




逻辑回归原理
-
逻辑回归是用来二分类的!
-
是在线性回归模型之后加了一个激活函数(Sigmoid)将预测值归一化到【0~1】之间,变成概率值。
-
因此:逻辑回归=线性回归模型+sigmoid激活函数

-
对于二分类任务来说,一般计算其中一个类别的概率P,自然会得到另一个类别的概率1-P。
-
假如一个人是女生的概率是0.7,是男生的概率是多少呢?
- 自然是0.3。
- 那你会认为这个人是男生还是女生呢?
- 当时是女生!
-
一般认为概率最大的类别为分类结果。
损失函数
- MSE loss:计算数值之间的差异 (线性回归)
- BCE Loss:计算分布之间的差异(逻辑回归)


代码实现
# 导入必要的库
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 准备数据
x_data = [1.0], [2.0], [3.0]
y_data = [0], [0], [1]
# 创建并拟合逻辑回归模型
model = LogisticRegression()
model.fit(x_data, y_data )
# 在测试集上进行预测
y_pred = model.predict(x_data)# predict预测的是值,可能是:[0,0,1]
# 计算准确率
accuracy = accuracy_score(y_data, y_pred)
print("Accuracy:", accuracy)
# 绘制决策边界
x = np.linspace(0, 10, 200).reshape(-1,1)#变成200行,1列
y = model.predict_proba(x)[:, 1]#predict_proba预测的是类别为1的概率值,取值范围为:[0,1]概率值[0.2,0.3,0.8]
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r')#在概率=0.5时画一条红色直线;概率<0.5认为类别为0;概率>=0.5认为类别为1.
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()

练习
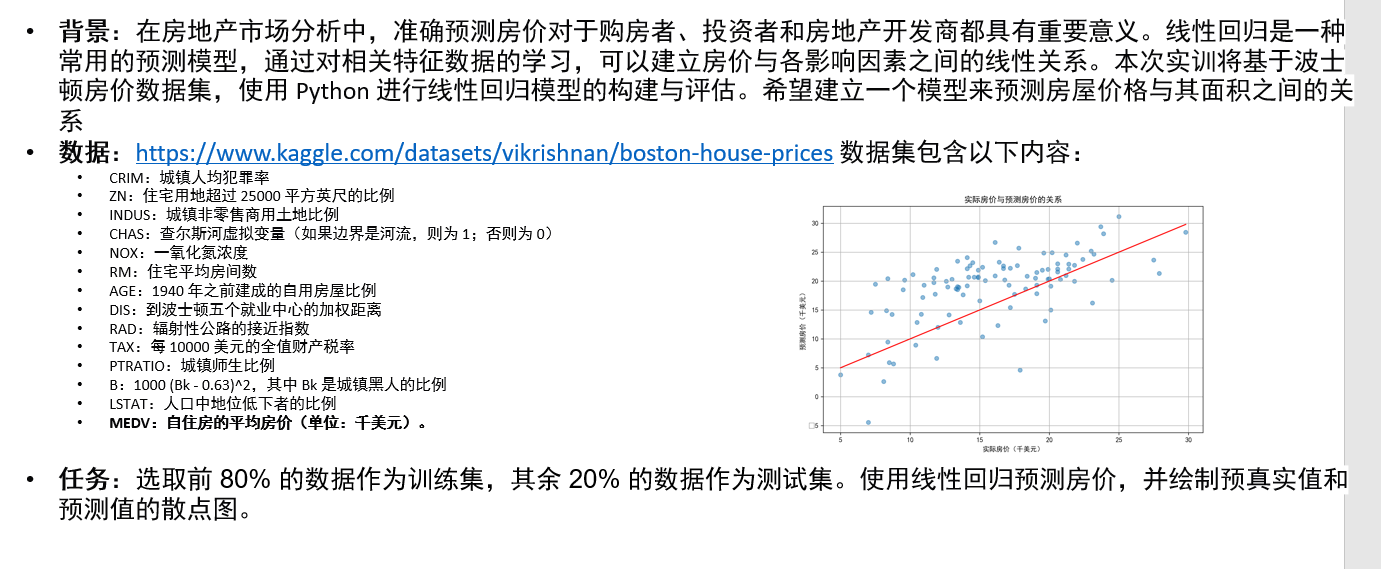
1. 波士顿房价预测
import pandas as pd
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import matplotlib
from sklearn.metrics import mean_squared_error
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
matplotlib.rcParams['font.family'] = 'sans-serif'
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
# 1.加载数据集
df = pd.read_csv('housing.csv', sep="\s+", header=None)
# 2.划分特征变量X和目标变量y
X = df.iloc[:, :-1].values # 选择所有特征列
y = df.iloc[:, -1].values # 选择目标列
# 3.手动划分训练集和测试集
train_size = int(len(df) * 0.8)
X_train = X[:train_size]
y_train = y[:train_size]
X_test = X[train_size:]
y_test = y[train_size:]
# 4.构建线性回归模型并训练
model = LinearRegression()
model.fit(X_train, y_train)
# 5.进行预测(测试集)
y_pred = model.predict(X_test)
# 6.计算mse loss
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
# 7.绘制实际房价和预测房价的散点图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
# 绘制对角线
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], color='red')
#对角线表示理想预测:这一条线能帮助直观地判断模型效果。
#点的分布:如果大部分点靠近这条线,说明预测效果较好;如果远离,则可能意味着需要对模型进行调整或改进。
plt.xlabel('实际房价(千美元)')
plt.ylabel('预测房价(千美元)')
plt.title('实际房价与预测房价的关系')
plt.grid()
plt.show()
2.基于学生特征的录取概率预测

import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, log_loss
from sklearn.preprocessing import LabelEncoder
# 1.加载训练集和测试集
train_data = pd.read_csv('data/train.csv')
test_data = pd.read_csv('data/test.csv')
# 2.数据预处理
# 填充训练集和测试集的 Age 列缺失值为均值
train_data['Age'] = train_data['Age'].fillna(train_data['Age'].mean())
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].mean())
# 填充测试集的 Fare 列缺失值为均值
test_data['Fare'] = test_data['Fare'].fillna(test_data['Fare'].mean())
# 填充训练集的 Embarked 列缺失值为众数
train_data['Embarked'] = train_data['Embarked'].fillna(train_data['Embarked'].mode()[0])
# 对 Sex 和 Embarked 列进行编码,进行编码是为了将分类变量转换为数值格式,以便可以被机器学习模型使用
label_encoder = LabelEncoder()
train_data['Sex'] = label_encoder.fit_transform(train_data['Sex'])
test_data['Sex'] = label_encoder.transform(test_data['Sex'])
train_data['Embarked'] = label_encoder.fit_transform(train_data['Embarked'])
test_data['Embarked'] = label_encoder.transform(test_data['Embarked'])
# 3.选择特征X_train、X_test 和目标变量y_train
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
X_train = train_data[features]
y_train = train_data['Survived']
X_test = test_data[features]
# 4.构建逻辑回归模型
model = LogisticRegression(max_iter=1000)#max_iter 的默认值通常是 100,用于指定优化算法的最大迭代次数。如果你发现模型没有收敛或性能较差,可以尝试增加此参数。
model.fit(X_train, y_train)
# 5. 在测试集上进行预测
y_pred = model.predict(X_test)
#y_pred_prob = model.predict_proba(X_test)[:, 1]
# 6.将预测结果和 PassengerId 合并为一个 DataFrame
result_df = pd.DataFrame({
'PassengerId': test_data['PassengerId'],
'Survived': y_pred
})
print('预测结果:')
print(result_df.head())
# 7.将预测结果保存为 CSV 文件
result_df.to_csv('data/titanic_prediction.csv', index=False)
线性回归和逻辑回归是机器学习的基础
分类和回归也是机器学习的两个最重要的分支!

















 4370
4370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









