






1. 背景介绍
在人工智能技术加速渗透各行各业的今天,大型语言模型(LLM)的落地应用正面临两大核心挑战:通用性与场景适配的平衡,以及数据隐私与计算成本的博弈。传统大模型往往依赖云端算力与海量数据,导致企业面临高昂的部署成本、潜在的数据泄露风险,以及垂直领域专业知识适配不足的困境。DeepSeekR1以其“轻量化架构+本地化部署+高效微调”进入中小企业的视野,具备低硬件门槛(最低8GB内存即可运行基础版)、低数据依赖(支持小样本微调)、低部署复杂度(兼容主流国产芯片),以及高场景适配性(强化学习优化的推理性能),形成了一条“开箱即用-按需优化-深度定制”的渐进式路径。
本文以此为起点,介绍基于DeepSeek R1 微调自己的大模型,并用低成本方式本地化部署,让个人用户也能享受到AI大模型算力平民化的普照。
2. 环境准备
硬件环境(如果自己有显卡):16G显存、32G内存和100G+磁盘;如果没有,可以申请使用Google免费的T100显卡资源。
软件环境:
- 基本包:Python 3.11, torch 2.6.0, cuda 2.5.1+cu124.
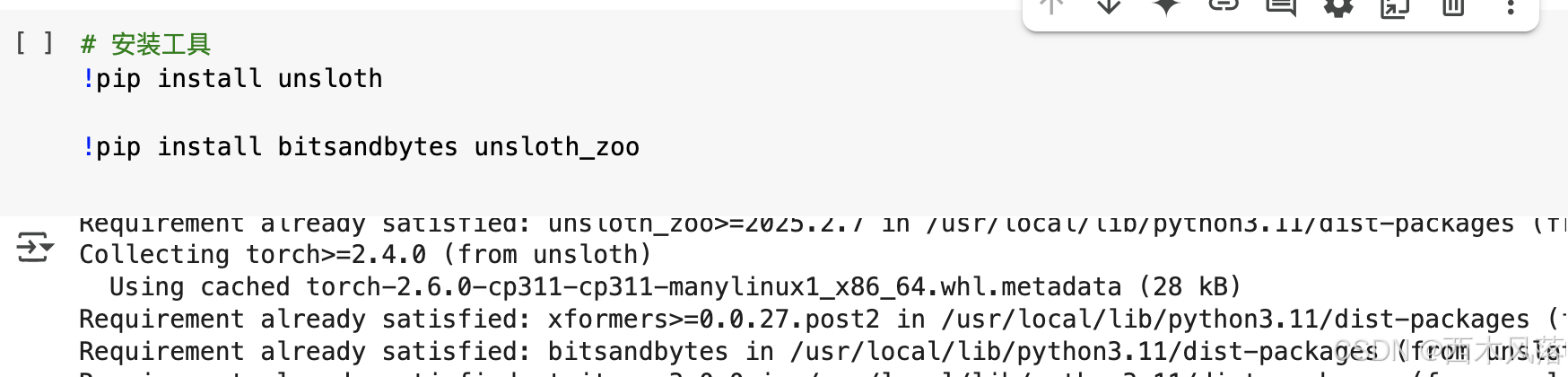
- unsloth:是一个用于加速 PyTorch 模型训练的 Python 库,它通过优化模型的内存使用和计算效率,帮助用户更高效地训练深度学习模型,尤其在处理大模型时优势明显。
bitsandbytes:是一个用于在 PyTorch 中进行 8 位和 4 位量化的 Python 工具包,可以显著减少模型的内存占用,从而加速深度学习模型的训练和推理过程。通过设置load_in_4bit=True来启用 4 位量化。-
unsloth_zoo:与unsloth配合,包含一些预训练工具
如果使用Google免费GPU,可申请https://colab.research.google.com/
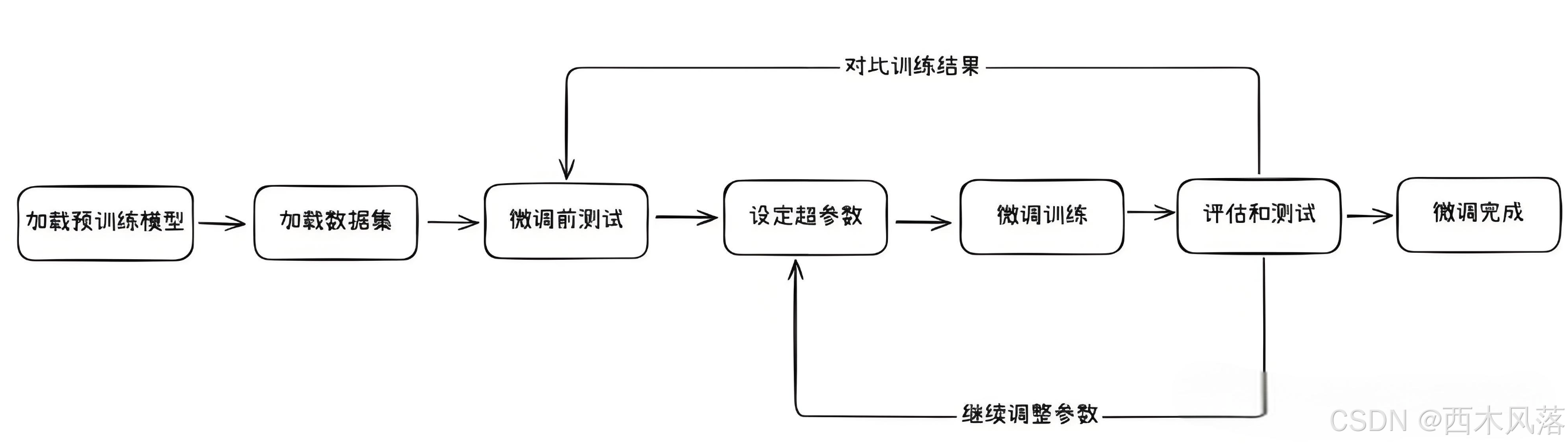
3. 模型微调
整体流程如下:
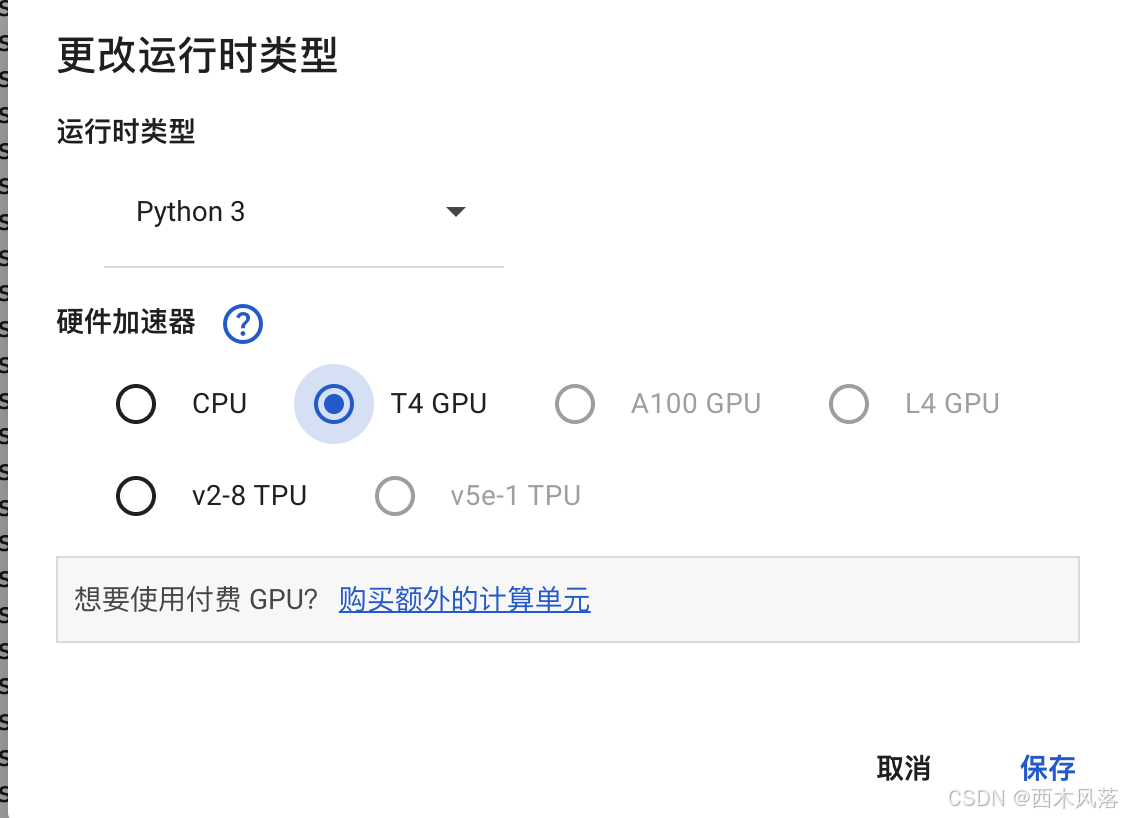
设定Google环境:
ipynb代码如下:
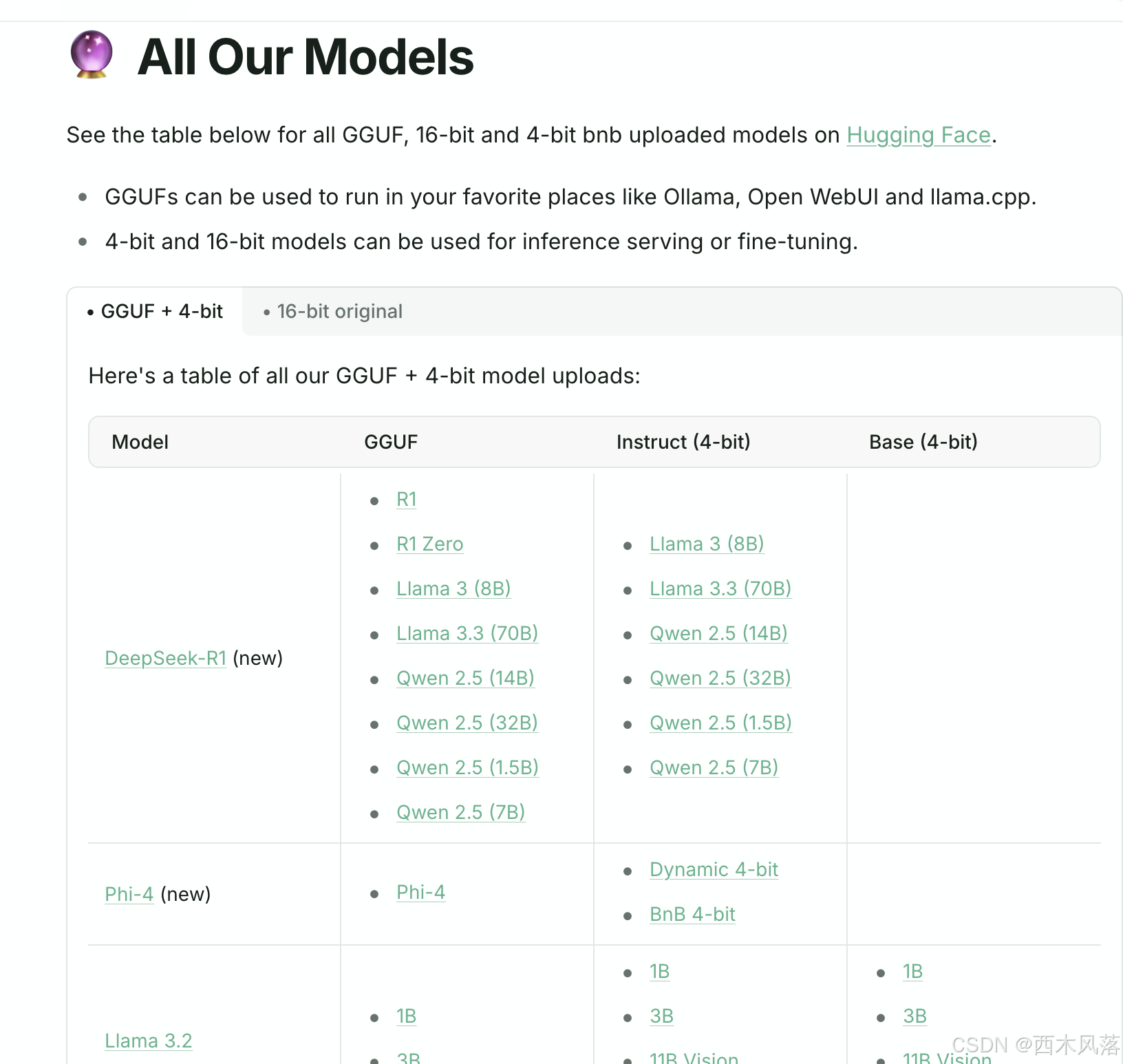
加载模型:
 可下载的模型All Our Models | Unsloth Documentation
可下载的模型All Our Models | Unsloth Documentation
 测试模型:
测试模型:

定义微调训练模板:

加载微调数据,





保存模型:
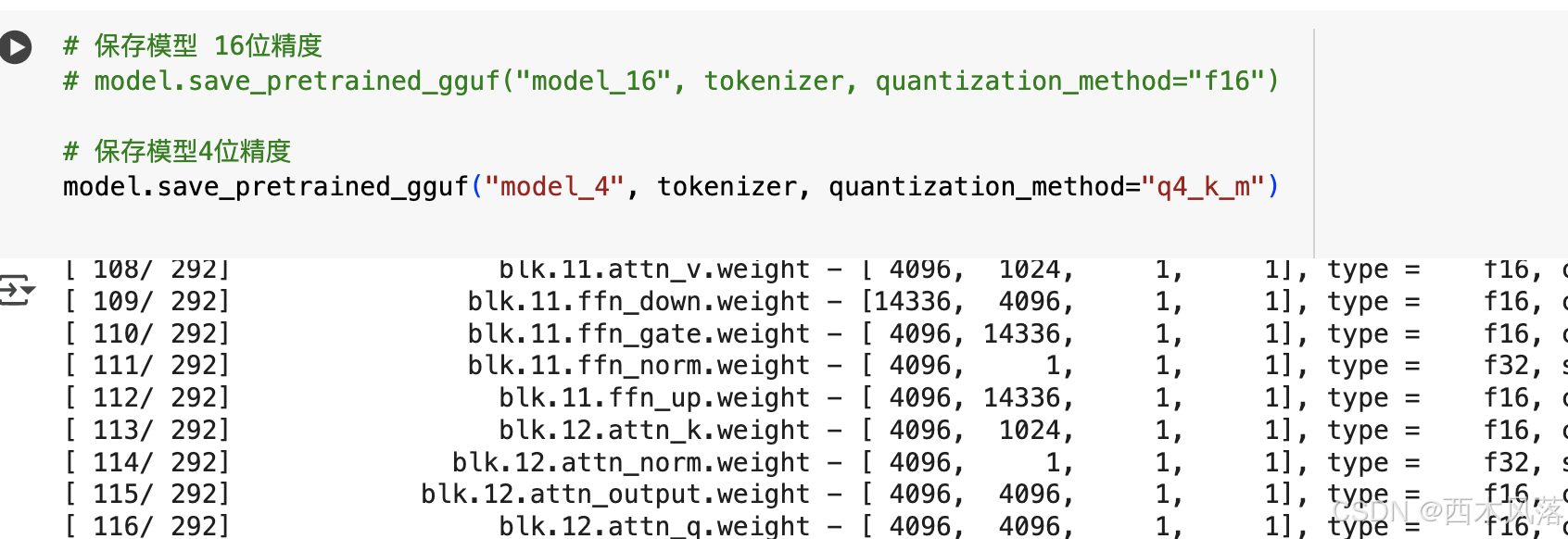


4. 本地部署模型
采用Ollama本地部署模型。
Ollama下载安装地址:
OllamaGet up and running with large language models.![]() https://registry.ollama.ai/ 本地下载安装后验证:
https://registry.ollama.ai/ 本地下载安装后验证:

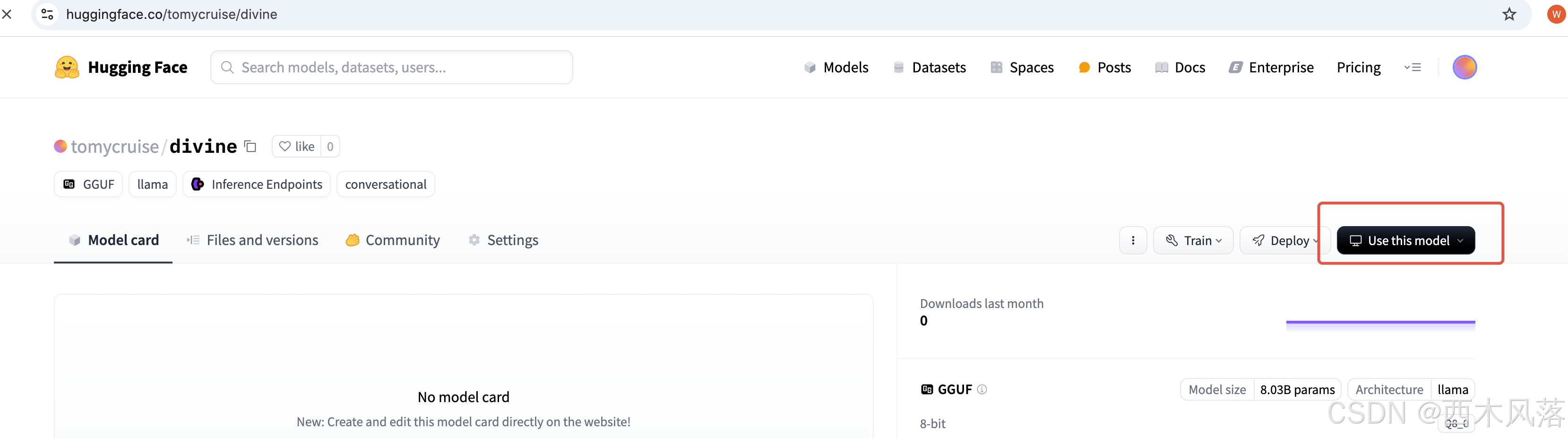
从huggfacing上直接下载安装微调后的模型:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









