





 本文深入解析泰勒公式,探讨其在数学和物理领域的应用。泰勒公式能够利用函数的各阶导数构建高次多项式,近似描述函数在某点附近的取值,特别适用于变量为一维或多维的情形。此外,文章还阐述了泰勒公式与梯度下降法之间的联系,展示如何通过泰勒展开找到函数的最小值。
本文深入解析泰勒公式,探讨其在数学和物理领域的应用。泰勒公式能够利用函数的各阶导数构建高次多项式,近似描述函数在某点附近的取值,特别适用于变量为一维或多维的情形。此外,文章还阐述了泰勒公式与梯度下降法之间的联系,展示如何通过泰勒展开找到函数的最小值。
什么是泰勒公式
百度百科中的解释
泰勒公式,应用于数学、物理领域,是一个用函数在某点的信息描述其附近取值的公式。如果函数足够平滑的话,在已知函数在某一点的各阶导数值的情况之下,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数在这一点的邻域中的值。
说白了,泰勒公式就是:可以使用函数在某点的各阶导数组成高次多项式去逼近一个函数。
泰勒公式表示为:
h
(
x
)
=
∑
k
=
0
∞
h
(
k
)
(
x
0
)
k
!
(
x
−
x
0
)
k
\mathrm{h}(\mathrm{x})=\sum_{k=0}^{\infty} \frac{\mathrm{h}^{(k)}\left(x_{0}\right)}{k !}\left(x-x_{0}\right)^{k}
h(x)=k=0∑∞k!h(k)(x0)(x−x0)k将泰勒公式展开:
h
(
x
)
=
∑
k
=
0
∞
h
(
k
)
(
x
0
)
k
!
(
x
−
x
0
)
k
=
h
(
x
0
)
+
h
′
(
x
0
)
(
x
−
x
0
)
+
h
′
′
(
x
0
)
2
!
(
x
−
x
0
)
2
+
…
\begin{aligned} \mathrm{h}(\mathrm{x}) &=\sum_{k=0}^{\infty} \frac{\mathrm{h}^{(k)}\left(x_{0}\right)}{k !}\left(x-x_{0}\right)^{k} \\ &=h\left(x_{0}\right)+h^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)+\frac{h^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots \end{aligned}
h(x)=k=0∑∞k!h(k)(x0)(x−x0)k=h(x0)+h′(x0)(x−x0)+2!h′′(x0)(x−x0)2+…同时,如果
x
x
x 很接近
x
0
x_0
x0,也就是逼近的范围足够小的话,上面的公式可以只取前两项:
h
(
x
)
≈
h
(
x
0
)
+
h
′
(
x
0
)
(
x
−
x
0
)
h(x) \approx h\left(x_{0}\right)+h^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)
h(x)≈h(x0)+h′(x0)(x−x0)上面的公式是变量为一维的时候得出的,对于多维变量,只不过将求导改为分别求偏导即可。
泰勒公式和梯度下降的关系
想象一下在多维空间中有下面的图像(它的函数
L
(
θ
)
L(\boldsymbol \theta)
L(θ)自变量为
θ
1
\theta_1
θ1 和
θ
2
\theta_2
θ2),从红色到紫色表示海拔越来越低,那么任取空间中一个点
θ
0
\theta_0
θ0 后,每次移动一步,如何才能更快的到达谷底。

为了方便用公式推导出最速下降的关系,可以设定每次在极小的范围内移动一步,因此就可以将
L
(
θ
)
L(\boldsymbol \theta)
L(θ) 用泰勒展开来逼近。将走这一小步到达的点记为
(
a
,
b
)
\left(a,b\right)
(a,b),则有泰勒展开如下:
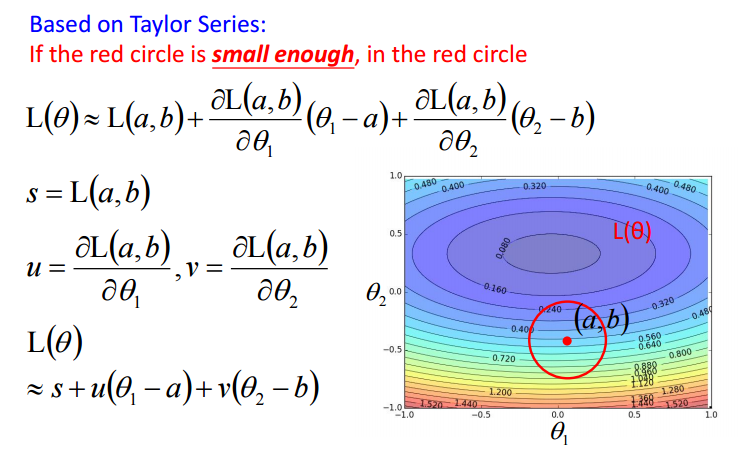
上面的式子即被简化成了:
L
(
θ
)
≈
s
+
u
(
θ
1
−
a
)
+
v
(
θ
2
−
b
)
\begin{array}{l}{\mathrm{L}(\theta)}{\approx s+u\left(\theta_{1}-a\right)+v\left(\theta_{2}-b\right)}\end{array}
L(θ)≈s+u(θ1−a)+v(θ2−b)因为
s
s
s 是一个定值,只与输入有关,因此不去看它,只考虑
u
(
θ
1
−
a
)
+
v
(
θ
2
−
b
)
u\left(\theta_{1}-a\right)+v\left(\theta_{2}-b\right)
u(θ1−a)+v(θ2−b).
将
u
u
u 与
v
v
v 合在一起作为一个向量
∇
w
f
(
x
)
\nabla_{w}f(x)
∇wf(x)(这其实就是对所有变量分别求偏导的集合),将
(
θ
1
−
a
)
\left(\theta_{1}-a\right)
(θ1−a)与
(
θ
2
−
b
)
\left(\theta_{2}-b\right)
(θ2−b)作为另外一个向量
u
\boldsymbol u
u(距离尽可能小,可以视为单位向量),想让
L
(
θ
)
L(\boldsymbol \theta)
L(θ)最小,也即让两个向量的点积最小,也就是:
min
u
⊤
∇
x
f
(
x
)
=
min
∥
u
∥
2
∥
∇
x
f
(
x
)
∥
2
cos
θ
\min\boldsymbol{u}^{\top} \nabla_{\boldsymbol{x}} f(\boldsymbol{x}) \\ = \min \|\boldsymbol{u}\|_{2}\left\|\nabla_{\boldsymbol{x}} f(\boldsymbol{x})\right\|_{2} \cos \theta
minu⊤∇xf(x)=min∥u∥2∥∇xf(x)∥2cosθ想让上面的式子取最小值,很显然要令两个向量方向相反,也就是:下降的方向与梯度方向相反。


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









