






目录
前言
在人工智能应用中,如何让机器更智能地理解和生成文本,已经成为了科研与工程实践中的一个关键挑战。特别是在大规模信息检索和问答系统中,如何高效地从海量文档中找到最相关的信息,一直是技术的难点之一。近年来,基于Retriever-Generator (RAG) 结构的模型,逐渐成为了一种主流的解决方案。在这个架构中,Retriever 负责从大量的知识库中检索出相关信息,而生成模型则基于这些信息生成精确的答案。
本文将详细介绍 RAG 中的 Retriever 组件,分析其工作原理、实现方式以及如何通过优化向量数据库来提升检索效率。我们还将深入探讨各种向量检索策略的优缺点,帮助开发者在实际应用中选择最适合的方案。
1. 什么是 RAG 和 Retriever?
1.1 RAG 结构概述
RAG 是一种结合了信息检索与生成模型的框架。具体来说,它由两大组件组成:
- Retriever:负责从知识库中检索出与用户问题相关的文档或片段。
- Generator:基于 Retriever 提供的上下文,生成最终的答案。
RAG 的优势在于它能够通过结合现有的文档知识来提升生成模型的性能,使其不仅能生成自然语言的回答,还能根据实际知识库中的信息进行回答。
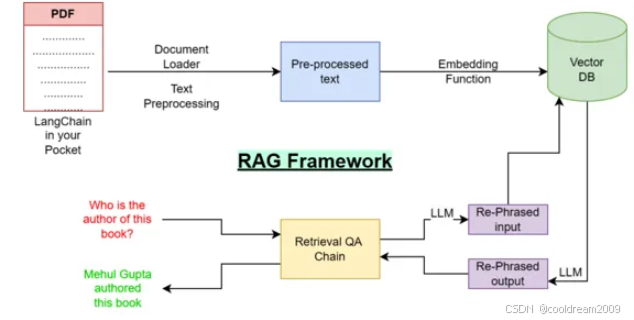
1.2 Retriever 的职责
在 RAG 框架中,Retriever 主要有以下几个职责:
- 接收用户问题的向量表示:用户输入的自然语言问题会被转换为向量表示,这个过程通常通过嵌入模型(如 BERT 或 GPT)完成。
- 检索相关文档:Retriever 会根据用户问题的向量表示,从向量数据库中查找出最相似的文档片段。一般情况下,Retriever 会返回前 N 条相关文档,常见的是 Top-K 文档。
- 返回最相似的文档:根据查找到的文档片段,Retriever 会将它们作为上下文传递给生成模型,帮助模型生成更加精准的答案。
可以把 Retriever 看作是“AI 图书管理员”,它在用户提出问题时,从知识库中找到最相关的文档片段,为生成模型提供必要的上下文。
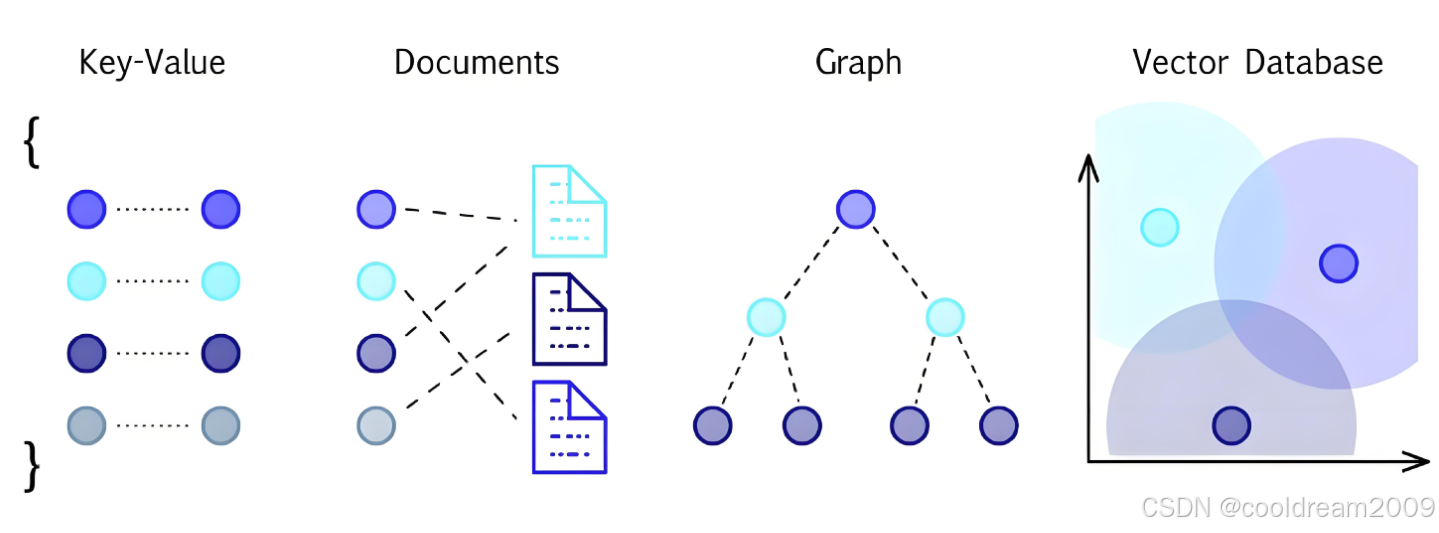
2. 向量数据库:存储与检索的核心
2.1 向量数据库的功能
为了让 Retriever 高效地完成文档检索,向量数据库扮演着至关重要的角色。向量数据库的主要功能包括:
- 存储文档的向量表示:向量数据库可以存储经过嵌入模型处理后的文档向量,通常这些向量是高维的,例如 1536 维或者 768 维。
- 检索相似向量:向量数据库能够根据查询向量,找到最相似的文档向量。这一检索过程通常基于距离度量,如余弦相似度或欧氏距离。
2.2 常用的向量数据库工具
目前,市面上有多种向量数据库工具,它们各有特点,适用于不同的应用场景。以下是一些常用的向量数据库及其特点:
| 名称 | 特点 | 使用建议 |
|---|---|---|
| FAISS | Facebook 开源,轻量快速 | 本地原型开发 |
| Milvus | 分布式、支持 GPU | 企业级、海量数据 |
| Weaviate | REST API 接口友好 | 快速接入、支持多种检索 |
| Qdrant | 高性能、开源 | 小型服务部署 |
每个工具的选择都应根据应用的规模、数据量以及计算资源等多种因素进行决定。
3. 文档向量化与切分:提升检索效率的关键步骤
3.1 向量化文档的必要性
为了能够高效检索到相关文档,首先需要将文档内容转化为向量表示。这一过程通常使用嵌入模型(如 BERT、GPT)来完成,将每个文档的语义信息转化为高维向量。向量化后,文档就可以在向量空间中进行检索和比较。
然而,单个文档往往过长,直接将整个文档向量化并存入数据库可能不利于检索效率。这时,我们需要对文档进行切分。
3.2 Chunking:文本切分的策略
“Chunking”(文本切分)是文档向量化过程中至关重要的一步。通过将长文档分割成多个较小的片段,能够显著提高检索精度和效率。常见的切分策略包括:
- 每段 300~500 字:这种长度的片段既能保证信息的完整性,又不会过长,适合嵌入模型的处理。
- 滑动窗口 + 重叠:为了避免语义断裂,常采用滑动窗口技术,将相邻的文本片段之间进行重叠,例如每 500 字切分,并让前后部分有 250 字的重叠。
示例:
段1:第0~500字
段2:第250~750字(重叠部分)
段3:第500~1000字
这种切分方式确保了文档中的重要信息能够被完整保留,同时也避免了模型输入过长的问题。
4. 检索策略:如何选择最合适的方案?
在实现文档检索时,Retriever 不仅可以通过语义相似度来检索,还可以结合不同的检索策略。以下是三种常见的检索策略及其优缺点:
| 检索类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 向量检索 | 基于语义 | 语义理解强 | 易引入干扰信息 |
| 关键词检索 | 关键词匹配 | 精准性高 | 语义能力差 |
| 混合检索(Hybrid) | 向量 + BM25 权重融合 | 准确率高 | 实现稍复杂 |
- 向量检索:基于语义的检索方法,能够识别到语义相似的文档,适合处理复杂的自然语言查询,但可能会引入一些不相关的噪音信息。
- 关键词检索:基于传统的关键词匹配,能够快速且精确地找到包含指定关键词的文档,适合对关键词要求比较明确的查询。
- 混合检索:结合向量检索和关键词检索的优势,通过加权融合,提升准确性,但实现相对复杂。
在实际应用中,开发者可以根据具体需求和数据特征选择合适的检索策略。
5. 实际演示:用 FAISS 完成文档检索
为了帮助大家更好地理解如何在实际中实现 Retriever,我们使用 FAISS(Facebook 开源的向量检索库)来完成一个简单的文档检索。
5.1 安装 FAISS
首先,需要安装 FAISS 库:
pip install faiss-cpu
5.2 构建索引
接下来,使用 FAISS 创建一个向量索引,并将文档的向量添加到索引中:
import faiss
index = faiss.IndexFlatL2(1536) # 向量维度
index.add(vectors) # vectors 是你的文档向量
5.3 查询与检索
最后,使用 FAISS 执行查询并返回最相似的文档:
D, I = index.search(query_vector, top_k)
这里,I 是结果的索引,D 是距离(越小越相似)。
6. 结语
在 RAG 中,Retriever 扮演着至关重要的角色,它通过高效的文档检索为生成模型提供了丰富的上下文信息。而如何构建一个高效的向量数据库、选择合适的文本切分策略以及优化检索策略,将直接影响到整个系统的性能和答案的质量。通过本篇文章的深入剖析,希望大家能够对 RAG 中的 Retriever 有一个更全面的理解,并能够在实际应用中根据需求做出最优的技术选择。


















 2475
2475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











