




 本文介绍了RNN的不同架构,包括一对一、多对多和序列到序列模型。重点讨论了语言建模中单词的表示,以及如何在不同设置下训练RNN。在多对多模型中,计算的发散是网络输出序列与期望输出序列之间的差异。在序列到序列模型中,如何确定何时输出符号成为挑战,提出了两种可能的解决方案:选择最可能的符号或外部约束输出序列。
本文介绍了RNN的不同架构,包括一对一、多对多和序列到序列模型。重点讨论了语言建模中单词的表示,以及如何在不同设置下训练RNN。在多对多模型中,计算的发散是网络输出序列与期望输出序列之间的差异。在序列到序列模型中,如何确定何时输出符号成为挑战,提出了两种可能的解决方案:选择最可能的符号或外部约束输出序列。
Variants on recurrent nets
- Architectures
- How to train recurrent networks of different architectures
- Synchrony
- The target output is time-synchronous with the input
- The target output is order-synchronous, but not time synchronous
One to one
-
No recurrence in model
- Exactly as many outputs as inputs
- One to one correspondence between desired output and actual output
-
Common assumption
∇Y(t)Div(Ytarget(1…T),Y(1…T))=wt∇Y(t)Div(Ytarget(t),Y(t)) \nabla_{Y(t)} \operatorname{Div}\left(Y_{\text {target}}(1 \ldots T), Y(1 \ldots T)\right)=w_{t} \nabla_{Y(t)} \operatorname{Div}\left(Y_{\text {target}}(t), Y(t)\right) ∇Y(t)Div(Ytarget(1…T),Y(1…T))=wt∇Y(t)Div(Ytarget(t),Y(t))- wtw_twt is typically set to 1.0
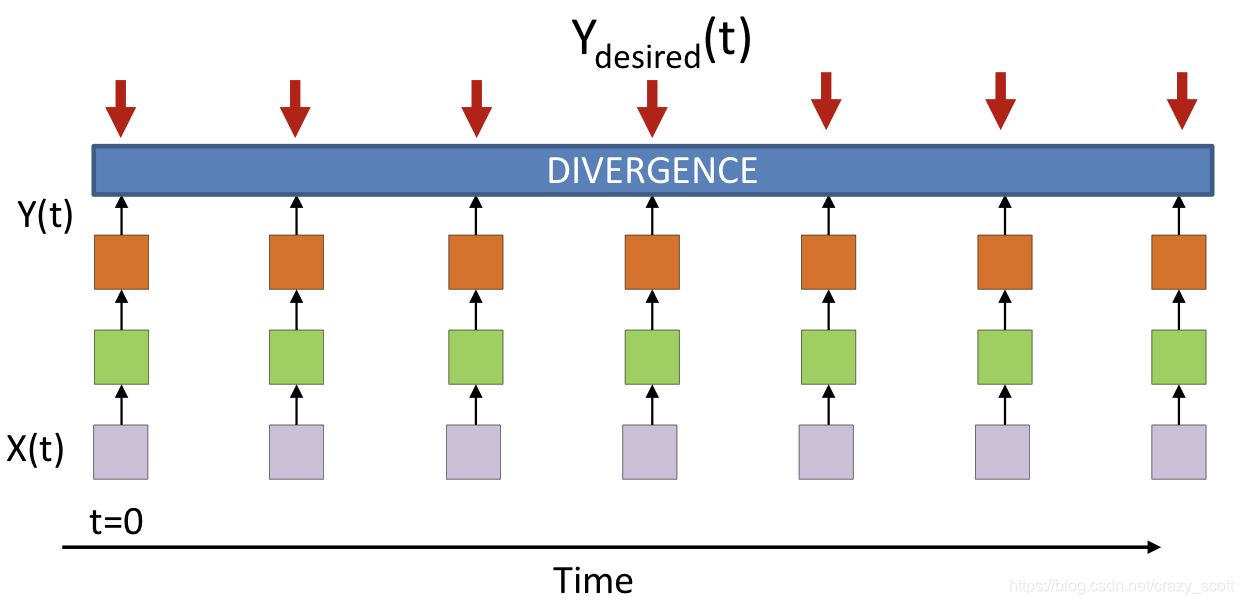
Many to many
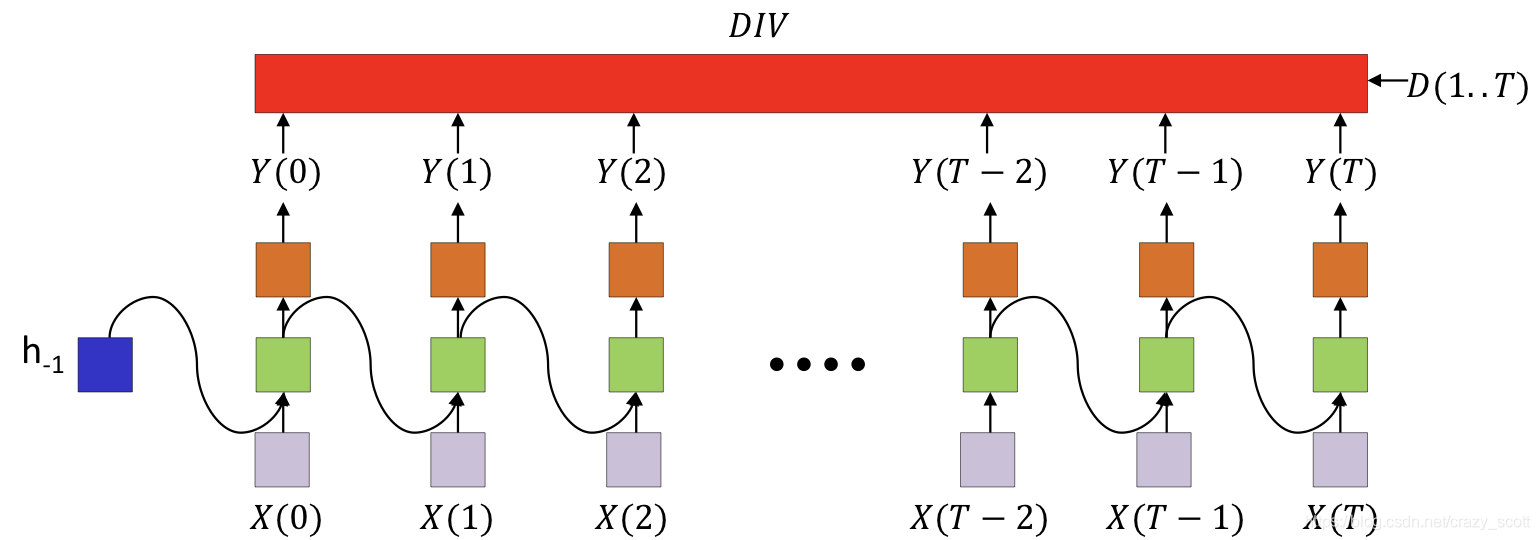
- The divergence computed is between the sequence of outputs by the network and the desired sequence of outputs
- This is not just the sum of the divergences at individual times
Language modelling: Representing words
-
Represent words as one-hot vectors
- Sparse problem
- Makes no assumptions about the relative importance of words
-
The Projected word vectors
- Replace every one-hot vector WiW_iWi by PWiPW_iPWi
- PPP is an M×NM\times NM×N matrix
-
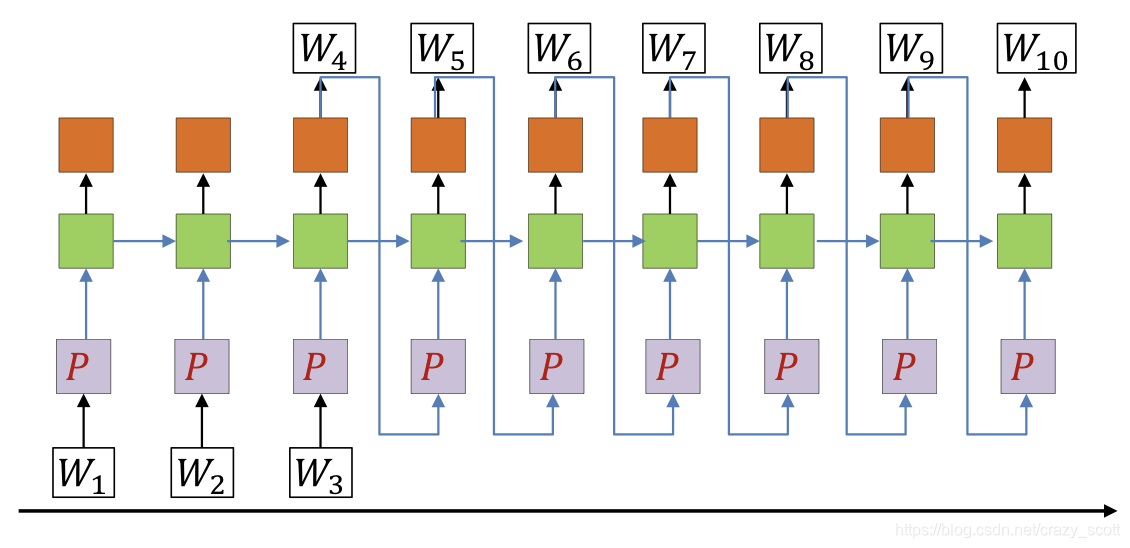
How to learn projections
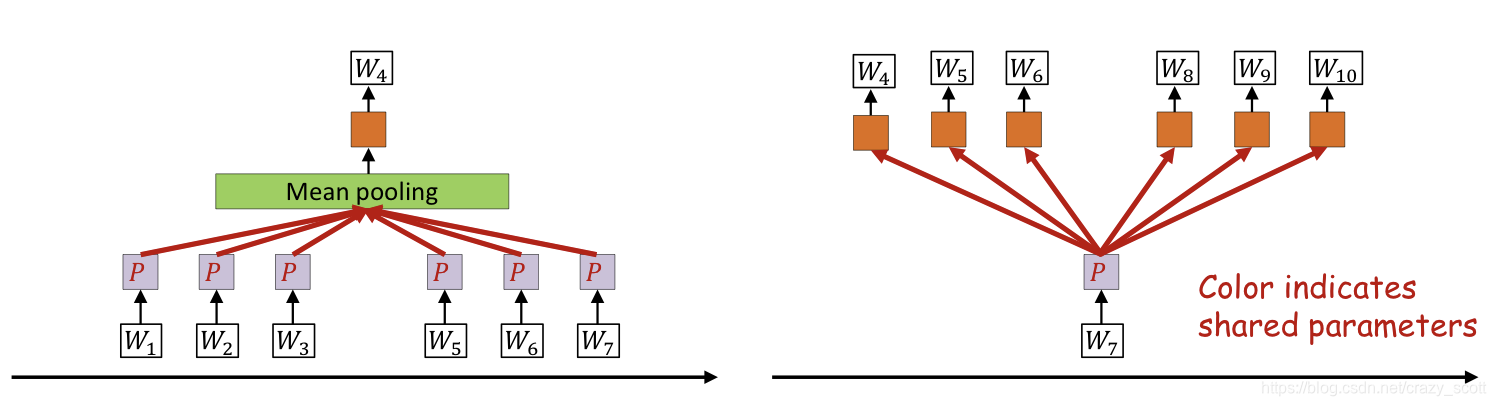
- Soft bag of words
- Predict word based on words in immediate context
- Without considering specific position
- Skip-grams
- Predict adjacent words based on current word
Many to one
- Example
- Question answering
- Input : Sequence of words
- Output: Answer at the end of the question
- Speech recognition
- Input : Sequence of feature vectors (e.g. Mel spectra)
- Output: Phoneme ID at the end of the sequence
- Question answering
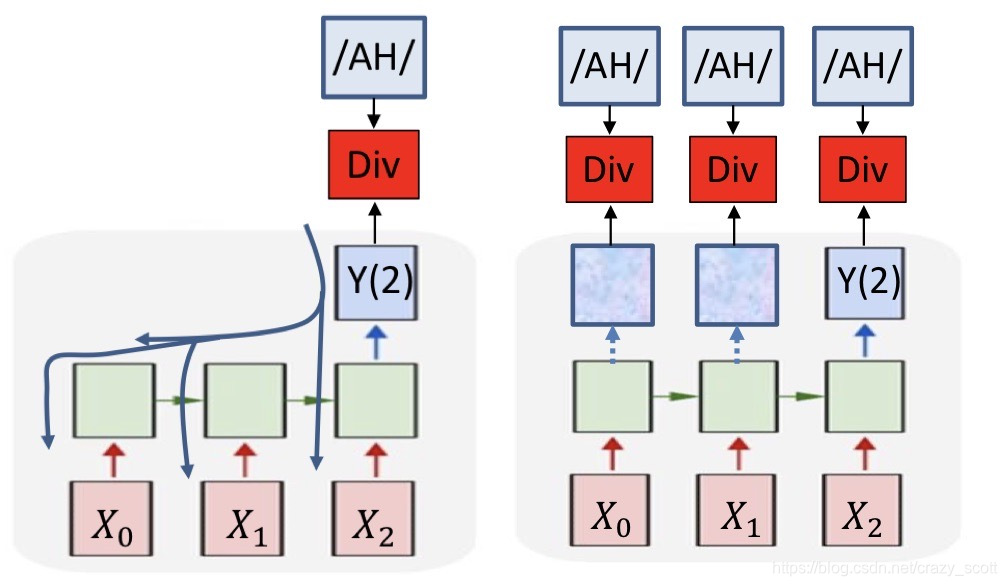
-
Outputs are actually produced for every input
- We only read it at the end of the sequence
-
How to train
- Define the divergence everywhere
- DIV(Ytarget,Y)=∑twtXent(Y(t), Phoneme)D I V\left(Y_{\text {target}}, Y\right)=\sum_{t} w_{t} \operatorname{Xent}(Y(t), \text { Phoneme})DIV(Ytarget,Y)=∑twtXent(Y(t), Phoneme)
- Typical weighting scheme for speech
- All are equally important
- Problem like question answering
- Answer only expected after the question ends
- Define the divergence everywhere
Sequence-to-sequence
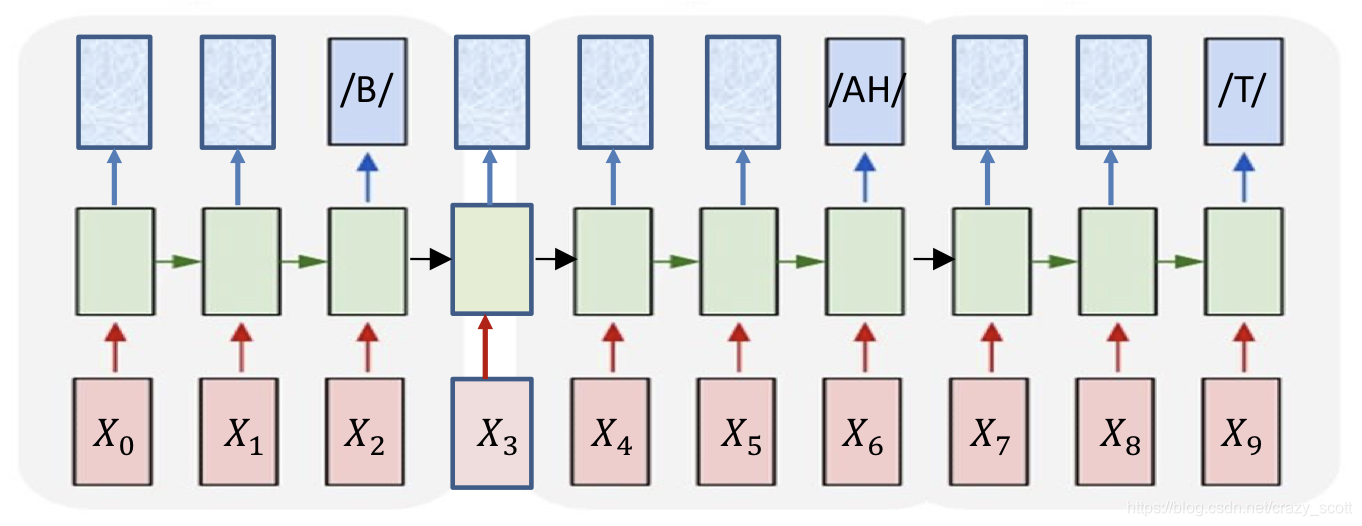
- How do we know when to output symbols
- In fact, the network produces outputs at every time
- Which of these are the real outputs
- Outputs that represent the definitive occurrence of a symbol
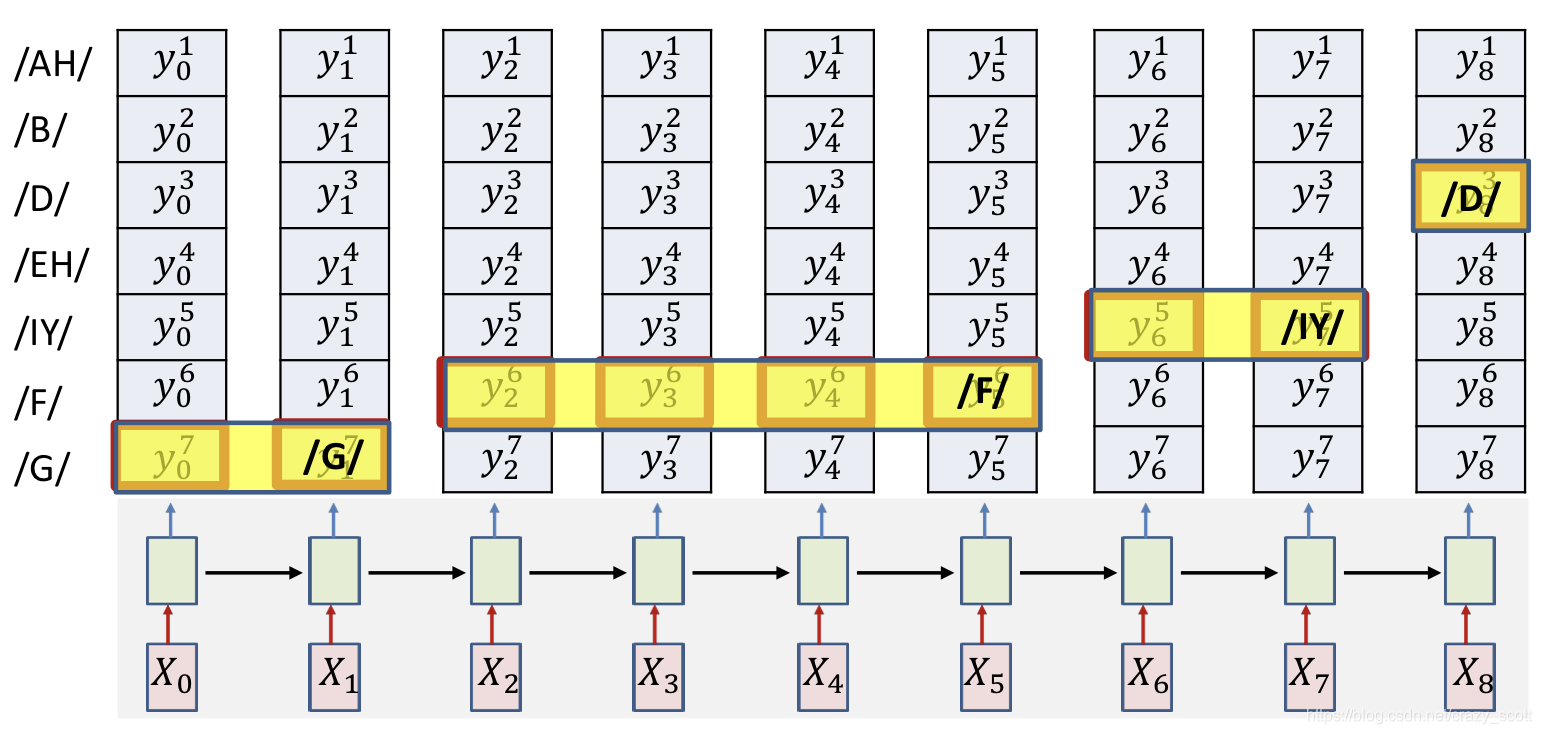
- Option 1: Simply select the most probable symbol at each time
- Merge adjacent repeated symbols, and place the actual emission of the symbol in the final instant
- Cannot distinguish between an extended symbol and repetitions of the symbol
- Resulting sequence may be meaningless
- Option 2: Impose external constraints on what sequences are allowed
- Only allow sequences corresponding to dictionary words
- Sub-symbol units
- How to train when no timing information provided
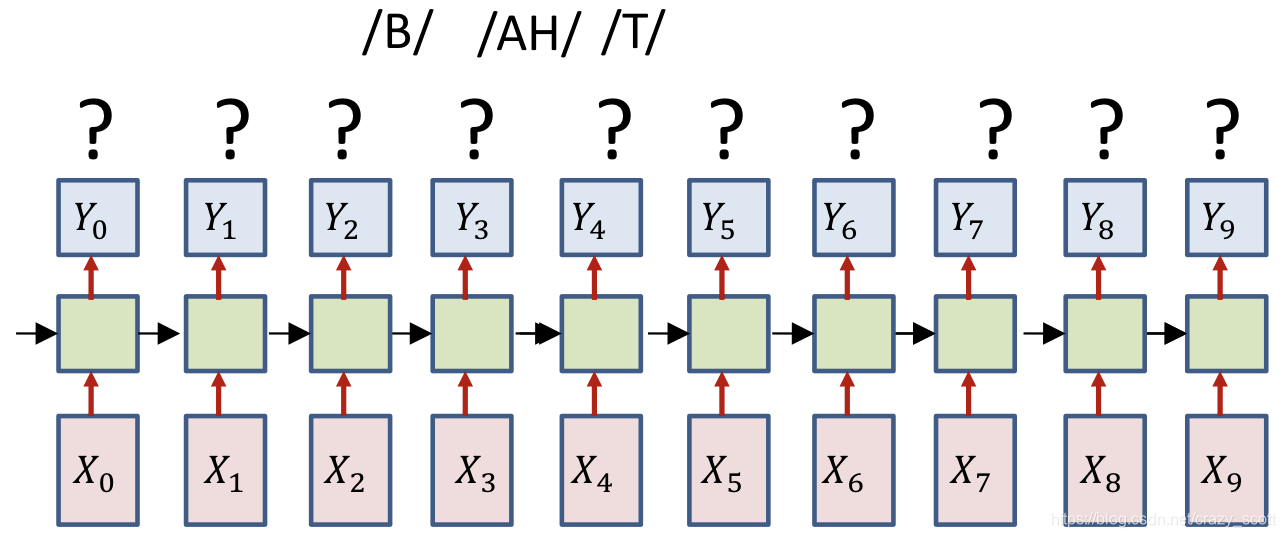
- Only the sequence of output symbols is provided for the training data
- But no indication of which one occurs where
- How do we compute the divergence?
- And how do we compute its gradient

















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









