




 主动学习是半监督机器学习的一种形式,通过让算法选择要学习的数据,以减少对大规模标记数据集的依赖。它在标签密集型任务如自然语言处理中表现出色,常用策略包括最小置信度、边际采样和熵采样。应用场景包括Membership Query Synthesis、Stream-Based Selective Sampling和Pool-Based Sampling,用于提高模型学习效率。
主动学习是半监督机器学习的一种形式,通过让算法选择要学习的数据,以减少对大规模标记数据集的依赖。它在标签密集型任务如自然语言处理中表现出色,常用策略包括最小置信度、边际采样和熵采样。应用场景包括Membership Query Synthesis、Stream-Based Selective Sampling和Pool-Based Sampling,用于提高模型学习效率。
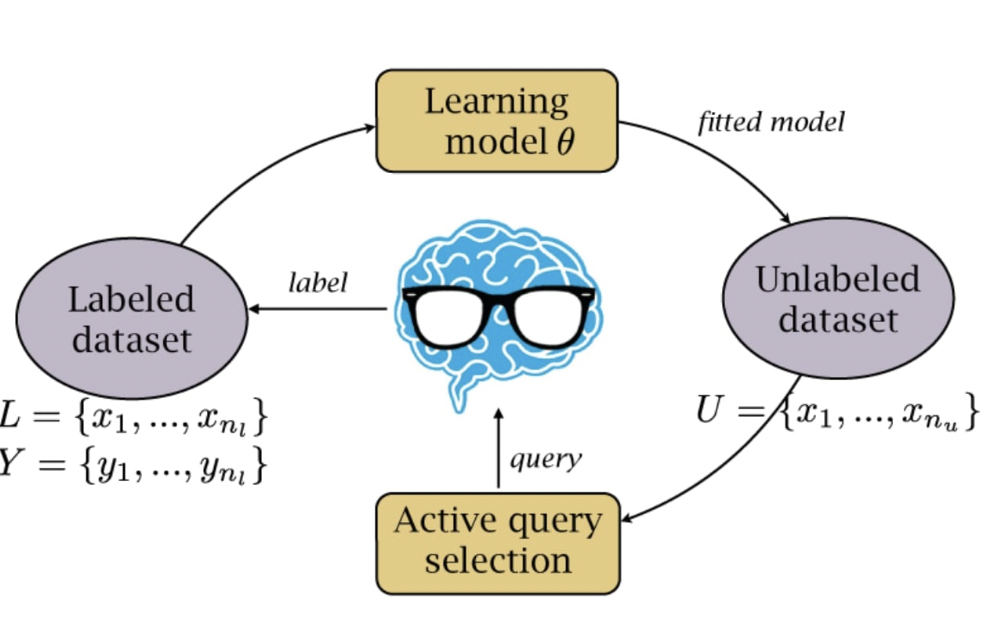
什么是Active Learning
主动学习(Active Learning)是半监督机器学习的一种形式,算法可以选择它想要学习的数据。
使用这种方法,程序可以主动查询权威来源,无论是程序员还是标记数据集,以学习对给定问题的正确预测。
目标:
这种迭代学习方法的目标是加快学习过程,特别是如果您没有大型标记数据集来练习传统的监督学习方法。
领域:
主动学习最流行的应用之一是标签密集型自然语言处理领域。 这种方法可以产生与监督学习相似的结果,但只需要一小部分人工的参与。
如何在实践中发挥作用?
有许多特定的查询策略,例如:
- 最小置信度、
- 边际采样
- 熵采样
主动学习 AI 只需要在三种广泛的场景中查询数据的正确标签。
Membership Query Synthesis
这是learning model从底层自然分布生成自己的实例的。例如,如果数据集是人类和动物的图片,leading model可以将截取的腿的图像发送给teacher model,并询问该附肢属于动物还是人类。如果您的数据集很小,这将特别有用。
Stream-Based Selective Sampling
每次检查每个未标记的数据,根据其查询参数评估每个样本的信息量。learing model自己决定是否为每个数据点分配标签label或查询teacher model,得到teacher的label。
Pool-Based Sampling
在这种情况下,从整个数据池中抽取实例并分配一个信息分数,衡量learning的“理解”数据的程度。然后系统选择信息量最大的实例并向learning model 查询,得到predict标签。


















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









