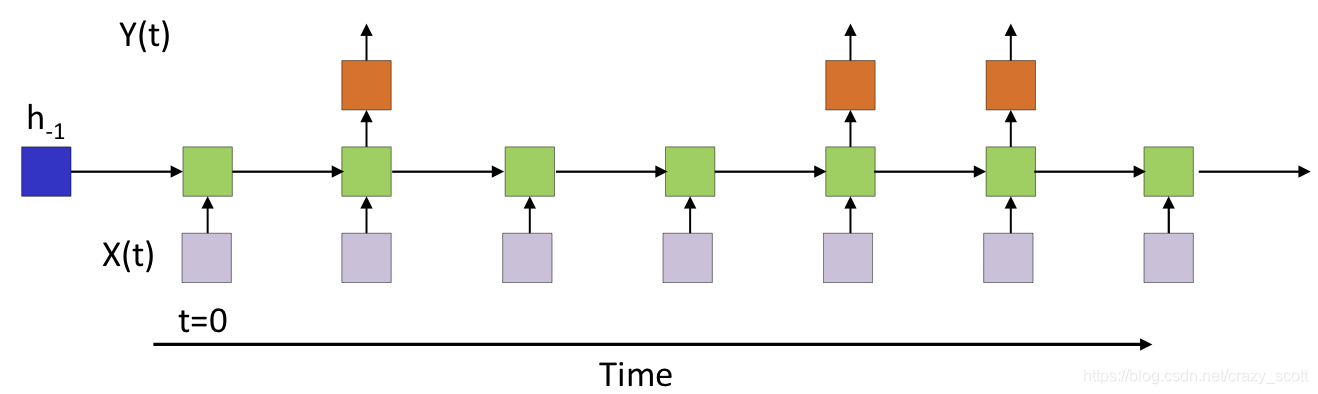
- The input and output sequences happen in the same order
- Although they may be time asynchronous
- E.g. Speech recognition
- The input speech corresponds to the phoneme sequence output
- Question
- How do we know when to output symbols
- In fact, the network produces outputs at every time
- Which of these are the real outputs?
Option 1
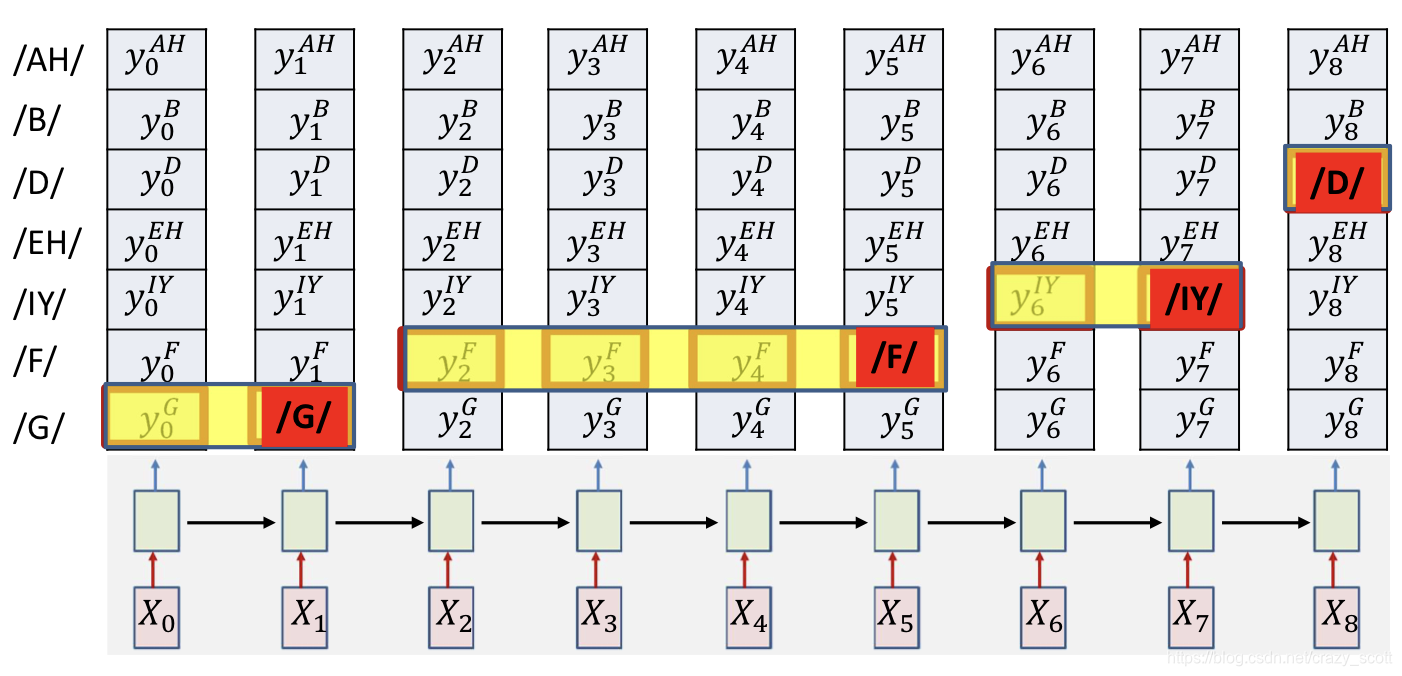
- Simply select the most probable symbol at each time
- Merge adjacent repeated symbols, and place the actual emission of the symbol in the final instant
- Problem
- Cannot distinguish between an extended symbol and repetitions of the symbol
- Resulting sequence may be meaningless
Option 2
- Impose external constraints on what sequences are allowed
- E.g. only allow sequences corresponding to dictionary words
Decoding
-
The process of obtaining an output from the network
-
Time-synchronous & order-synchronous sequence
-
aaabbbbbbccc => abc (probility 0.5) aabbbbbbbccc => abc (probility 0.001) cccddddddeee => cde (probility 0.4) cccddddeeeee => cde (probility 0.4) - So abc is the most likely time-synchronous output sequence
- But cde is the the most likely order-synchronous sequence
-
-
Option 2 is in fact a suboptimal decode that actually finds the most likely time-synchronous output sequence
-
The “merging” heuristics do not guarantee optimal order-synchronous sequences
No timing information provided
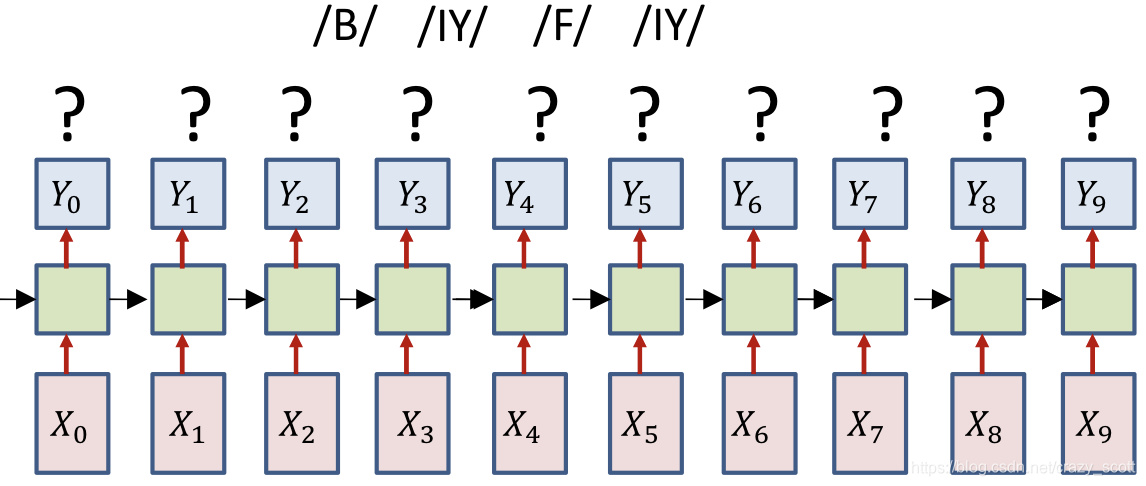
- Only the sequence of output symbols is provided for the training data
- But no indication of which one occurs where
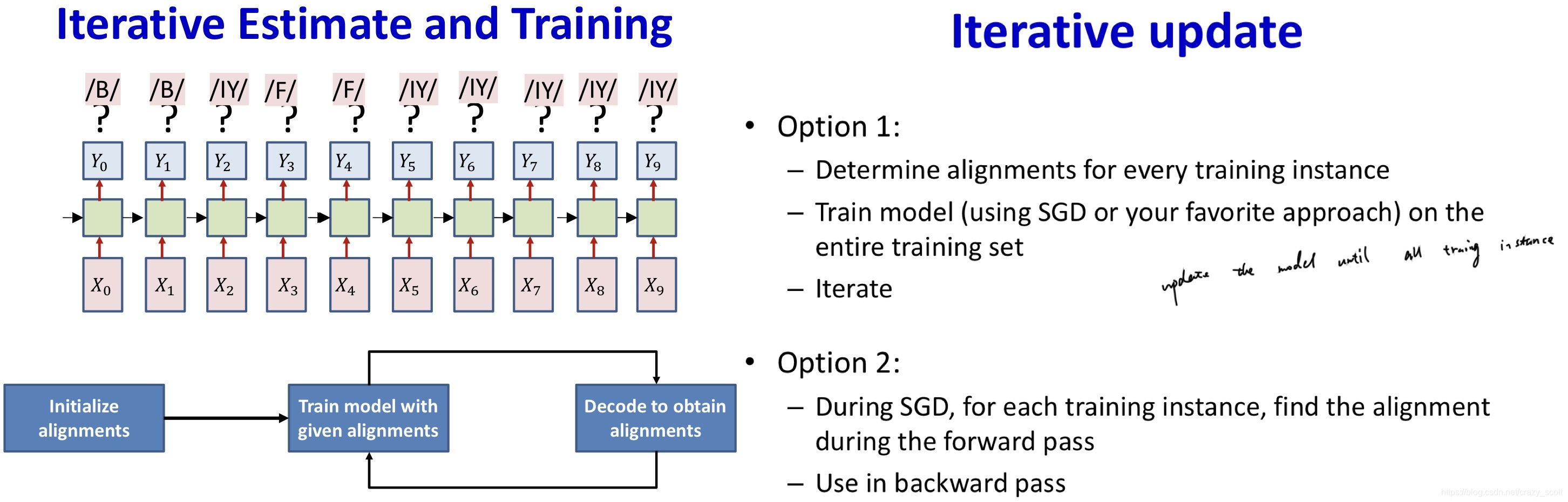
Guess the alignment
- Initialize
- Assign an initial alignment
- Either randomly, based on some heuristic, or any other rationale
- Iterate
- Train the network using the current alignment
- Reestimate the alignment for each training instance
Constraining the alignment
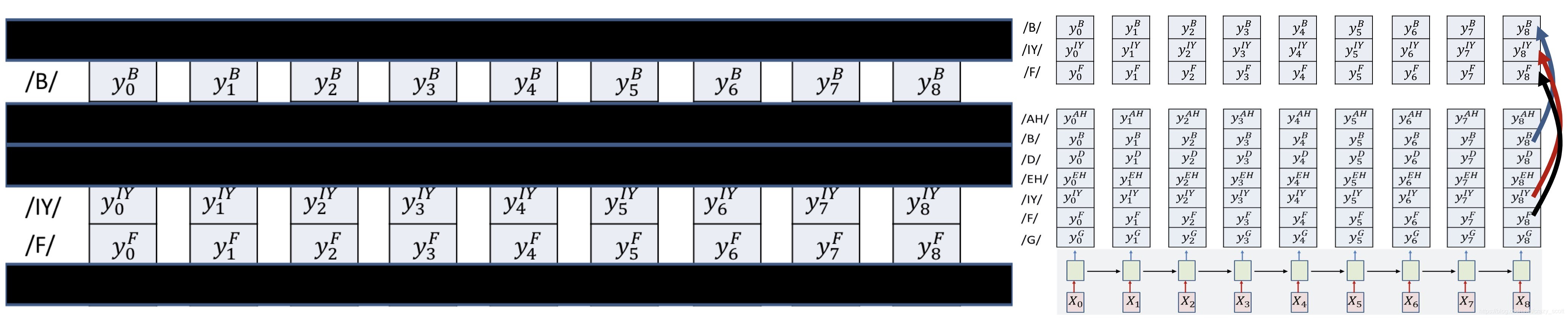
- Try 1
- Block out all rows that do not include symbols from the target sequence
- E.g. Block out rows that are not /B/ /IY/ or /F/
- Only decode on reduced grid
- We are now assured that only the appropriate symbols will be hypothesized
- But this still doesn’t assure that the decode sequence correctly expands the target symbol sequence
- Order variance
- Try 2
- Explicitly arrange the constructed table
- Arrange the constructed table so that from top to bottom it has the exact sequence of symbols required
- If a symbol occurs multiple times, we repeat the row in the appropriate location

-
Constrain that the first symbol in the decode must be the top left block
- The last symbol must be the bottom right
- The rest of the symbols must follow a sequence that monotonically travels down from top left to bottom right
- This guarantees that the sequence is an expansion of the target sequence
-
Compose a graph such that every path in the graph from source to sink represents a valid alignment
- The “score” of a path is the product of the probabilities of all nodes along the path
- Find the most probable path from source to sink using any dynamic programming algorithm (viterbi algorithm)
Viterbi algorithm
-
Main idea
- The best path to any node must be an extension of the best path to one of its parent nodes
-
Dynamically track the best path (and the score of the best path) from the source node to every node in the graph
- At each node, keep track of
- The best incoming parent edge (BP)
- The score of the best path from the source to the node through this best parent edge (Bscr)
- At each node, keep track of
-
Process

-
Algorithm

Gradients
D I V = ∑ t X e n t ( Y t , s y m b o l t b e s t p a t h ) = − ∑ t log Y ( t , s y m b o l t b e s t p a t h ) D I V=\sum_{t} X e n t\left(Y_{t}, s y m b o l_{t}^{b e s t p a t h}\right)=-\sum_{t} \log Y\left(t, s y m b o l_{t}^{b e s t p a t h}\right) DIV=t∑Xent(Yt,symboltbestpath)=−t∑logY(t,symboltbestpath)
- The gradient w.r.t the -th output vector Y t Y_t Yt
∇ Y t D I V = [ 0 0 ⋅ ⋅ ⋅ − 1 Y ( t , s y m b o l t b e s t p a t h ) 0 ⋅ ⋅ ⋅ 0 ] \nabla_{Y_{t}} D I V=[0 \quad 0 \cdot \cdot \cdot \frac{-1}{Y(t, s y m b o l_{t}^{b e s t p a t h})} \quad 0 \cdot \cdot \cdot 0] ∇YtDIV=[00⋅⋅⋅Y(t,symboltbestpath)−10⋅⋅⋅0]
-
Problem
- Approach heavily dependent on initial alignment
- Prone to poor local optima
- Because we commit to the single “best” estimated alignment
- This can be way off, particularly in early iterations, or if the model is poorly initialized
-
Alternate view
- There is a probability distribution over alignments of the target Symbol sequence (to the input)
- Selecting a single alignment is the same as drawing a single sample from it
-
Instead of only selecting the most likely alignment, use the statistical expectation over all possible alignments
-
D I V = E [ − ∑ t log Y ( t , s t ) ] D I V=E\left[-\sum_{t} \log Y\left(t, s_{t}\right)\right] DIV=E[−t∑logY(t,st)]
-
Use the entire distribution of alignments
-
This will mitigate the issue of suboptimal selection of alignment
-
-
Using the linearity of expectation
-
D I V = − ∑ t E [ log Y ( t , s t ) ] D I V=-\sum_{t} E\left[\log Y\left(t, s_{t}\right)\right] DIV=−t∑E[logY(t,st)]
-
D I V = − ∑ t ∑ S ∈ S 1 … S K P ( s t = S ∣ S , X ) log Y ( t , s t = S ) D I V=-\sum_{t} \sum_{S \in S_{1} \ldots S_{K}} P\left(s_{t}=S | \mathbf{S}, \mathbf{X}\right) \log Y\left(t, s_{t}=S\right) DIV=−t∑S∈S1…SK∑P(st=S∣S,X)logY(t,st=S)
-
A posteriori probabilities of symbols
-
P ( s t = S ∣ S , X ) P(s_{t}=S | \mathbf{S}, \mathbf{X}) P(st=S∣S,X) is the probability of seeing the specific symbol s s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









