







一句话总结:将预训练权重分解为大小(magnitude)和方向(direction)两个组成部分,并分别对它们进行微调,较LoRA进一步细化。
先简单复习一下LoRA:
即通过低秩矩阵展开,将原本需要微调的全基础网络,变成仅需要微调低秩展开矩阵的形式,大幅度减少了所需的参数量。
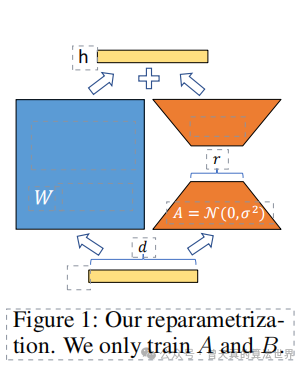
更新方式:
在2020年的文章《Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning》中,已经证明了在预训练的NLP模型中,可以投影到更低维度的子空间,同时保持较好的最终表现。

回到DoRA:
首先我们给出一个完整流程图(尤其注意和LoRA的对比,多了一层):
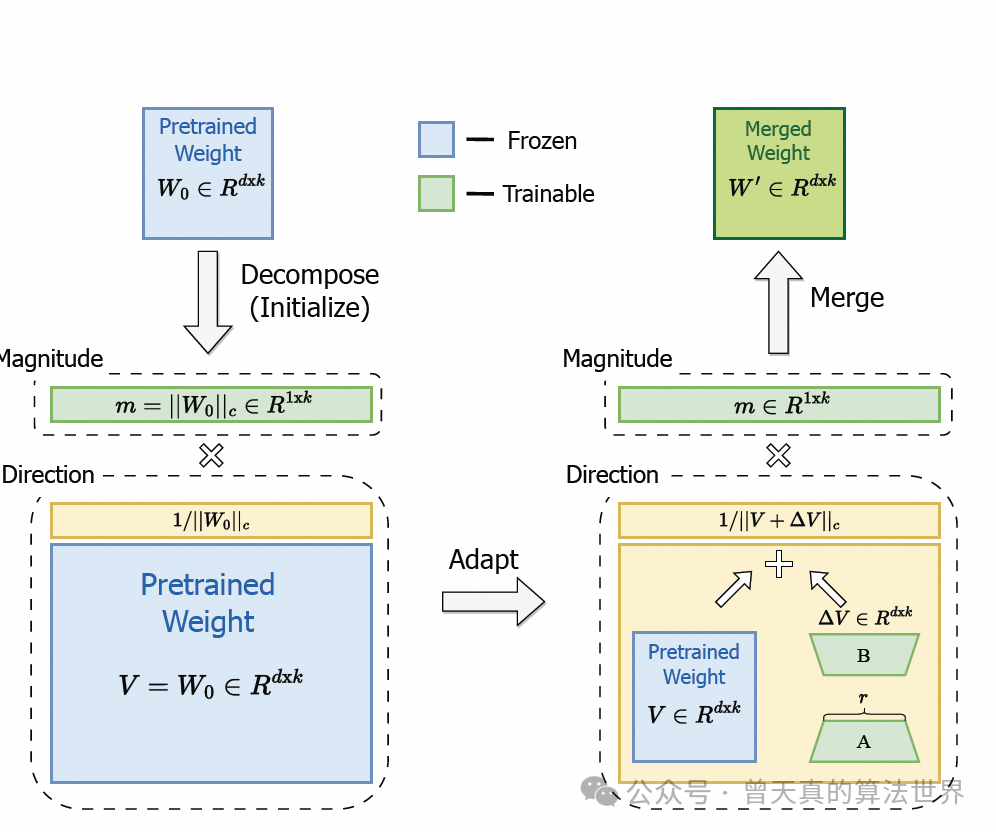
它将预训练权重分解为幅度和方向组件用于微调,尤其是与LoRA一起使用以有效更新方向组件。其中|| · ||c表示矩阵的每个列向量的向量范数。
权重解耦的Low-Rank Adaptation:
DoRA方法的核心是将预训练的权重分解为两个部分:大小(magnitude)和方向(direction)。 这种分解基于权重归一化(Weight Normalization)的思想,旨在通过重新参数化权重矩阵来加速优化过程。
初始化权重分解:
预训练权重:记为𝑊0∈𝑅𝑑×𝑘,其中𝑑d和𝑘k分别是权重矩阵的维度。
分解:权重矩阵𝑊被分解为𝑊=𝑚𝑉,其中𝑚∈𝑅1×𝑘是大小向量,𝑉∈𝑅𝑑×𝑘是方向矩阵,且∥𝑉∥𝑐=∥𝑊∥𝑐,保证了𝑉的每一列在初始化时都是单位向量。
微调过程:
首先固定方向矩阵:在微调过程中,方向矩阵𝑉被保持固定,而大小向量𝑚m被设为可训练的参数。LoRA应用于方向更新:方向组件的更新通过LoRA方法实现,即使用两个低秩矩阵𝐵∈𝑅𝑑×𝑟和𝐴∈𝑅𝑟×𝑘的乘积来学习方向更新Δ𝑉,其中𝑟≪min(𝑑,𝑘)。
更新后的权重表示:
微调后的权重:记为𝑊′,可以表示为𝑊′=𝑚(𝑉+Δ𝑉),或者等价地表示为:
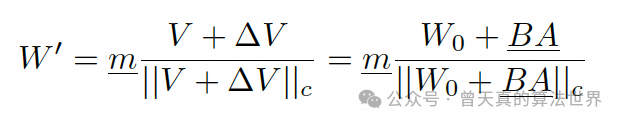
其中𝐵𝐴是LoRA方法中用于更新的低秩矩阵乘积。
DoRA的梯度计算:
观察DoRA如何通过其权重分解策略来影响梯度的计算。
梯度表达式的推导步骤:
STEP1,权重矩阵的更新:权重矩阵𝑊′通过分解为𝑚(𝑉+Δ𝑉),其中Δ𝑉是低秩更新。
STEP2,损失函数关于W′的梯度:记为∇𝑊′𝐿,是损失函数𝐿关于权重矩阵𝑊′的梯度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









