




 这篇博客介绍了导数的概念,它揭示了函数微小变化如何影响输出。讨论了多元标量函数的偏导数,并解释了梯度如何表示函数增量。在优化方面,讨论了单变量和多变量函数的临界点,梯度方向与函数增益的关系,以及无约束最小化问题中使用Hessian矩阵判断局部极值的方法。最后,提到了梯度下降法在凸函数和非凸函数上的收敛性质。
这篇博客介绍了导数的概念,它揭示了函数微小变化如何影响输出。讨论了多元标量函数的偏导数,并解释了梯度如何表示函数增量。在优化方面,讨论了单变量和多变量函数的临界点,梯度方向与函数增益的关系,以及无约束最小化问题中使用Hessian矩阵判断局部极值的方法。最后,提到了梯度下降法在凸函数和非凸函数上的收敛性质。
What is derivatives?
- A derivative of a function at any point tells us how much a minute increment to the argument of the function will increment the value of the function
To be clear, what we want is not differentiable, but how the change effects the outputs.
- Based on the fact that at a fine enough resolution, any smooth, continuous function is locally linear at any point. So we can express like this
Δy=αΔx \Delta y=\alpha \Delta x Δy=αΔx
Multivariate scalar function
Δy=α1Δx1+α2Δx2+⋯+αDΔxD \Delta y=\alpha_{1} \Delta x_{1}+\alpha_{2} \Delta x_{2}+\cdots+\alpha_{D} \Delta x_{D} Δy=α1Δx1+α2Δx2+⋯+αDΔxD
-
The partial derivative αi\alpha_iαi gives us how yyy increments when only xix_ixi is incremented
-
It can be expressed as:
Δy=∇xyΔx \Delta y=\nabla_{x} y \Delta x Δy=∇xyΔx -
where
∇xy=[∂y∂x1⋯∂y∂xD] \nabla_{\mathrm{x}} y=\left[\frac{\partial y}{\partial x_{1}} \quad \cdots \quad \frac{\partial y}{\partial x_{D}}\right] ∇xy=[∂x1∂y⋯∂xD∂y]
Optimization
Single variable
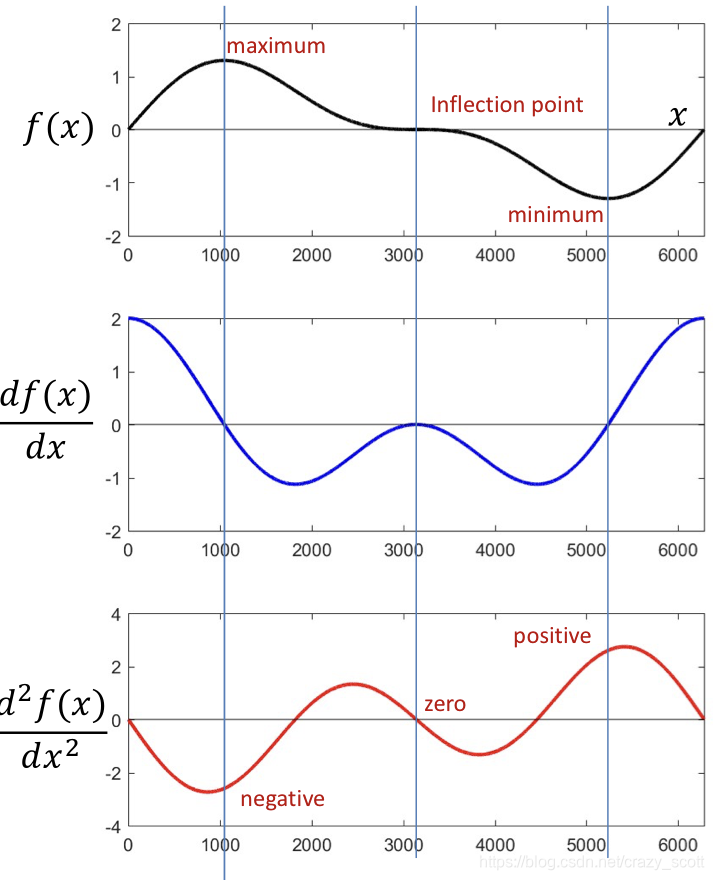
- Three different critical point with zero derivative
- The second derivative is
- ≥0\ge 0≥0 at minima
- ≤0\le 0≤0 at maxima
- =0=0=0 at inflection points
multiple variables
df(X)=∇Xf(X)dX d f(X)=\nabla_{X} f(X) d X df(X)=∇Xf(X)dX
-
The gradient is the transpose of the derivative ∇Xf(X)T\nabla_{X} f(X)^{T}∇Xf(X)T(give us the change in f(x)f(x)f(x) for tiny variations in XXX)
-
This is a vector inner product
- df(x)d f(x)df(x) is max if dXdXdX is aligned with ∇Xf(X)T\nabla_{X} f(X)^{\mathrm{T}}∇Xf(X)T
- ∠(∇Xf(X)T,dX)=0\angle\left(\nabla_{X} f(X)^{\mathrm{T}}, d X\right)=0∠(∇Xf(X)T,dX)=0
-
The gradient is the direction of fastest increase in f(x)f(x)f(x)
-
Hessian
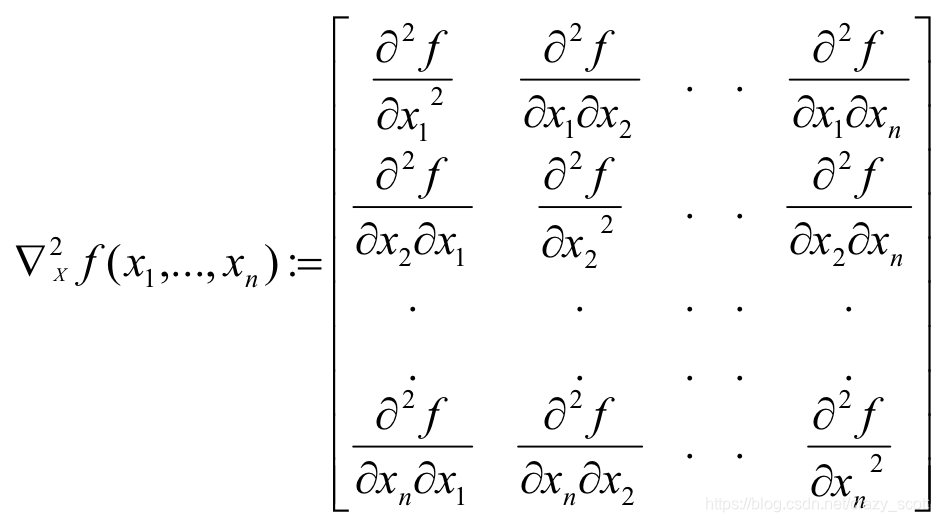
Unconstrained Minimization of function
- Solve for ZZZ where the derivative equals to zero:
∇Xf(X)=0 \nabla_{X} f(X)=0 ∇Xf(X)=0
- Compute the Hessian Matrix at the candidate solution and verify that
- Hessian is positive definite (eigenvalues positive) -> to identify local minima
- Hessian is negative definite (eigenvalues negative) -> to identify local maxima
Closed form are not available
- To find a maximum move in the direction of the gradient
xk+1=xk+ηk∇xf(xk)T x^{k+1}=x^{k}+\eta^{k} \nabla_{x} f\left(x^{k}\right)^{T} xk+1=xk+ηk∇xf(xk)T
- To find a minimum move exactly opposite the direction of the gradient
xk+1=xk−ηk∇xf(xk)T x^{k+1}=x^{k}-\eta^{k} \nabla_{x} f\left(x^{k}\right)^{T} xk+1=xk−ηk∇xf(xk)T
- Choose steps
- fixed step size
- iteration-dependent step size: critical for fast optimization
Convergence
- For convex functions
- gradient descent will always find the minimum.
- For non-convex functions
- it will find a local minimum or an inflection point

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









