 STDC网络详解:实时语义分割的创新
STDC网络详解:实时语义分割的创新





 本文深入探讨了STDC网络,一种针对实时语义分割问题的高效结构。作者通过改进BiSeNet的multi-path结构,提出STDC模块,减少计算量并保持多尺度特征的提取。STDC网络在Cityscapes和CamVid数据集上表现出色,实现了速度与精度的良好平衡。此外,文章介绍了网络的详细实现,包括不同模块的原理和代码示例。
本文深入探讨了STDC网络,一种针对实时语义分割问题的高效结构。作者通过改进BiSeNet的multi-path结构,提出STDC模块,减少计算量并保持多尺度特征的提取。STDC网络在Cityscapes和CamVid数据集上表现出色,实现了速度与精度的良好平衡。此外,文章介绍了网络的详细实现,包括不同模块的原理和代码示例。
1、主要参考
(1)参考的blog
【语义分割】——STDC-Seg快又强 + 细节边缘的监督_农夫山泉2号的博客-优快云博客_stdcseg
【CVPR2021语义分割】STDC语义分割网络|BiSeNet的轻量化加强版 - 知乎
【STDC】《Rethinking BiSeNet For Real-time Semantic Segmentation》_bryant_meng的博客-优快云博客
(2)github地址
https://github.com/chenjun2hao/STDC-Seg(3)论文下载地址
(4)作者单位:
美团,做外卖机器人?
2、主要原理
2.1论文题目
Rethinking BiSeNet For Real-time Semantic Segmentation
Rethinking说明了一切
关于v1和v2的整理见下面文档
(24)语义分割--BiSeNetV1 和 BiSeNetV2_chencaw的博客-优快云博客
2.2摘要看看先
- BiSeNet[28,27]已被证明是一种流行的用于实时分割的双流网络。但是,它通过额外的通道来编码空间信息的方法是耗时的。而且主干网从预先训练过模型而来,比如图像分类的网络,由于特定任务设计的不同,可能无法有效地进行图像分割。
- 为了解决这些问题,我们提出了一种新的、有效的结构,即短期密集级联网络(Short-Term Dense Concatenate networkSTDC network),它消除了结构冗余。
- 具体来说,我们逐步降低特征图的维数,利用特征图的聚合来表示图像,形成了STDC网络的基本模块。在解码器中,我们提出了一个细节聚合模块,将空间信息的学习以单流的方式集成到底层。最后,融合底层特征和深层特征,预测最终的分割结果。
- 在Cityscapes和CamVid数据集上的大量实验证明了我们的方法的有效性,实现了分割精度和推理速度之间的良好平衡。
- 在cityscape上,我们在测试集上实现了71.9%的mIoU,在NVIDIA GTX 1080Ti上的速度为250.4 FPS,比最新的方法快45.2%。在更高图像分辨率上以97.0 FPS的速度推断,实现了76.8%的mIoU。
2.3 研究背景

(1)当前的实时语义分割方法:
- 在实时推理方面,一些工作,如(1)DFANet[18]和BiSeNetV1[28]选择了轻量级的主干,并研究了特征融合或聚合模块的方法来补偿精度的下降。用了空间信息XXX不好,预训练模型是分类来的,如何不好
- (2)另一些工作通过降低输入分辨率,如何XXXXX不好
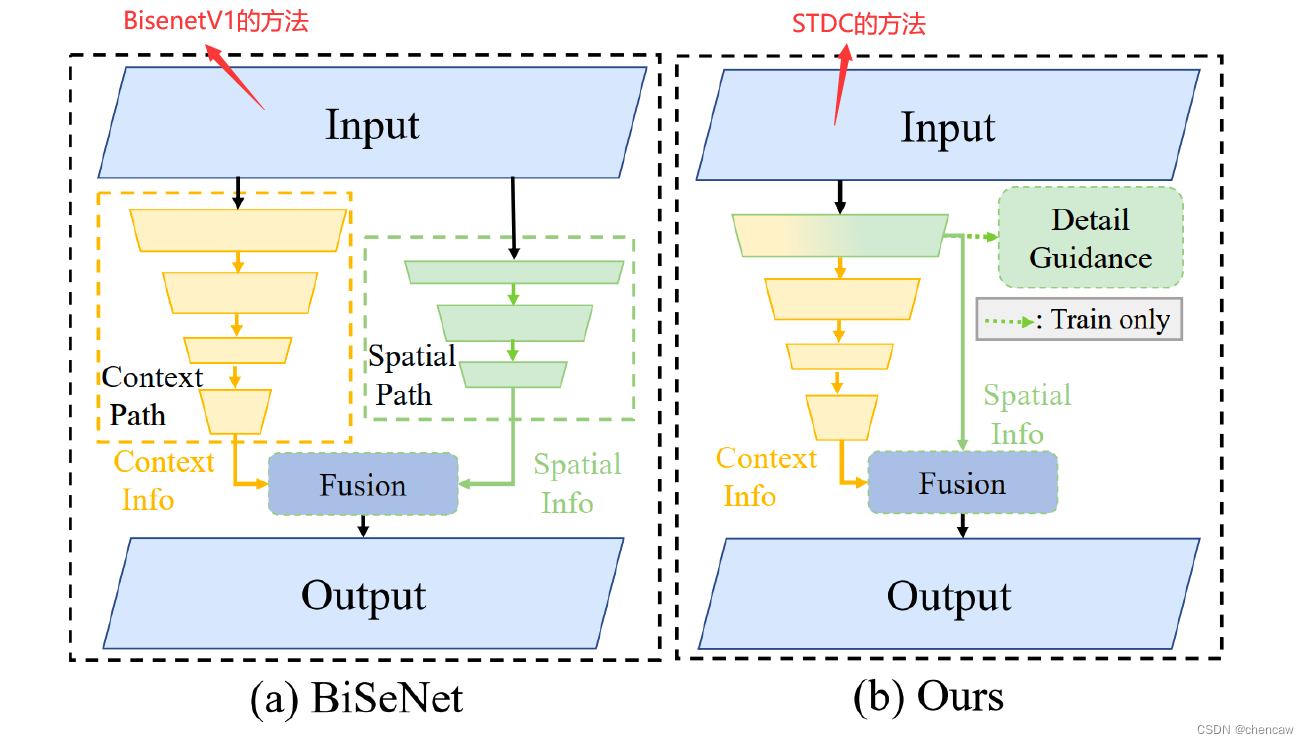
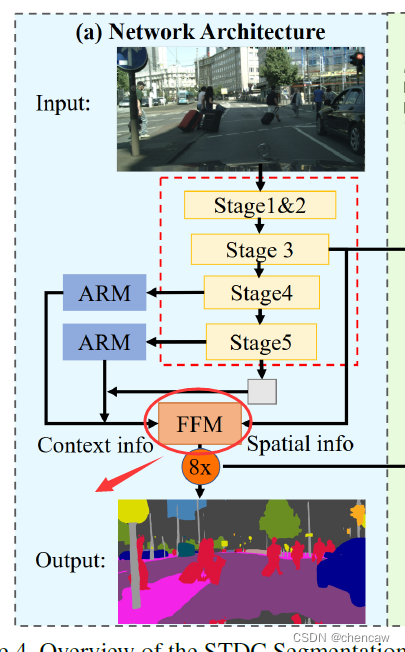
2.4 STDC网络
作者提出了STDC模块,能够使用较少的参数量提取多尺度特征,且能够很方便地集成到U-Net类型的语义分割网络中;对BiSeNet中的multi-path结构做出改进,在提取底层细节特征的同时减少网络计算量。
2.4.1 STDC模块的原理
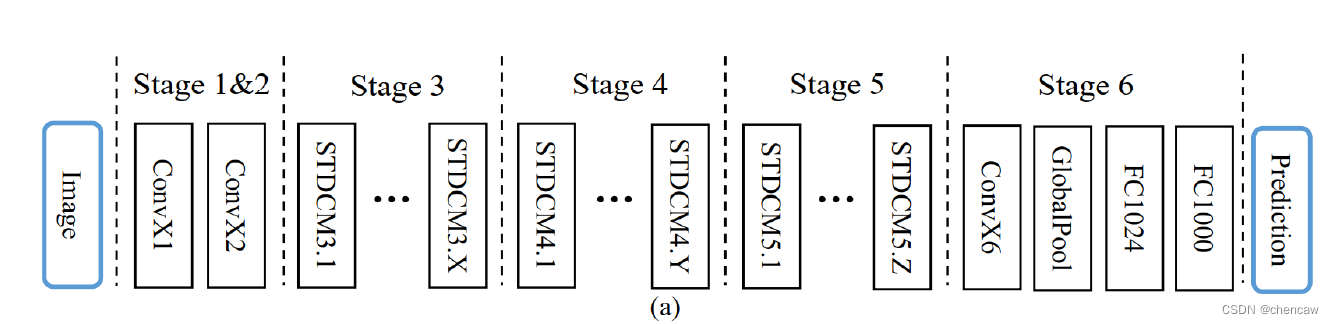
(1)通用的STDC结构如下图a所示
(2)本文提出的STDC结构,没有stride=2的(下采样的)如图b所示
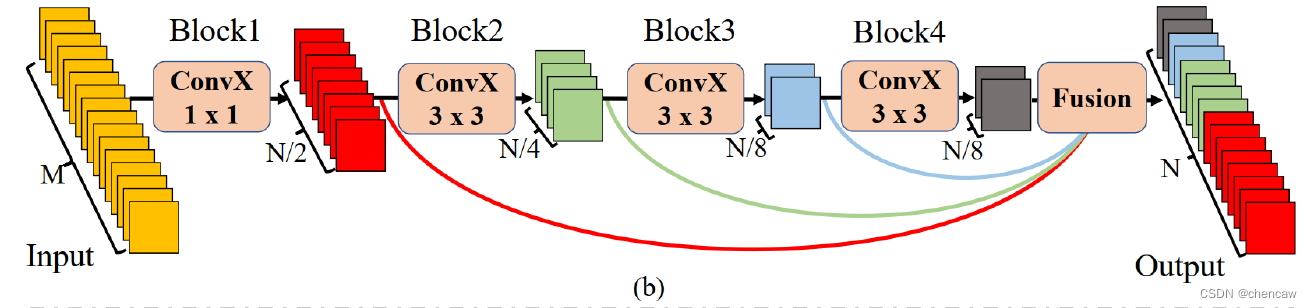
其中,图中的ConvX表示“卷积+BN+ReLU”操作,M表示输入特征通道数,N表示输出特征通道数。每个模块ConvX有着不同的核大小
下面引用了大佬的翻译
【CVPR2021语义分割】STDC语义分割网络|BiSeNet的轻量化加强版 - 知乎
- 在STDC模块中,第1个block的卷积核尺寸为1×1,其余block的卷积核尺寸为3×3。
- 若STDC模块的最终输出通道数为N,除最后一个block外,该模块内第i个block的输出通道数为N/2i;最后一个block的输出特征通道数与倒数第二个block保持一致。
- 与传统的backbone不同的是,STDC模块中深层的特征通道数少,浅层的特征通道数多。作者认为,浅层需要更多通道的特征编码细节信息;深层更关注高层次语义信息,过多的特征通道数量会导致信息冗余。
- STDC模块最终的输出为各block输出特征的融合,即
上式中的F表示融合函数,x1,x2,…,xn表示n个block的输出,xoutput 表示STDC模块的输出。使用concatenation操作融合n个block的特征。
(3)本文提出的STDC结构,包含stride=2的如图c所示
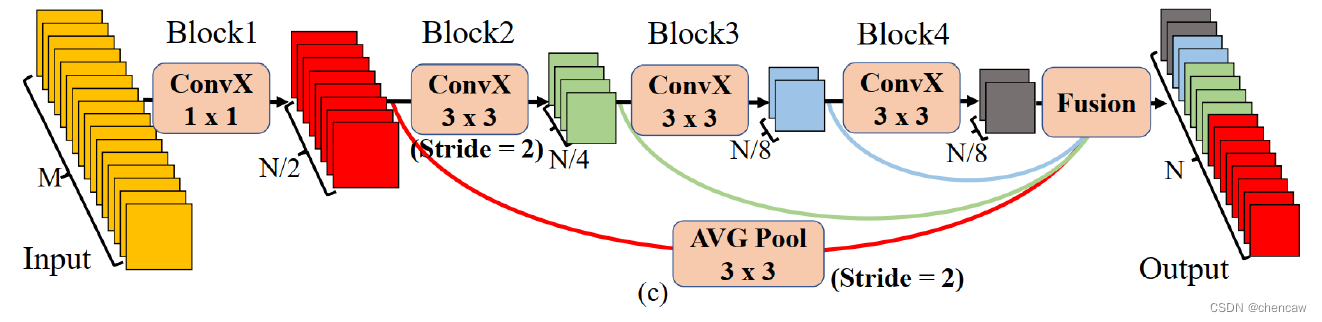
PS注意看:上图中Block2中有一个stride=2,AVG Pool中也有一个stride=2
对于stride=2版本的STDC模块,在Block2中进行下采样操作;为了在融合时保证feature map尺寸一致,对大尺寸的feature map使用stride=2、3×3的average pooling操作进行下采样
STDC模块有2个特点:(1)随着网络加深,逐渐减少特征通道数,以减少计算量;(2)STDC的输出融合了多个block的输出feature map,包含多尺度信息。
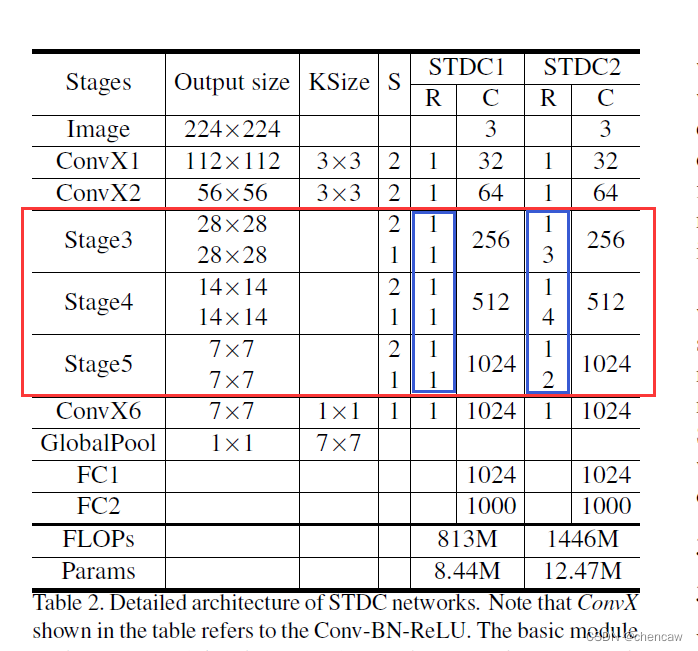
2.4.2 本文网络的结构
(1)下图表示由STDC模块组成的STDC网络,就是上面也提过的图a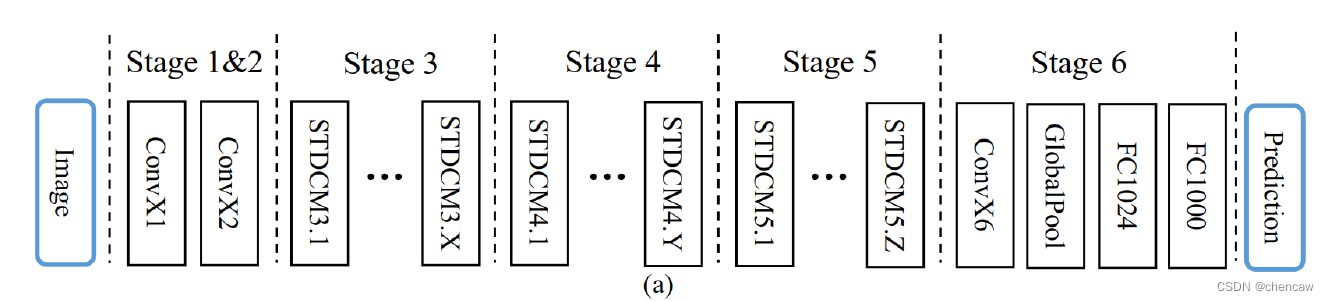
- 该网络包含6个Stage,Stage1~Stage5中都对feature map进行了步长为2的下采样,Stage6输出预测结果。
- 为了减少计算量,Stage1和Stage2中只使用1个卷积层。Stage3~Stage5中每个Stage包含若干个STDC模块,其中第1个STDC模块包含下采样操作,其余STDC模块保持feature map尺寸不变。
以上图为框架,作者构建了2个STDC网络,分别命名为STDC1和STDC2,它们的结构如下表所示:
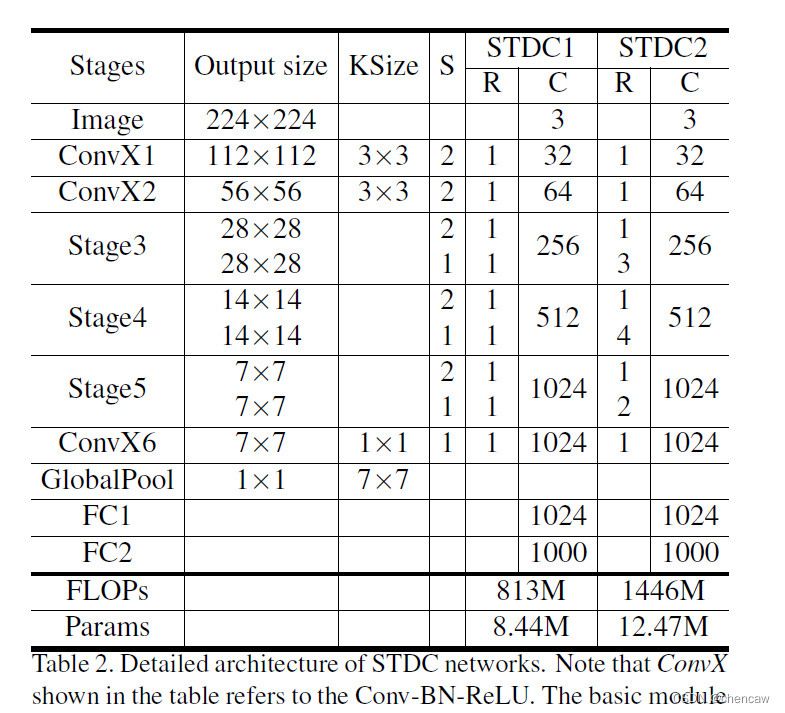
表中的ConvX表示“卷积+BN+ReLU”操作,Stage3~Stage5均由若干个STDC模块组成。上表中的KSize表示kernel尺寸,S表示步长,R表示重复次数,C表示输出通道数。
2.5 STDC网络的分类测试
针对如下例子,参加前面整理的教程
(2)pokeman_简单卷积分类的例子_chencaw的博客-优快云博客
2.5.1 使用了作者的网络
(1)简单的文件stdcnet.py,作者的github提供,无需更改
import torch
import torch.nn as nn
from torch.nn import init
import math
from torch.nn import functional as F #额外添加一下,陈20221104
class ConvX(nn.Module):
def __init__(self, in_planes, out_planes, kernel=3, stride=1):
super(ConvX, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel, stride=stride, padding=kernel//2, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.relu(self.bn(self.conv(x)))
return out
class AddBottleneck(nn.Module):
def __init__(self, in_planes, out_planes, block_num=3, stride=1):
super(AddBottleneck, self).__init__()
assert block_num > 1, print("block number should be larger than 1.")
self.conv_list = nn.ModuleList()
self.stride = stride
if stride == 2:
self.avd_layer = nn.Sequential(
nn.Conv2d(out_planes//2, out_planes//2, kernel_size=3, stride=2, padding=1, groups=out_planes//2, bias=False),
nn.BatchNorm2d(out_planes//2),
)
self.skip = nn.Sequential(
nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=2, padding=1, groups=in_planes, bias=False),
nn.BatchNorm2d(in_planes),
nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False),
nn.BatchNorm2d(out_planes),
)
stride = 1
for idx in range(block_num):
if idx == 0:
self.conv_list.append(ConvX(in_planes, out_planes//2, kernel=1))
elif idx == 1 and block_num == 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//2, stride=stride))
elif idx == 1 and block_num > 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//4, stride=stride))
elif idx < block_num - 1:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx+1))))
else:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx))))
def forward(self, x):
out_list = []
out = x
for idx, conv in enumerate(self.conv_list):
if idx == 0 and self.stride == 2:
out = self.avd_layer(conv(out))
else:
out = conv(out)
out_list.append(out)
if self.stride == 2:
x = self.skip(x)
return torch.cat(out_list, dim=1) + x
class CatBottleneck(nn.Module):
def __init__(self, in_planes, out_planes, block_num=3, stride=1):
super(CatBottleneck, self).__init__()
assert block_num > 1, print("block number should be larger than 1.")
self.conv_list = nn.ModuleList()
self.stride = stride
if stride == 2:
self.avd_layer = nn.Sequential(
nn.Conv2d(out_planes//2, out_planes//2, kernel_size=3, stride=2, padding=1, groups=out_planes//2, bias=False),
nn.BatchNorm2d(out_planes//2),
)
self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
stride = 1
for idx in range(block_num):
if idx == 0:
self.conv_list.append(ConvX(in_planes, out_planes//2, kernel=1))
elif idx == 1 and block_num == 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//2, stride=stride))
elif idx == 1 and block_num > 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//4, stride=stride))
elif idx < block_num - 1:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx+1))))
else:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx))))
def forward(self, x):
out_list = []
out1 = self.conv_list[0](x)
for idx, conv in enumerate(self.conv_list[1:]):
if idx == 0:
if self.stride == 2:
out = conv(self.avd_layer(out1))
else:
out = conv(out1)
else:
out = conv(out)
out_list.append(out)
if self.stride == 2:
out1 = self.skip(out1)
out_list.insert(0, out1)
out = torch.cat(out_list, dim=1)
return out
#STDC2Net
class STDCNet1446(nn.Module):
def __init__(self, base=64, layers=[4,5,3], block_num=4, type="cat", num_classes=1000, dropout=0.20, pretrain_model='', use_conv_last=False):
super(STDCNet1446, self).__init__()
if type == "cat":
block = CatBottleneck
elif type == "add":
block = AddBottleneck
self.use_conv_last = use_conv_last
self.features = self._make_layers(base, layers, block_num, block)
self.conv_last = ConvX(base*16, max(1024, base*16), 1, 1)
self.gap = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(max(1024, base*16), max(1024, base*16), bias=False)
self.bn = nn.BatchNorm1d(max(1024, base*16))
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=dropout)
self.linear = nn.Linear(max(1024, base*16), num_classes, bias=False)
self.x2 = nn.Sequential(self.features[:1])
self.x4 = nn.Sequential(self.features[1:2])
self.x8 = nn.Sequential(self.features[2:6])
self.x16 = nn.Sequential(self.features[6:11])
self.x32 = nn.Sequential(self.features[11:])
if pretrain_model:
print('use pretrain model {}'.format(pretrain_model))
self.init_weight(pretrain_model)
else:
self.init_params()
def init_weight(self, pretrain_model):
state_dict = torch.load(pretrain_model)["state_dict"]
self_state_dict = self.state_dict()
for k, v in state_dict.items():
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def _make_layers(self, base, layers, block_num, block):
features = []
features += [ConvX(3, base//2, 3, 2)]
features += [ConvX(base//2, base, 3, 2)]
for i, layer in enumerate(layers):
for j in range(layer):
if i == 0 and j == 0:
features.append(block(base, base*4, block_num, 2))
elif j == 0:
features.append(block(base*int(math.pow(2,i+1)), base*int(math.pow(2,i+2)), block_num, 2))
else:
features.append(block(base*int(math.pow(2,i+2)), base*int(math.pow(2,i+2)), block_num, 1))
return nn.Sequential(*features)
def forward(self, x):
feat2 = self.x2(x)
feat4 = self.x4(feat2)
feat8 = self.x8(feat4)
feat16 = self.x16(feat8)
feat32 = self.x32(feat16)
if self.use_conv_last:
feat32 = self.conv_last(feat32)
return feat2, feat4, feat8, feat16, feat32
def forward_impl(self, x):
out = self.features(x)
out = self.conv_last(out).pow(2)
out = self.gap(out).flatten(1)
out = self.fc(out)
# out = self.bn(out)
out = self.relu(out)
# out = self.relu(self.bn(self.fc(out)))
out = self.dropout(out)
out = self.linear(out)
return out
# STDC1Net
class STDCNet813(nn.Module):
def __init__(self, base=64, layers=[2,2,2], block_num=4, type="cat", num_classes=1000, dropout=0.20, pretrain_model='', use_conv_last=False):
super(STDCNet813, self).__init__()
if type == "cat":
block = CatBottleneck
elif type == "add":
block = AddBottleneck
self.use_conv_last = use_conv_last
self.features = self._make_layers(base, layers, block_num, block)
self.conv_last = ConvX(base*16, max(1024, base*16), 1, 1)
self.gap = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(max(1024, base*16), max(1024, base*16), bias=False)
self.bn = nn.BatchNorm1d(max(1024, base*16))
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(p=dropout)
self.linear = nn.Linear(max(1024, base*16), num_classes, bias=False)
self.x2 = nn.Sequential(self.features[:1])
self.x4 = nn.Sequential(self.features[1:2])
self.x8 = nn.Sequential(self.features[2:4])
self.x16 = nn.Sequential(self.features[4:6])
self.x32 = nn.Sequential(self.features[6:])
if pretrain_model:
print('use pretrain model {}'.format(pretrain_model))
self.init_weight(pretrain_model)
else:
self.init_params()
def init_weight(self, pretrain_model):
state_dict = torch.load(pretrain_model)["state_dict"]
self_state_dict = self.state_dict()
for k, v in state_dict.items():
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def _make_layers(self, base, layers, block_num, block):
features = []
features += [ConvX(3, base//2, 3, 2)]
features += [ConvX(base//2, base, 3, 2)]
for i, layer in enumerate(layers):
for j in range(layer):
if i == 0 and j == 0:
features.append(block(base, base*4, block_num, 2))
elif j == 0:
features.append(block(base*int(math.pow(2,i+1)), base*int(math.pow(2,i+2)), block_num, 2))
else:
features.append(block(base*int(math.pow(2,i+2)), base*int(math.pow(2,i+2)), block_num, 1))
return nn.Sequential(*features)
def forward(self, x):
feat2 = self.x2(x)
feat4 = self.x4(feat2)
feat8 = self.x8(feat4)
feat16 = self.x16(feat8)
feat32 = self.x32(feat16)
if self.use_conv_last:
feat32 = self.conv_last(feat32)
return feat2, feat4, feat8, feat16, feat32
def forward_impl(self, x):
out = self.features(x)
out = self.conv_last(out).pow(2)
out = self.gap(out).flatten(1)
out = self.fc(out)
# out = self.bn(out)
out = self.relu(out)
# out = self.relu(self.bn(self.fc(out)))
out = self.dropout(out)
out = self.linear(out)
# out = F.relu(out) #额外添加一下,陈20221104,不需要!!
return out
if __name__ == "__main__":
model = STDCNet813(num_classes=1000, dropout=0.00, block_num=4)
model.eval()
x = torch.randn(1,3,224,224)
y = model(x)
torch.save(model.state_dict(), 'cat.pth')
print(y.size())
(2)简单的训练代码
import torch
from torch import optim, nn
# import visdom
from tensorboardX import SummaryWriter #(1)引入tensorboardX
# import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms,datasets
# from pokemon import Pokemon
# from resnet import ResNet18
from PIL import Image
from stdcnet import STDCNet813
from tqdm import tqdm
batchsz = 64
# lr = 1e-3
lr = 1e-5
# epochs = 10
epochs = 500
img_resize = 224
device = torch.device('cuda')
# device = torch.device('cpu')
torch.manual_seed(1234)
# tf = transforms.Compose([
# transforms.Resize((224,224)),
# transforms.ToTensor(),
# ])
#输入应该是PIL.Image类型
tf = transforms.Compose([
#匿名函数
# lambda x:Image.open(x).convert('RGB'), # string path= > image data
transforms.Resize((int(img_resize*1.25), int(img_resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(img_resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# db = torchvision.datasets.ImageFolder(root='pokemon', transform=tf)
train_db = datasets.ImageFolder(root='/home/chen/chen_deep/data/pokeman/train', transform=tf)
print(train_db.class_to_idx)
print("个数")
print(len(train_db))
val_db = datasets.ImageFolder(root='/home/chen/chen_deep/data/pokeman/val', transform=tf)
test_db = datasets.ImageFolder(root='/home/chen/chen_deep/data/pokeman/test', transform=tf)
# train_db = Pokemon('pokemon', 224, mode='train')
# val_db = Pokemon('pokemon', 224, mode='val')
# test_db = Pokemon('pokemon', 224, mode='test')
# train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True,
# num_workers=4)
# val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
# test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True)
val_loader = DataLoader(val_db, batch_size=batchsz)
test_loader = DataLoader(test_db, batch_size=batchsz)
# viz = visdom.Visdom()
#(2)初始化,注意可以给定路径
writer = SummaryWriter('runs/chen_stdc_pokeman_test1')
def evalute(model, loader):
model.eval()
correct = 0
total = len(loader.dataset)
for x,y in loader:
x,y = x.to(device), y.to(device)
with torch.no_grad():
# logits = model(x)
logits = model.forward_impl(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = STDCNet813(num_classes=5, dropout=0.00, block_num=4).to(device)
# model = ResNet18(5).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
global_step = 0
for epoch in tqdm(range(epochs)):
for step, (x,y) in tqdm(enumerate(train_loader)):
# x: [b, 3, 224, 224], y: [b]
x, y = x.to(device), y.to(device)
model.train()
# logits = model(x)
logits = model.forward_impl(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#(3)将batch中TrainLoss添加到tensorboardX中
writer.add_scalar('TrainLoss', loss.item(), global_step=global_step)
global_step += 1
# if epoch % 10 == 0:
if epoch % 5 == 0:
val_acc = evalute(model, val_loader)
if val_acc> best_acc:
best_epoch = epoch
best_acc = val_acc
writer.add_scalar('TestAcc', val_acc, global_step=epoch)
writer.add_scalar('BestAcc', best_acc, global_step=epoch)
torch.save(model.state_dict(), 'best.mdl')
#(4)将epoch中TestAcc添加到tensorboardX中
# viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(model, test_loader)
print('test acc:', test_acc)
#(5)关闭writer
writer.close()
#(6)查看tensorboardx的方法
#tensorboard --logdir=D:/pytorch_learning2022/3chen_classify_test2022/1pokeman_sample/runs/chen_pokeman_test1
#tensorboard --logdir=runs/chen_stdc_pokeman_test1
#http://localhost:6006/
if __name__ == '__main__':
main()
(3)简单的测试代码test_stdc.py
import torch
from torch import optim, nn
from torch.utils.data import DataLoader
from torchvision import transforms,datasets ,models
# from resnet import ResNet18
from torchvision.models import resnet18
from PIL import Image
# from utils import Flatten
from stdcnet import STDCNet813
import os
img_resize = 224
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
# device = torch.device('cuda')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device('cpu')
tf = transforms.Compose([
#匿名函数
lambda x:Image.open(x).convert('RGB'), # string path= > image data
transforms.Resize((img_resize, img_resize)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
"""
函数说明: 根据训练结果对模型进行测试
:param img_test: 待测试的图片
:return: y: 测试结果,分类序号
"""
def model_test_img(model,img_test):
model.eval()
# img = Image.open(img_test).convert('RGB')
# resize = transforms.Resize([224,224])
# x = transforms.Resize([img_resize,img_resize])(img)
# x = transforms.ToTensor()(x)
x =tf(img_test)
x = x.to(device)
x = x.unsqueeze(0)
# x = transforms.Normalize(mean,std)(x)
# print(x.shape)
with torch.no_grad():
# logits = model(x)
logits = model.forward_impl(x)
pred = logits.argmax(dim=1)
return pred
def main():
#(1)如用anaconda激活你自己的环境
# conda env list
# conda activate chentorch_cp310
#分类名称
class_name = ['bulbasaur', 'charmander', 'mewtwo', 'pikachu', 'squirtle']
image_file = "/home/chen/chen_deep/data/pokeman/test/charmander/00000007.jpg"
# image_file = "/home/chen/chen_deep/data/pokeman/test/bulbasaur/00000014.jpg"
# image_file = "/home/chen/chen_deep/data/pokeman/train/bulbasaur/00000000.jpg"
# trained_model = resnet18(pretrained=True)
# trained_model = resnet18(weights = models.ResNet18_Weights.DEFAULT)
model = STDCNet813(num_classes=5, dropout=0.00, block_num=4).to(device)
# model = nn.Sequential(*list(trained_model.children())[:-1], #[b, 512, 1, 1]
# nn.Flatten(),
# # Flatten(), # [b, 512, 1, 1] => [b, 512]
# nn.Linear(512, 2)
# ).to(device)
#发现使用state_dict保存时如果是多GPU
#测试的时候也要多GPU
# os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'#设置所有可以使用的显卡,共计四块
# device_ids = [0,1]#选中其中两块
# model = nn.DataParallel(model, device_ids=device_ids)#并行使用两块
model.load_state_dict(torch.load('best.mdl'))
y = model_test_img(model,image_file)
print(y.item())
print("detect result is: ",class_name[y])
img_show = Image.open(image_file)
img_show.show()
if __name__ == '__main__':
main()2.6 STDC网络的实现
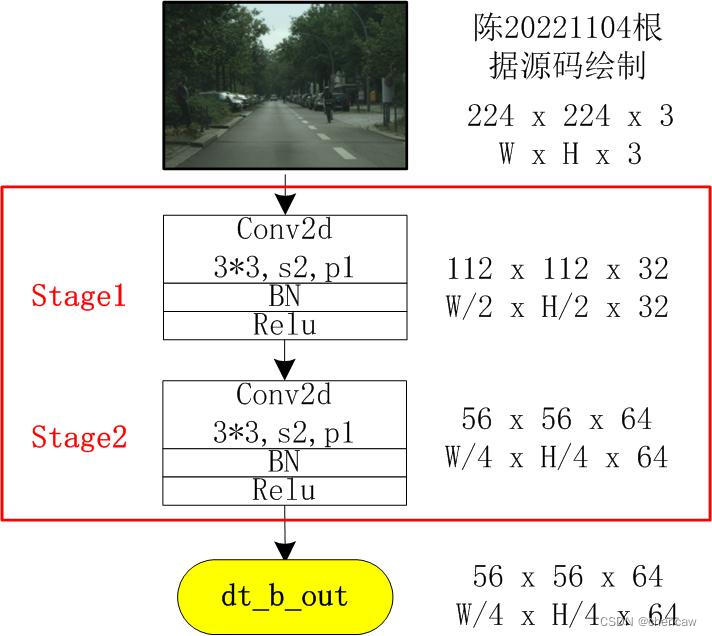
2.6.1 Stage1&2的实现
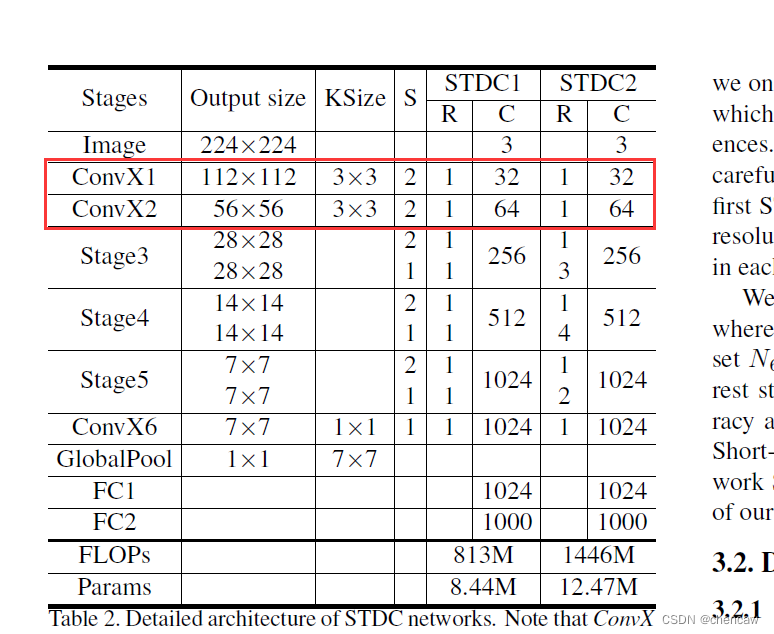
(1)Stage1&2对应的是ConvX1和ConvX2,不包含STDC的内容,如下图所示。
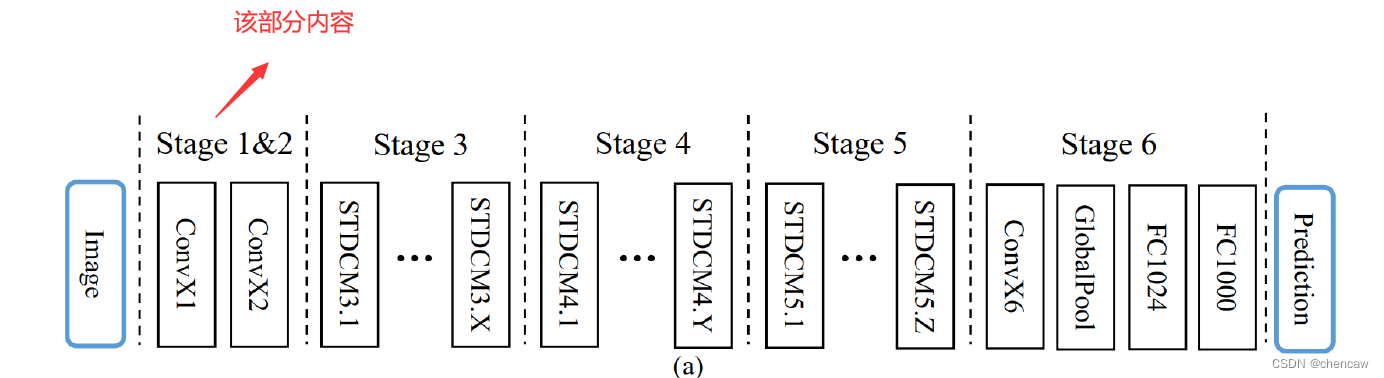
(2)对应的网络结构在下面这个位置
(3)测试代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class ConvX(nn.Module):
def __init__(self, in_planes, out_planes, kernel=3, stride=1):
super(ConvX, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel, stride=stride, padding=kernel//2, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.relu(self.bn(self.conv(x)))
return out
class Chen_Stage1and2(nn.Module):
def __init__(self,base=64,):
super(Chen_Stage1and2, self).__init__()
self.stage1 = ConvX(3, base//2, 3, 2)
self.stage2 = ConvX(base//2, base, 3, 2)
def forward(self, x):
out1 = self.stage1(x)
out2 = self.stage2(out1)
return out2
def save_onnx(model,x,model_file_name):
torch_out = torch.onnx.export(model, x,
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
if __name__ == "__main__":
stage1and2_net = Chen_Stage1and2()
x = torch.randn(16, 3, 224, 224)
dt_out = stage1and2_net(x)
print(dt_out.shape)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_stage1and2.onnx"
# #打印网络结构
summary(stage1and2_net, input_size=(16, 3, 224, 224))
# #保存为onnx
save_onnx(stage1and2_net,x,model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
(4)手绘图
可以看出使用了2个3*3,stride=2的卷积,快速下采样到原来的1/4
(5)netron导出的图
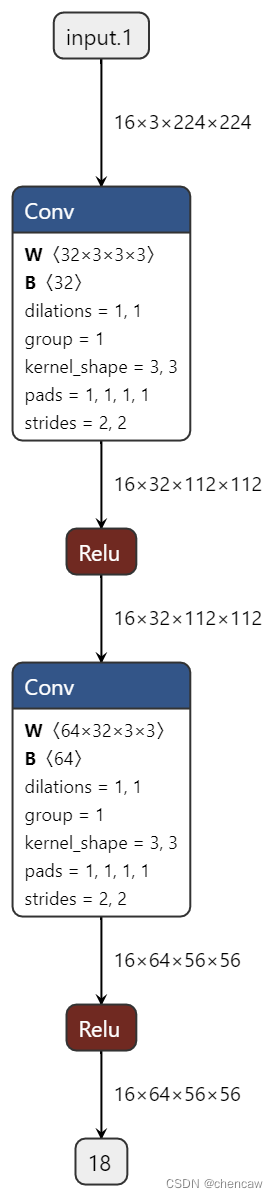
2.6.3 STDC1 网络模块的实现
(1)stdc网络模块对应的层次如下图所示。
(2)测试代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import math
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class ConvX(nn.Module):
def __init__(self, in_planes, out_planes, kernel=3, stride=1):
super(ConvX, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel, stride=stride, padding=kernel//2, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.relu(self.bn(self.conv(x)))
return out
class CatBottleneck(nn.Module):
def __init__(self, in_planes, out_planes, block_num=3, stride=1):
super(CatBottleneck, self).__init__()
assert block_num > 1, print("block number should be larger than 1.")
self.conv_list = nn.ModuleList()
self.stride = stride
if stride == 2:
self.avd_layer = nn.Sequential(
nn.Conv2d(out_planes//2, out_planes//2, kernel_size=3, stride=2, padding=1, groups=out_planes//2, bias=False),
nn.BatchNorm2d(out_planes//2),
)
self.skip = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)
stride = 1
for idx in range(block_num):
if idx == 0:
self.conv_list.append(ConvX(in_planes, out_planes//2, kernel=1))
elif idx == 1 and block_num == 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//2, stride=stride))
elif idx == 1 and block_num > 2:
self.conv_list.append(ConvX(out_planes//2, out_planes//4, stride=stride))
elif idx < block_num - 1:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx+1))))
else:
self.conv_list.append(ConvX(out_planes//int(math.pow(2, idx)), out_planes//int(math.pow(2, idx))))
def forward(self, x):
out_list = []
out1 = self.conv_list[0](x)
for idx, conv in enumerate(self.conv_list[1:]):
if idx == 0:
if self.stride == 2:
out = conv(self.avd_layer(out1))
else:
out = conv(out1)
else:
out = conv(out)
out_list.append(out)
if self.stride == 2:
out1 = self.skip(out1)
out_list.insert(0, out1)
out = torch.cat(out_list, dim=1)
return out
class Chen_Stage3to5(nn.Module):
def __init__(self,base=64,):
super(Chen_Stage3to5, self).__init__()
block_num =4
self.stage31 = CatBottleneck(base, base*4, block_num, 2)
#待修改,陈20221104
self.stage32 = CatBottleneck(base*4, base*4, block_num, 1)
# self.stage4 = CatBottleneck(base*4, base*8, block_num, 2)
# self.stage5 = CatBottleneck(base*8, base*16, block_num, 2)
def forward(self, x):
out11 = self.stage31(x)
# print("out11",out11.shape)
out12 = self.stage32(out11)
# out2 = self.stage4(out1)
# out3 = self.stage5(out2)
return out12
# return out3
# return out2
def save_onnx(model,x,model_file_name):
torch_out = torch.onnx.export(model, x,
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
if __name__ == "__main__":
stage3to5_net = Chen_Stage3to5()
x = torch.randn(16, 64, 56, 56)
dt_out = stage3to5_net(x)
print(dt_out.shape)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_stage3to5.onnx"
# #打印网络结构
summary(stage3to5_net, input_size=(16, 64, 56, 56))
# #保存为onnx
save_onnx(stage3to5_net,x,model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
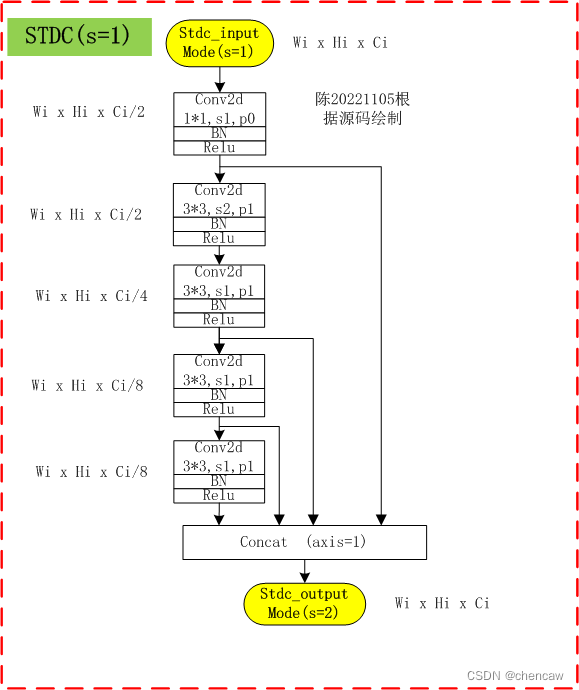
(3)手绘图,下图是STDC1格式中stage3的两个模块
1)第一个模块stride=2,带下采样;第二个模块没有stride=2
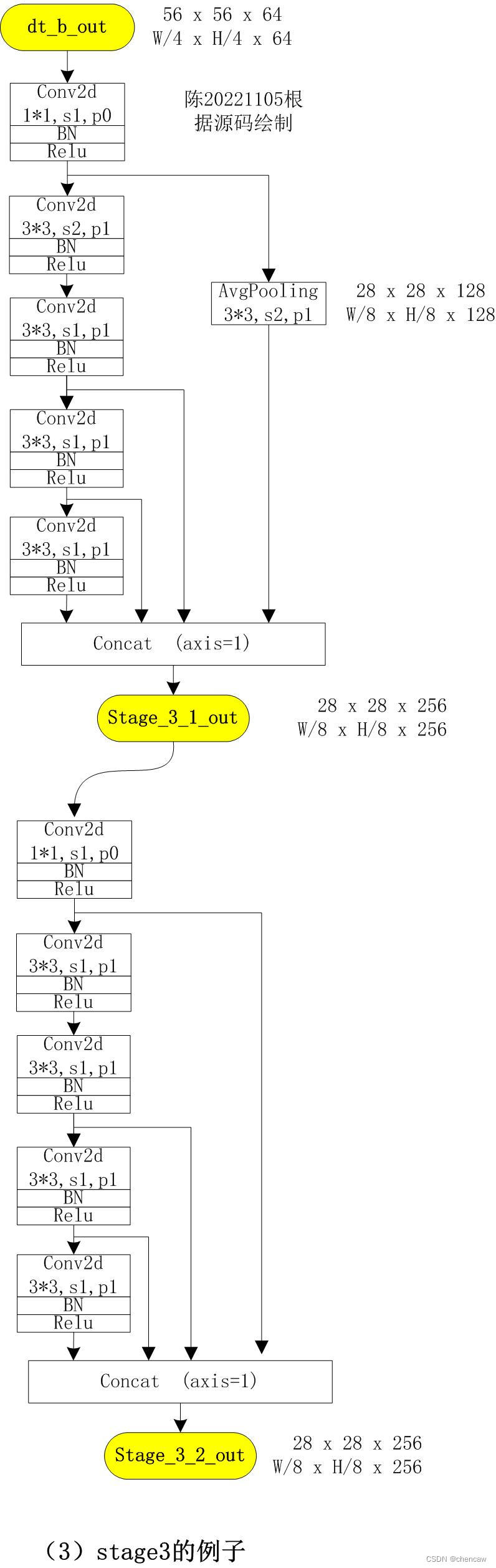
2)stride=2的通用格式的手绘图如下,stage3的通道翻了4倍,stage4和stage5翻了2倍
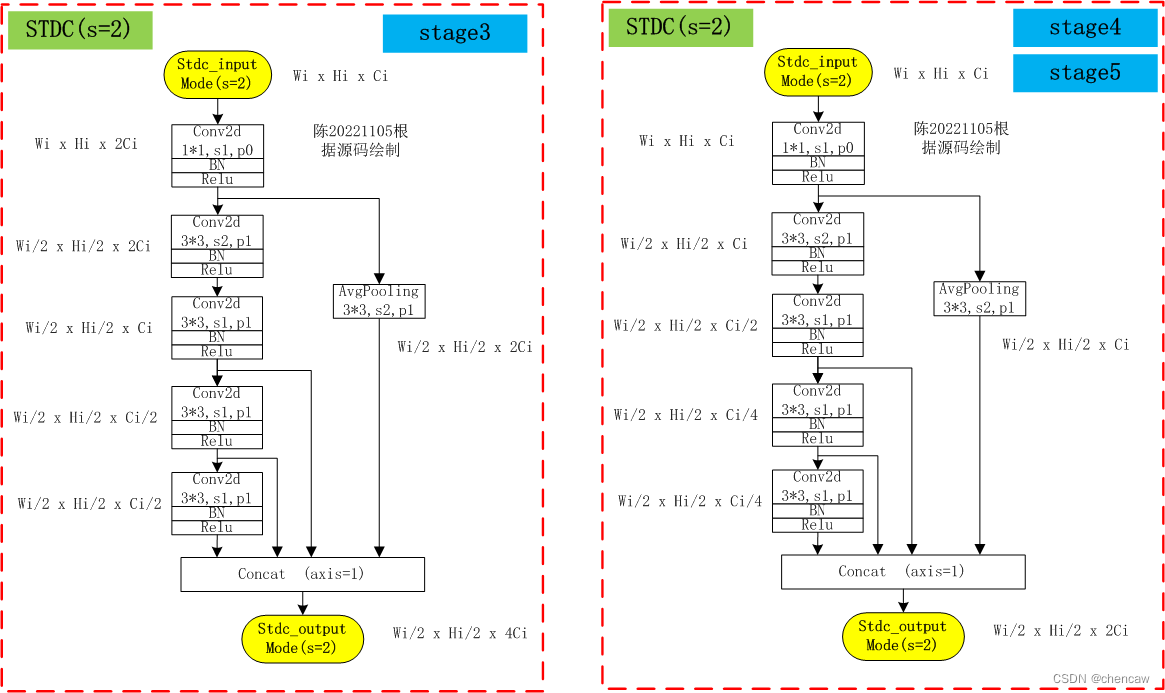
3)stride=1通用格式的手绘图如下
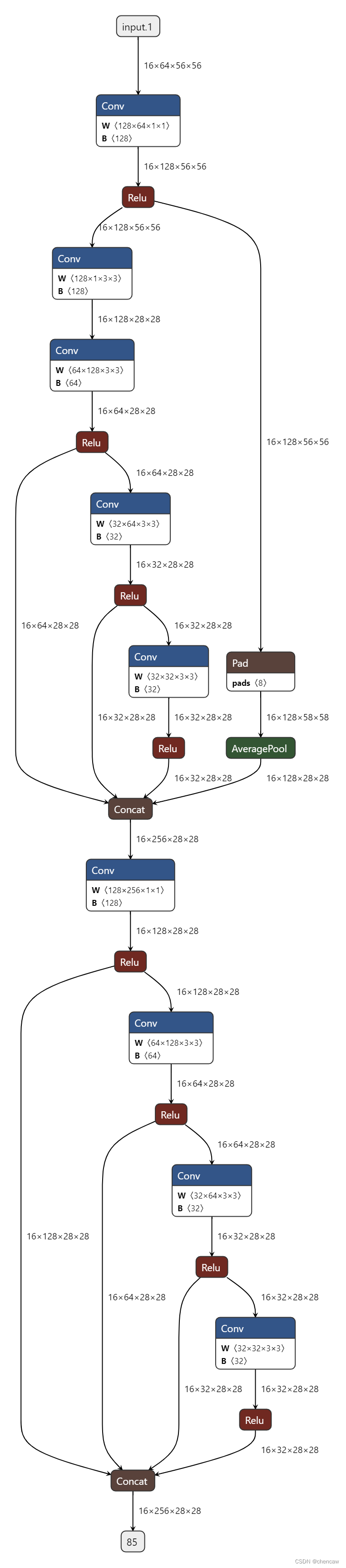
(4)导出的onnx图
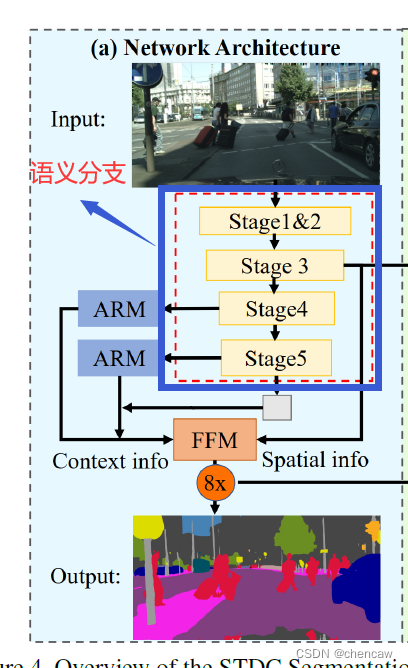
2.6.4 语义分支的实现
(1)下面stage1--stage5的实现
(2)手绘图
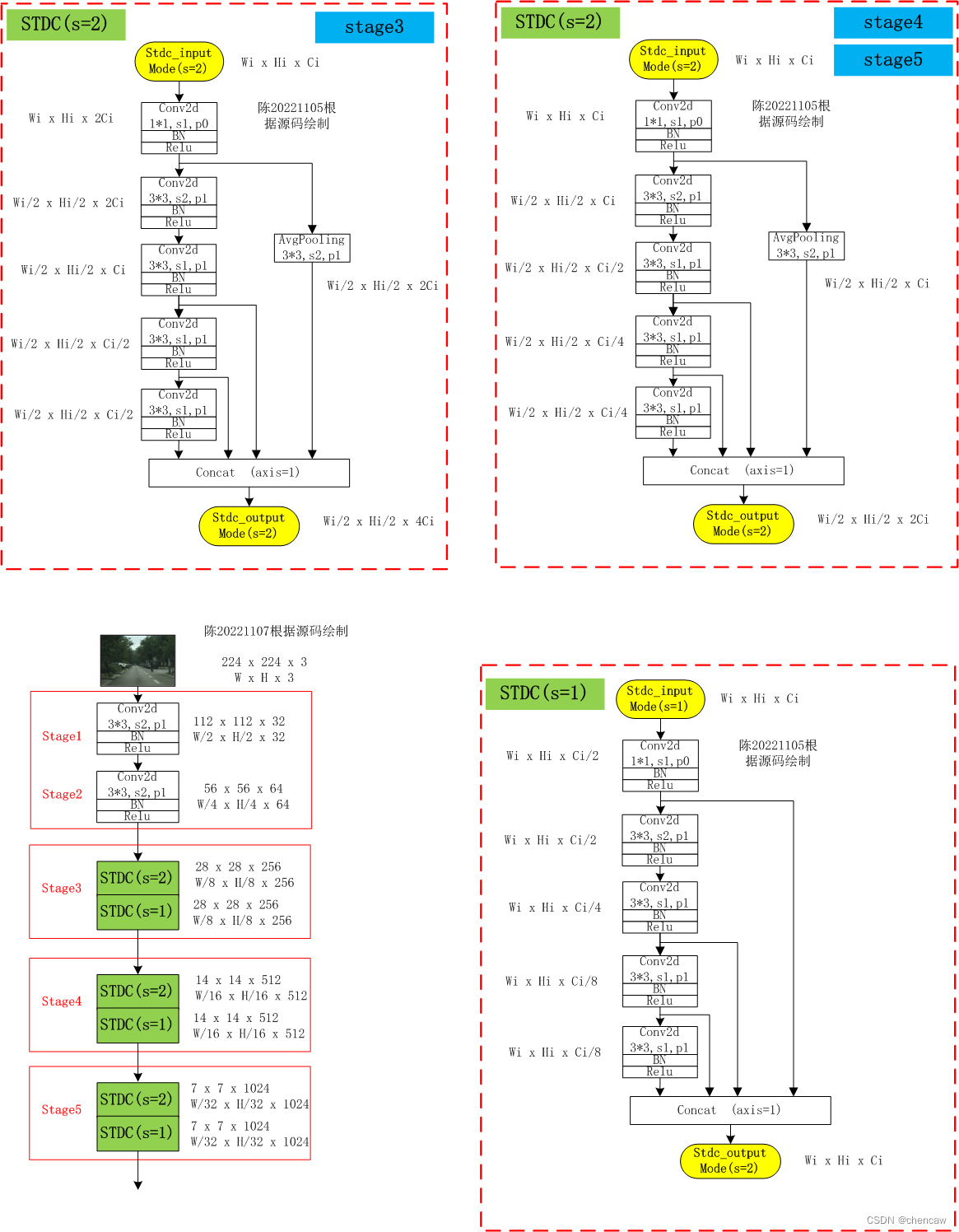
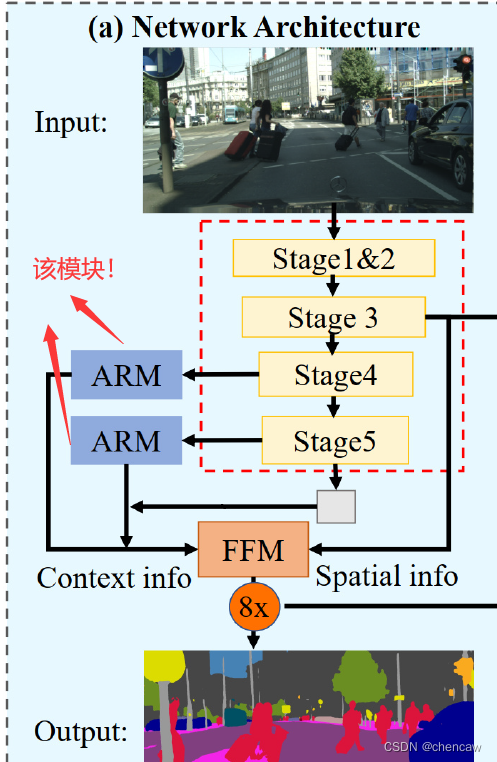
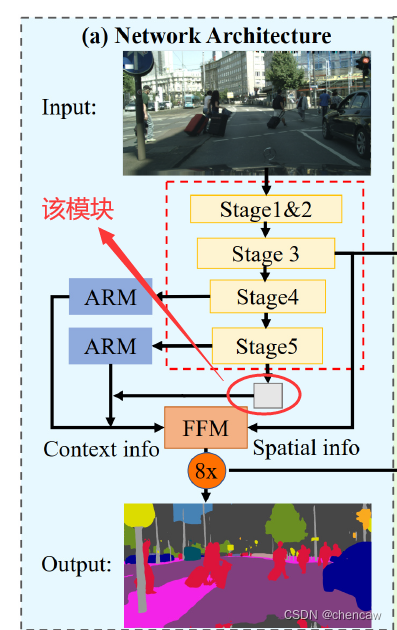
2.6.5 ARM模块的实现
(1)参考我的另一篇博客中的详细描述
(24)语义分割--BiSeNetV1 和 BiSeNetV2_chencaw的博客-优快云博客
(2)手绘图
注意:实际网络对应的输入通道排布为[B,C,W,H],我手绘的图都是使用了[W,H,C]
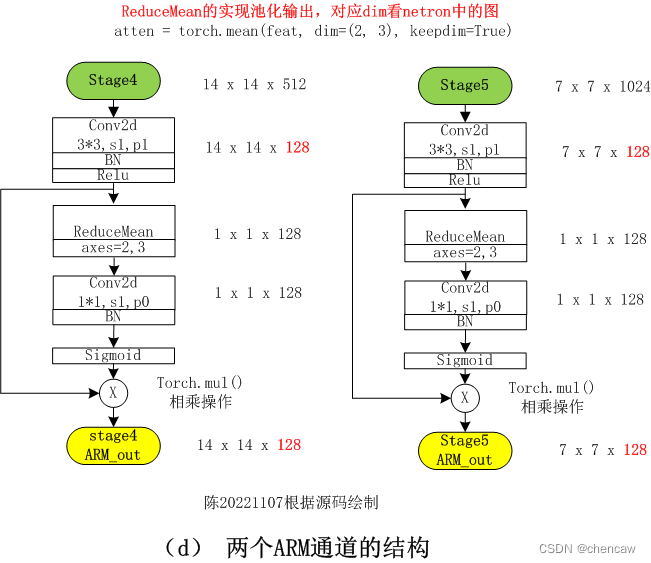
2.6.6 全局池化模块的输出
(1)对应的是如下模块
(2)测试代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import math
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = BatchNorm2d(out_chan)
# self.bn = BatchNorm2d(out_chan, activation='none')
# 原始定义
# torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
self.relu = nn.ReLU()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class Chen_Avg_Pool(nn.Module):
def __init__(self):
super(Chen_Avg_Pool, self).__init__()
inplanes = 1024
self.conv_avg = ConvBNReLU(inplanes, 128, ks=1, stride=1, padding=0)
# def forward(self, x):
def forward(self, feat32):
avg = F.avg_pool2d(feat32, feat32.size()[2:])
avg = self.conv_avg(avg)
return avg
def save_onnx(model,x,model_file_name):
torch_out = torch.onnx.export(model, x,
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
if __name__ == "__main__":
avgpool_net = Chen_Avg_Pool()
# x = torch.randn(16, 64, 56, 56)
x = torch.randn(16, 1024, 7, 7)
dt_out = avgpool_net(x)
print(dt_out.shape)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_avg_pool.onnx"
# #打印网络结构
summary(avgpool_net, input_size=(16, 1024, 7, 7))
# #保存为onnx
save_onnx(avgpool_net,x,model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
(3)手绘图
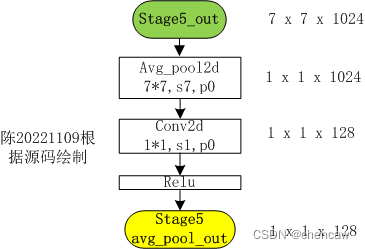
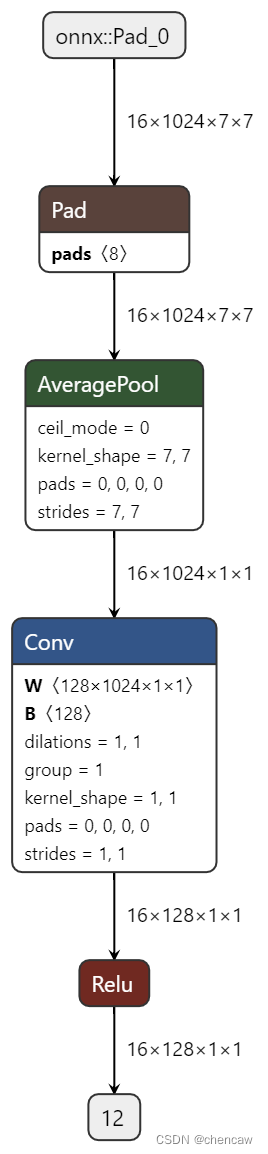
(4)netron导出图
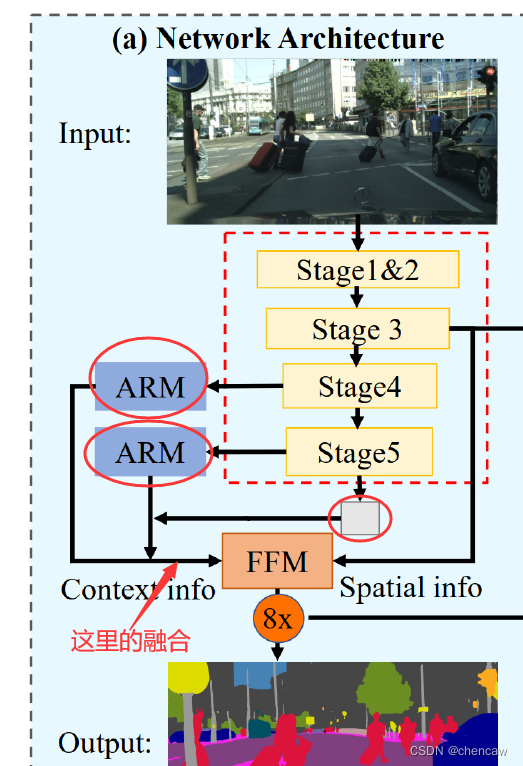
2.6.7 ARM模块和pooling输出模块的融合
(1)对应功能图如下
(2)测试代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import math
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = BatchNorm2d(out_chan)
# self.bn = BatchNorm2d(out_chan, activation='none')
# 原始定义
# torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
self.relu = nn.ReLU()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class Chen_Arm_Pool_Add(nn.Module):
def __init__(self):
super(Chen_Arm_Pool_Add, self).__init__()
# inplanes = 1024
# self.conv_avg = ConvBNReLU(inplanes, 128, ks=1, stride=1, padding=0)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
# def forward(self, x):
def forward(self, avg,feat32_arm,feat16_arm):
# H8, W8 = feat8.size()[2:]
# H16, W16 = feat16.size()[2:]
# H32, W32 = feat32.size()[2:]
H32 =7
W32 =7
H16 = 14
W16 =14
H8 =28
W8 =28
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
# feat32_arm = self.arm32(feat32)
feat32_sum = feat32_arm + avg_up
feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
feat32_up = self.conv_head32(feat32_up)
# feat16_arm = self.arm16(feat16)
feat16_sum = feat16_arm + feat32_up
feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
feat16_up = self.conv_head16(feat16_up)
return feat16_up, feat32_up # x8, x16
# def save_onnx(model,x,model_file_name):
# torch_out = torch.onnx.export(model, x,
# model_file_name,
# export_params=True,
# verbose=True)
def save_onnx(model,x1, x2,x3, model_file_name):
torch_out = torch.onnx.export(model, (x1, x2, x3),
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
def chen_size_test(x):
H32, W32 = x.size()[2:]
print(H32,W32)
if __name__ == "__main__":
# feat32 = torch.randn(16, 1024, 7, 7)
# chen_size_test(feat32)
arm_pool_add_net = Chen_Arm_Pool_Add()
# x = torch.randn(16, 64, 56, 56)
avg = torch.randn(16, 128, 1, 1)
feat32_arm = torch.randn(16, 128, 7, 7)
feat16_arm = torch.randn(16, 128, 14, 14)
dt_out = arm_pool_add_net(avg,feat32_arm,feat16_arm)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_avg_add_pool.onnx"
# # #打印网络结构
summary(arm_pool_add_net, input_size=[(16, 128, 1, 1), (16, 128, 7, 7), (16, 128, 14, 14)])
# # #保存为onnx
save_onnx(arm_pool_add_net,avg,feat32_arm,feat16_arm,model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
PS:手绘图,将2.6.8,陈20221115
2.6.8 语义分支的输出
(1)输出的内容包括
return feat2, feat4, feat8, feat16, feat16_up, feat32_up # x8, x16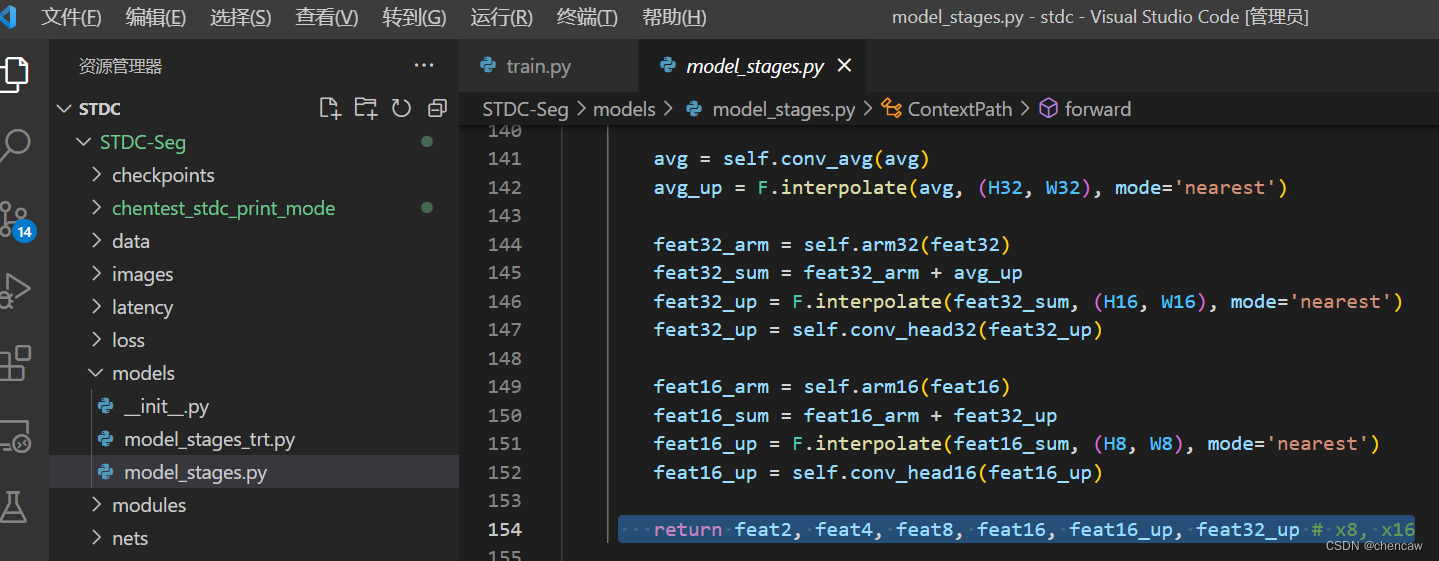 (2)测试代码
(2)测试代码
PS:见2.6.7的测试代码,陈20221115
(3)手绘的融合输出,对应上图中cp(语义分支)的6个输出
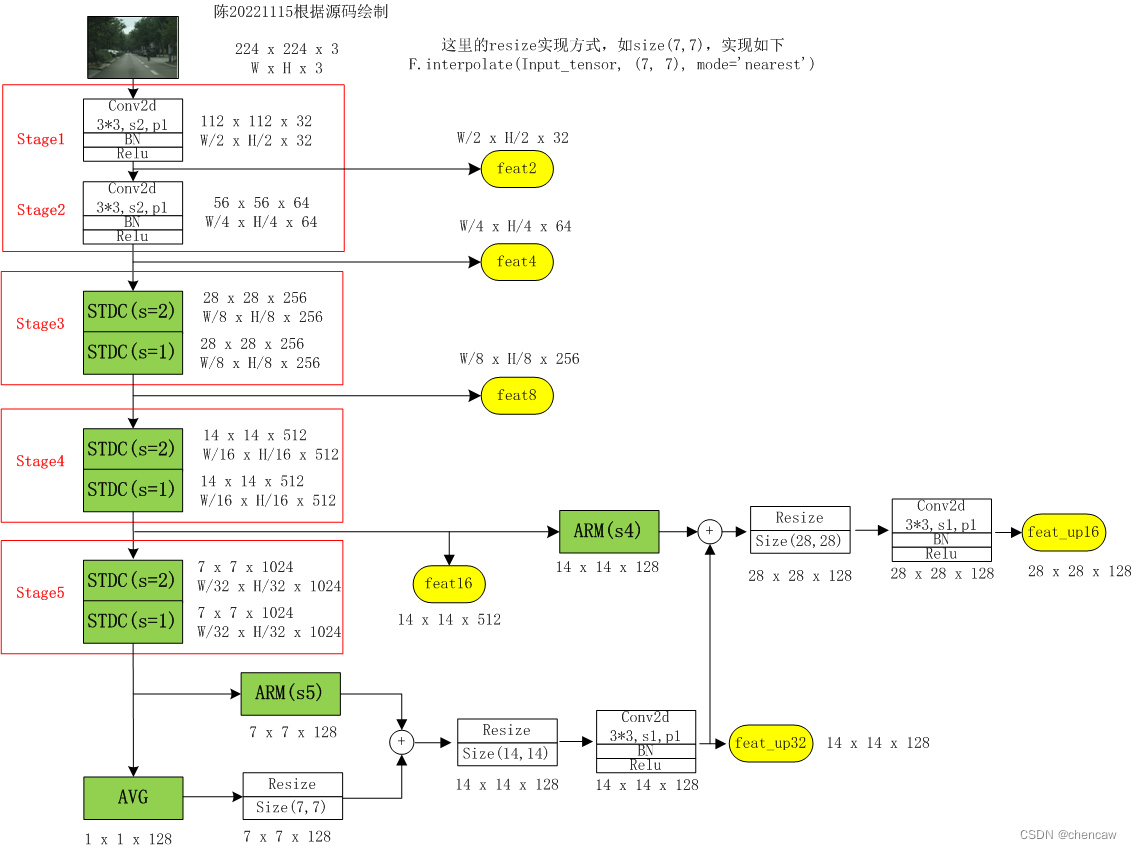
修改了一下,画的漂亮一点,如下所示:
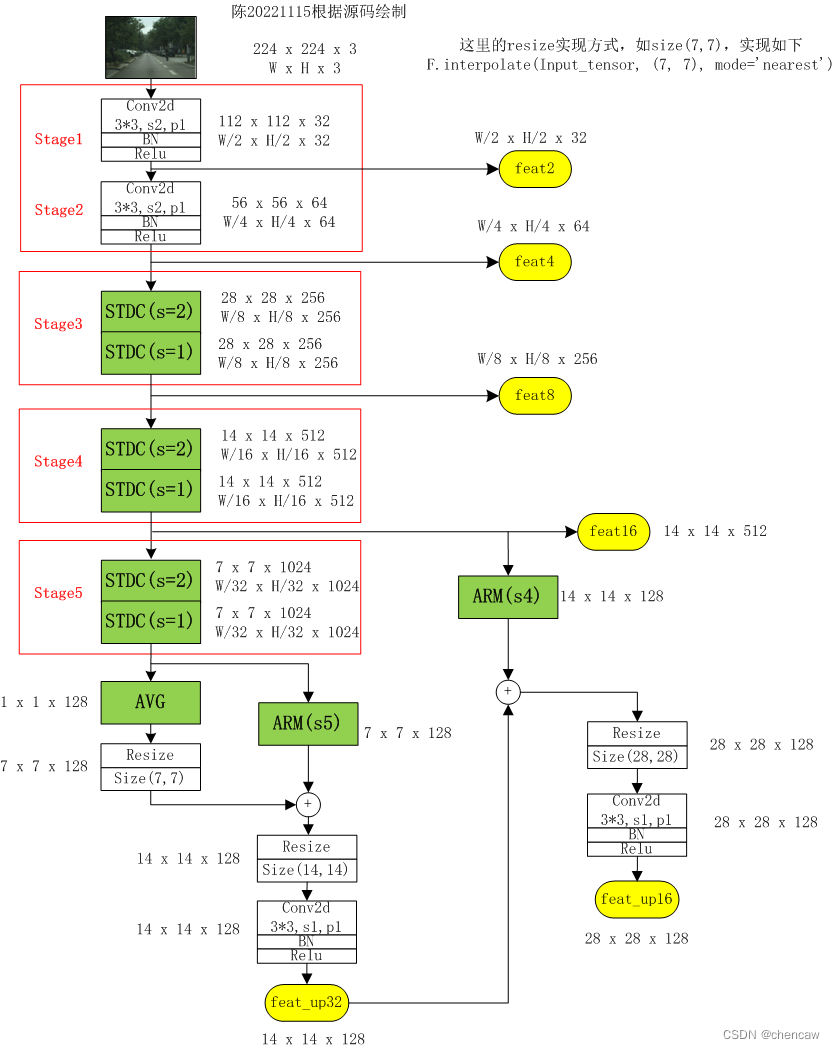
2.6.9 FFM模块
(1)对应位置如下
(2)测试一下,代码如下
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import math
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan,
out_chan//4,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.conv2 = nn.Conv2d(out_chan//4,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
print("fsp.shape",fsp.shape)
print("fcp.shape",fcp.shape)
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = BatchNorm2d(out_chan)
# self.bn = BatchNorm2d(out_chan, activation='none')
# 原始定义
# torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
self.relu = nn.ReLU()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class Chen_FFM(nn.Module):
def __init__(self):
super(Chen_FFM, self).__init__()
conv_out_inplanes = 128
sp8_inplanes = 256
inplane = sp8_inplanes + conv_out_inplanes
self.ffm = FeatureFusionModule(inplane, 256)
# def forward(self, x):
def forward(self, feat_res8,feat_cp8):
# 语义网络的6个输出,return feat2, feat4, feat8, feat16, feat16_up, feat32_up # x8, x16
# feat_res2, feat_res4, feat_res8, feat_res16, feat_cp8, feat_cp16 = self.cp(x)
# 所以,对应关系为:
# feat_res8 对应语义分割网络6个输出中的feat8
# feat_cp8 对应语义分割网络6个输出中的feat16_up,
feat_fuse = self.ffm(feat_res8, feat_cp8)
return feat_fuse
# def save_onnx(model,x,model_file_name):
# torch_out = torch.onnx.export(model, x,
# model_file_name,
# export_params=True,
# verbose=True)
def save_onnx(model,x1, x2, model_file_name):
torch_out = torch.onnx.export(model, (x1, x2),
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
def chen_size_test(x):
H32, W32 = x.size()[2:]
print(H32,W32)
if __name__ == "__main__":
# feat32 = torch.randn(16, 1024, 7, 7)
# chen_size_test(feat32)
ffm_net = Chen_FFM()
feat_res8 = torch.randn(16, 256, 28, 28) #对应feat8
feat_cp8 = torch.randn(16, 128, 28, 28) #对应feat16_up
dt_out = ffm_net(feat_res8,feat_cp8)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_ffm.onnx"
# # #打印网络结构
# summary(ffm_net, input_size=[(16, 256, 28, 28), (16, 128, 14, 14)])
# # #保存为onnx
save_onnx(ffm_net,feat_res8,feat_cp8,model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
(3)导出的netron图如下
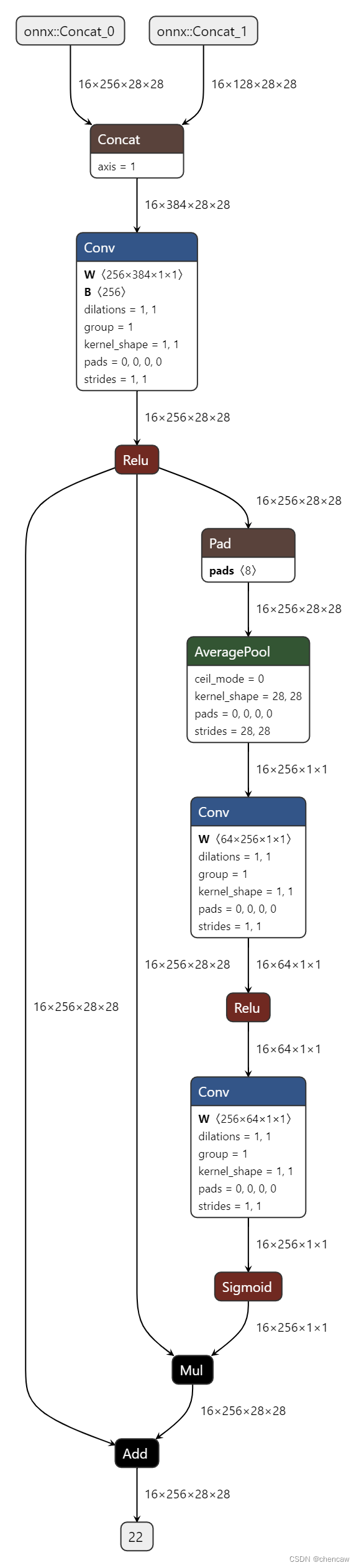
(4)PS:查看网络结构和发现和bisenetv1的FFM有些不一样,手绘图如下:
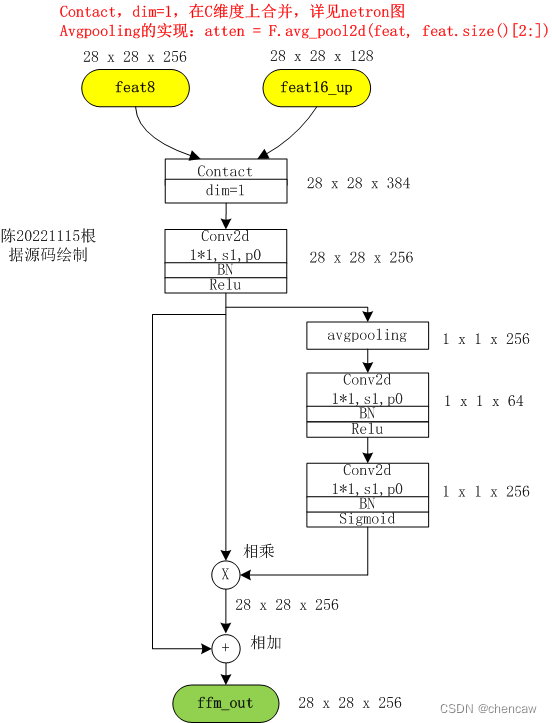
2.6.10网络的三个输出
(1)注意,网络中有一下几个参数
use_boundary_2,use_boundary_4,use_boundary_8,use_boundary_16
不过默认都是false
具体应用,有空再研究一下
(2)在上述默认参数下,网络的三个输出为:
return feat_out, feat_out16, feat_out32
(3)测试一下输出,测试代码如下
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import math
# from resnet import Resnet18
from torch.nn import BatchNorm2d
#清晰打印网络结构
from torchinfo import summary
#保存为onnx
import torch
import torch.onnx
from torch.autograd import Variable
#导出有尺寸
import onnx
# from onnx import shape_inference
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = BatchNorm2d(out_chan)
# self.bn = BatchNorm2d(out_chan, activation='none')
# 原始定义
# torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
self.relu = nn.ReLU()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
class BiSeNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
super(BiSeNetOutput, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.conv_out(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params
class Chen_Three_Out(nn.Module):
def __init__(self,n_classes):
super(Chen_Three_Out, self).__init__()
# n_classes = 19 #假设默认为19
conv_out_inplanes = 128
self.conv_out = BiSeNetOutput(256, 256, n_classes)
self.conv_out16 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
self.conv_out32 = BiSeNetOutput(conv_out_inplanes, 64, n_classes)
# def forward(self, x):
def forward(self, feat_fuse,feat_cp8,feat_cp16):
# 语义网络的6个输出,return feat2, feat4, feat8, feat16, feat16_up, feat32_up # x8, x16
# feat_res2, feat_res4, feat_res8, feat_res16, feat_cp8, feat_cp16 = self.cp(x)
# 所以,对应关系为:
# feat_cp8 对应语义分割网络6个输出中的feat16_up,
# feat_cp16 对应语义分割网络6个输出中的feat16_32,
# feat_fuse 为ffm的输出
H = 224
W = 224
# feat_fuse = self.ffm(feat_res8, feat_cp8)
feat_out = self.conv_out(feat_fuse)
feat_out16 = self.conv_out16(feat_cp8)
feat_out32 = self.conv_out32(feat_cp16)
feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
return feat_out, feat_out16, feat_out32
# def save_onnx(model,x,model_file_name):
# torch_out = torch.onnx.export(model, x,
# model_file_name,
# export_params=True,
# verbose=True)
def save_onnx(model,x1,x2,x3, model_file_name):
torch_out = torch.onnx.export(model, (x1, x2, x3),
model_file_name,
export_params=True,
verbose=True)
def save_scale_onnx(model_file_name):
model = model_file_name
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(model)), model)
def chen_size_test(x):
H32, W32 = x.size()[2:]
print(H32,W32)
if __name__ == "__main__":
stdc_three_out_net = Chen_Three_Out(19) #默认cityscape好像19分类
feat_fuse = torch.randn(16, 256, 28, 28)
feat_cp8 = torch.randn(16, 128, 28, 28)
feat_cp16 = torch.randn(16, 128, 14, 14)
dt_out = stdc_three_out_net(feat_fuse,feat_cp8,feat_cp16)
model_file_name = "D:/pytorch_learning2022/5chen_segement_test2022/stdc/STDC-Seg/chentest_stdc_print_mode/chen_stdc_three_out.onnx"
# # #打印网络结构
summary(stdc_three_out_net, input_size=[(16, 256, 28, 28), (16, 128, 28, 28), (16, 128, 14, 14)])
# # #保存为onnx
save_onnx(stdc_three_out_net, feat_fuse, feat_cp8, feat_cp16, model_file_name)
# #保存为onnx 有尺寸
save_scale_onnx(model_file_name)
(4)手绘输出图如下
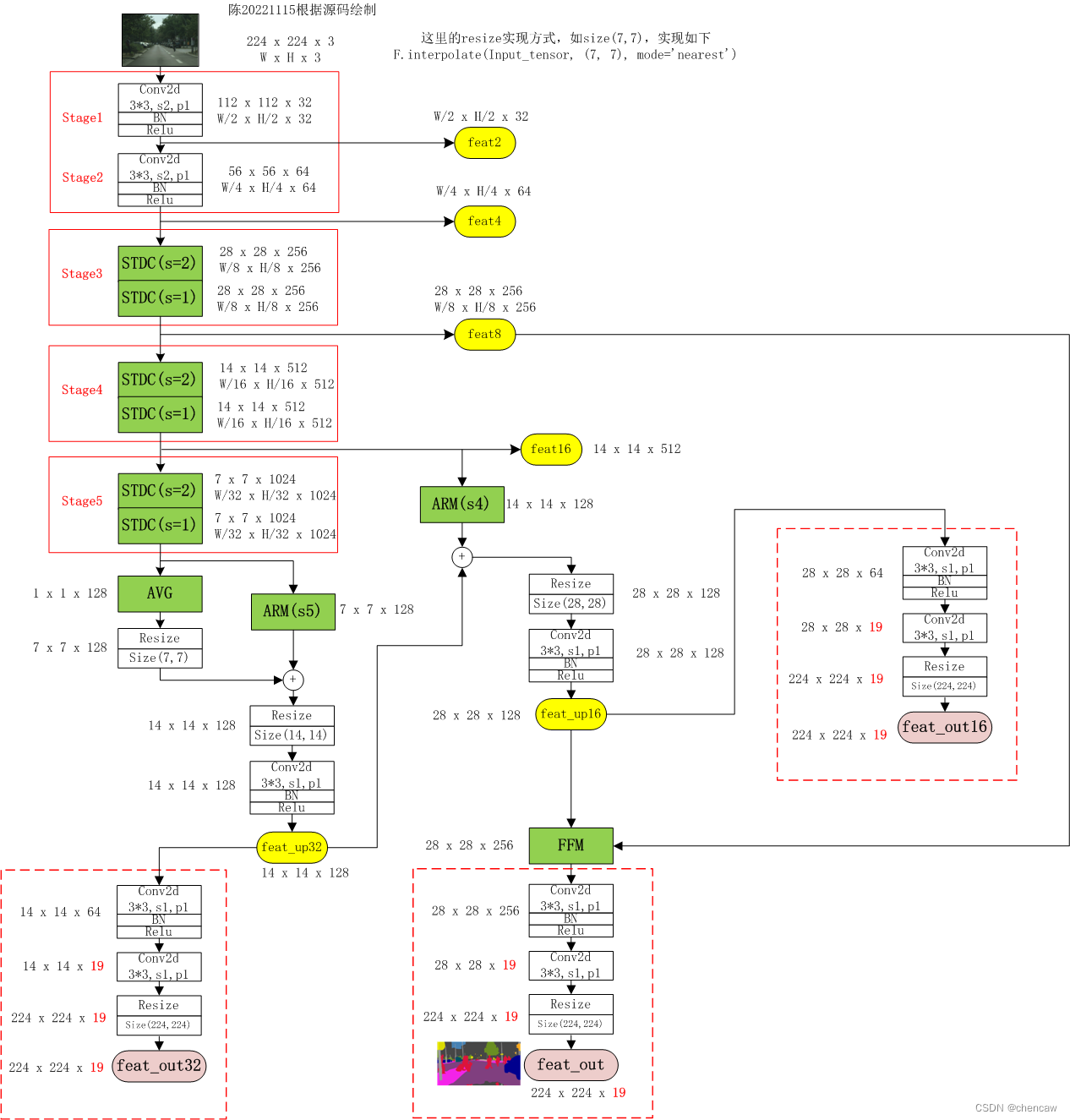
2.6.11 通过train文件中的loss看辅助训练输出头
(1)默认参数
use_boundary_2,use_boundary_4,use_boundary_8,use_boundary_16
默认都是false的时候,就是用了上述这三个输出的loss直接训练
(2)此时的代码为
if (not use_boundary_2) and (not use_boundary_4) and (not use_boundary_8):
out, out16, out32 = net(im)
lossp = criteria_p(out, lb)
loss2 = criteria_16(out16, lb)
loss3 = criteria_32(out32, lb)loss的定义参考另一篇博文
(28)语义分割--cross-entropy loss和OhemCELoss_chencaw的博客-优快云博客
score_thres = 0.7
n_min = n_img_per_gpu*cropsize[0]*cropsize[1]//16
criteria_p = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_16 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_32 = OhemCELoss(thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)(3)如果use_boundary_2,use_boundary_4,use_boundary_8,use_boundary_16为0的时候,

这里对应着
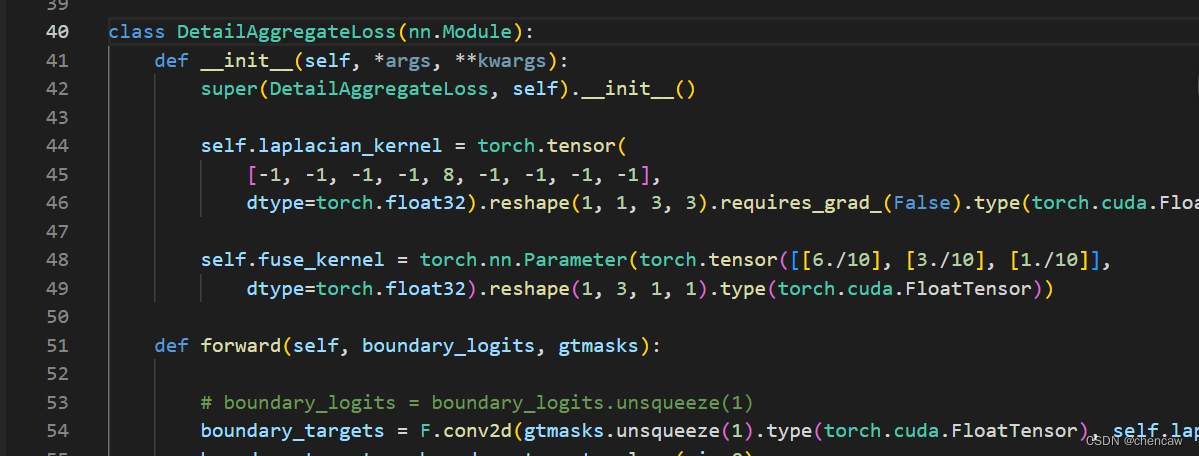
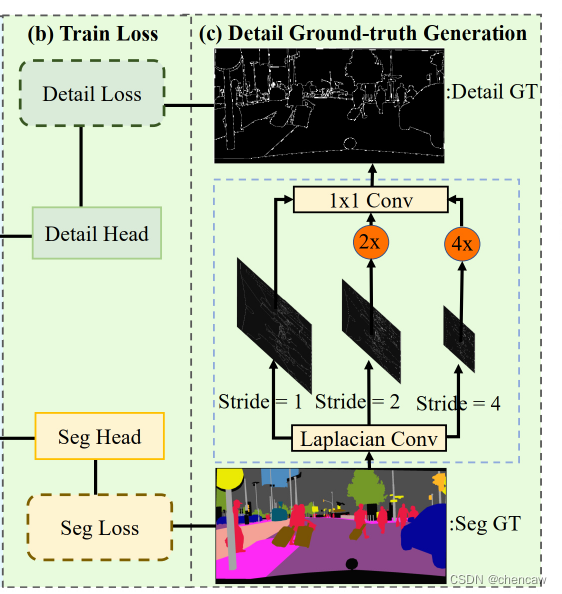
2.6.12 边缘细节的辅助监督
参考了
【语义分割】——STDC-Seg快又强 + 细节边缘的监督_wx6135db1f08cc4的技术博客_51CTO博客
项目采用边缘细节对语义分割网络进行辅助监督,同时,监督的是:网络前端 1/8的输出,(因为网络前端的细节信息更加丰富),边缘细节的 target 采用 拉普拉斯卷积核和语义label卷积得到。
这里卷积的时候,采用了stride=1,2,4三个不同的参数,然后再做了一个融合。
CVPR 2021 | 250 FPS!让实时语义分割飞起!重新思考BiSeNet_Amusi(CVer)的博客-优快云博客
通过detail Aggregation模块从语义分割ground truth中生成binary detail ground-truth,如图5(c)中虚线蓝框所示。这种运算可以通过2-D拉普拉斯核卷积和可训练的 卷积来实现。
首先,使用如图5(e)所示的Laplacian算子生成不同步幅的soft thin detail feature map以获取多尺度细节信息。
然后,我们将细节特征映射上采样到原始大小,并融合一个可训练的11 - 1卷积来进行动态重加权。
最后,利用边界和角点信息采用阈值0.1将预测细节转化为最终的binary detail ground-truth

















 2911
2911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









