




 该文描述了一个处理从知网下载的PDF文献的过程,首先将PDF转换为TXT文件,然后使用jieba分词库对TXT内容进行分析,特别是针对中医相关词汇的词频统计,最后将结果输出到dictdata.xls文件中。
该文描述了一个处理从知网下载的PDF文献的过程,首先将PDF转换为TXT文件,然后使用jieba分词库对TXT内容进行分析,特别是针对中医相关词汇的词频统计,最后将结果输出到dictdata.xls文件中。
一、目标:拿到一堆PDF文件(从知网下的文献),将文件中的内容读取并且统计与中医相关的词频。
数据如图:
二、将PDF转换成txt文件
import pdfplumber as pb
import os
# os.listdir()方法获取文件夹名字,返回数组
def getAllFiles(targetDir):
listFiles = os.listdir(targetDir)
return listFiles
files = getAllFiles(r"E:\data001")
# 写入list到txt文件中
with open(r"test.txt",'w+',encoding='utf-8')as f:
# 列表生成式
f.writelines(["'"+str(i)+"',\n" for i in files])
print(files[0])
for j in range(0,len(files)):
file_handle = open("E:\\dat\\"+str(files[j])+'.txt', mode='w', encoding='utf-8')
# 读取PDF文档
pdf = pb.open("E:\\data001\\"+str(files[j]))
# 绝对路径也可以这么写,下同
# 获取页数
a = len(pdf.pages)
print("当前页:", a)
i = 0
for i in range(0, a):
first_page = pdf.pages[i]
print("本页:", first_page.page_number)
print("-----------------------------------------")
# 导出当前页文本
text = first_page.extract_text()
# print(text)
file_handle.write(text)
print('已完成篇数:',j+1,files[j])
三、读取转换成功的txt的内容
import os
# os.listdir()方法获取文件夹名字,返回数组
def getAllFiles(targetDir):
listFiles = os.listdir(targetDir)
return listFiles
files = getAllFiles(r"E:\dat")
# 写入list到txt文件中
with open(r"test.txt",'w+',encoding='utf-8')as f:
# 列表生成式
f.writelines(["'"+str(i)+"',\n" for i in files])
print(files[0])
data11=[]
for n in range(0,len(files)):
for line in open(files[n],'w+',encoding='utf-8'):
data11.append(line)
print(len(data11))
四、对txt内容进行分析
此处主要使用了jieba分词库
import os
import jieba
data11 = []
path = 'E:\\dat'
for file in os.listdir(path):
data11.append(file)
dict5={}
dict7={}
dict6 = {}
jieba.load_userdict('E:/TCM_Syndrome.txt')
for i in range(0,len(data11)):
txt = open('E:/dat/'+str(data11[i]), 'r', encoding='utf-8').read()
#words = jieba.lcut(txt)
#words= jieba.cut(txt)
words = jieba.cut(txt, cut_all=False, HMM=True)
count1 = {}
#print(txt)
for i in words:
if len(i)>2 and len(i)<7:
# a = 1
#else:
count1[i] = count1.get(i, 0) + 1
li1 = count1.items()
# print(count1)
li1 = sorted(li1, key=lambda x: x[1], reverse=True)
dict5 = dict(li1)
#print(dict5)
for key in dict5:
dict6[key]=dict5[key]+dict7.get(key,0)
dict7=dict6
li2 = sorted(dict6.items(), key=lambda x: x[1], reverse=True)
#print(li2)
output = open('E:\data10\dictdata.xls','w',encoding='gbk')
output.write('char\tnumber\n')
for i in range(len(li2)):
for j in range(len(li2[i])):
output.write(str(li2[i][j])) #write函数不能写int类型的参数,所以使用str()转化
output.write('\t') #相当于Tab一下,换一个单元格
output.write('\n') #写完一行立马换行
output.close()
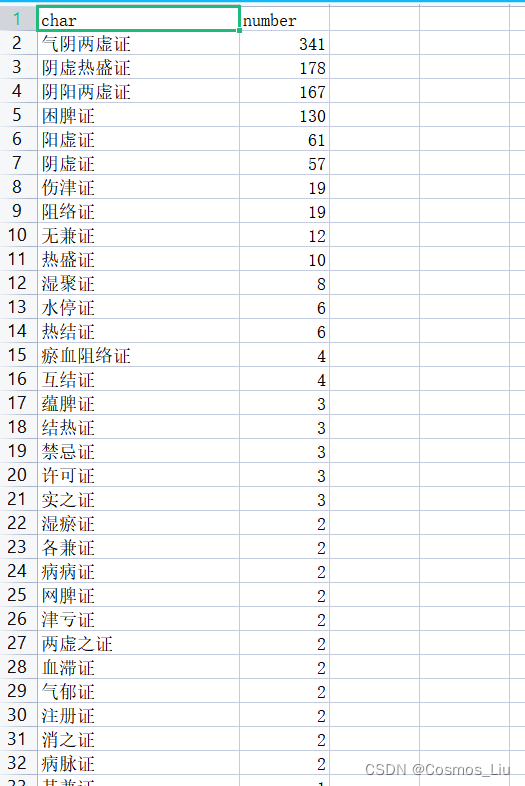
得到的有关的词频统计结果如下:

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









