




 本文探讨了在深度学习模型中,特别是在CNN、RNN和Self-Attention中,位置表示的重要性。绝对位置表示如BERT的使用存在局限性,而相对位置编码(RoPE)如进制编码提供了更好的扩展性和表示能力。文中还介绍了如何通过线性内插和NTK-aware方法来增强位置表示的灵活性和性能.
本文探讨了在深度学习模型中,特别是在CNN、RNN和Self-Attention中,位置表示的重要性。绝对位置表示如BERT的使用存在局限性,而相对位置编码(RoPE)如进制编码提供了更好的扩展性和表示能力。文中还介绍了如何通过线性内插和NTK-aware方法来增强位置表示的灵活性和性能.
为什么需要位置表示
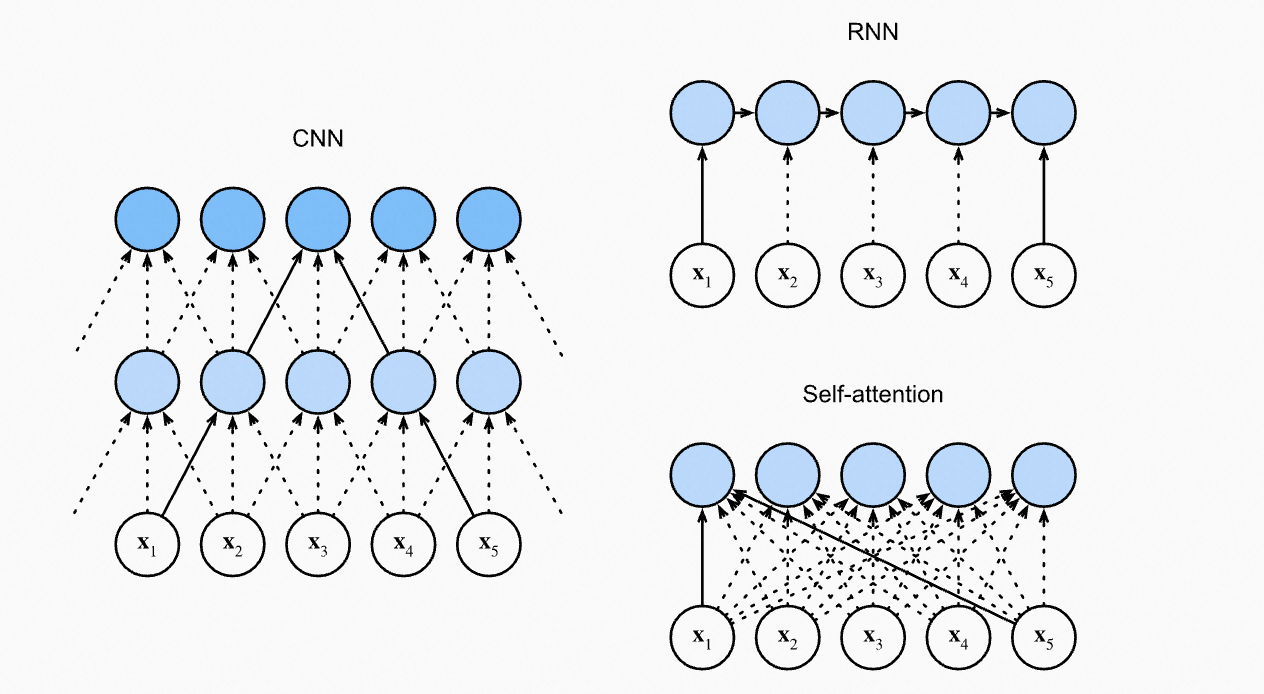
对比CNN、RNN和Self-Attention:
CNN处理相邻窗口的内容;RNN天然是序列操作,考虑了位置先后关系;Self-Attention的计算时是无序的,所以需要位置表示来知道Token之间的位置信息。
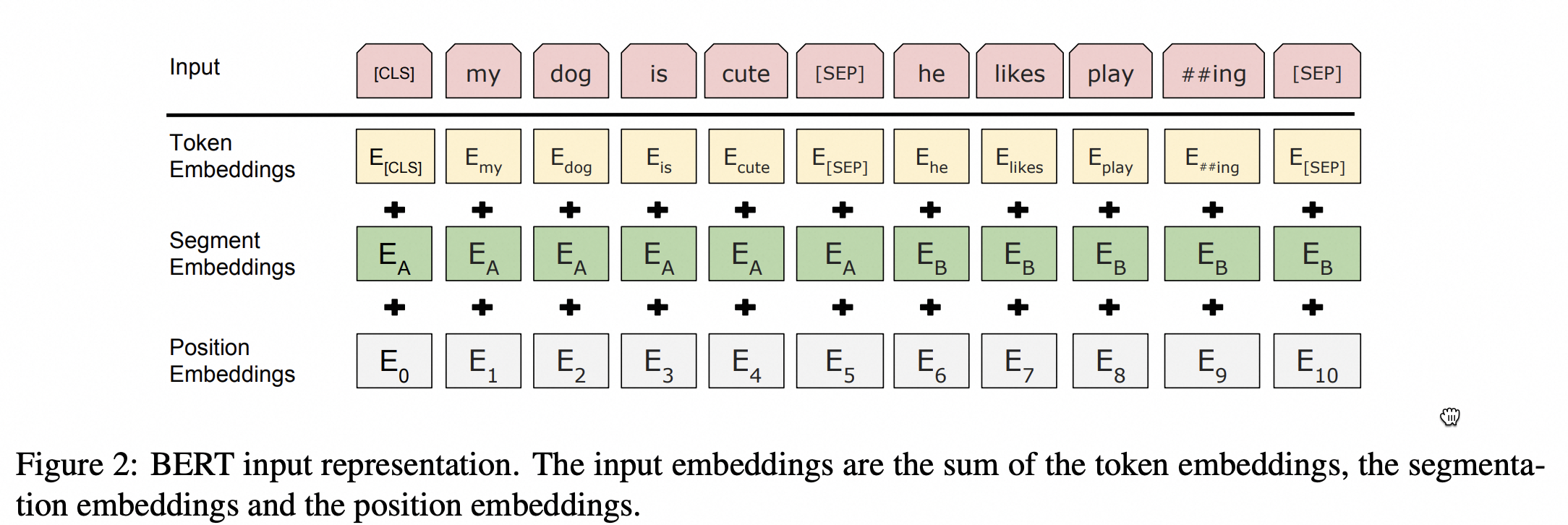
绝对位置表示
典型如:Bert/Roberta/GPT2的位置表示,将位置如 0~512 像词一样做embedding,需要训练position向量矩阵
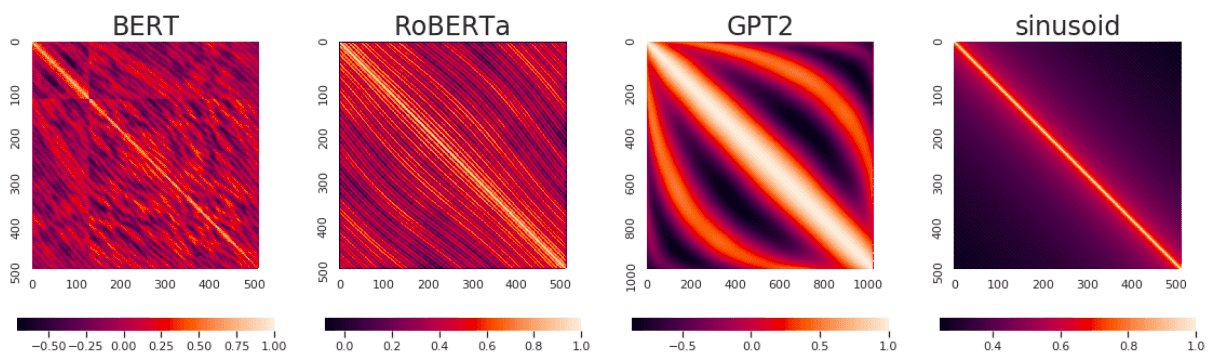
不同模型训练出来的位置表示之间的相似性,对角线是1
优势:简单
劣势:无法处理超出长度的句子,必须截断
相对位置表示
位置n的旋转位置编码(RoPE),本质上就是数字n的β进制编码!- 苏剑林
为什么需要进制编码?我们先看进制编码的格式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









