




 本文深入探讨了可变形卷积网络(DCN)的两种版本:DCNv1和DCNv2。DCNv1通过学习卷积核的偏移量以适应不同特征,而DCNv2进一步引入了权重系数,允许模型学习采样点的权重,以减少无关信息的影响。此外,DCNv2还利用R-CNN的知识蒸馏优化FasterR-CNN。文中提供了DCN层的PyTorch实现代码,展示了如何在卷积层中应用可变形卷积。
本文深入探讨了可变形卷积网络(DCN)的两种版本:DCNv1和DCNv2。DCNv1通过学习卷积核的偏移量以适应不同特征,而DCNv2进一步引入了权重系数,允许模型学习采样点的权重,以减少无关信息的影响。此外,DCNv2还利用R-CNN的知识蒸馏优化FasterR-CNN。文中提供了DCN层的PyTorch实现代码,展示了如何在卷积层中应用可变形卷积。
1.DCNv1
可变形卷积顾名思义就是卷积的位置是可变形的,并非在传统的N × N的网格上做卷积,这样的好处就是更准确地提取到我们想要的特征(传统的卷积仅仅只能提取到矩形框的特征)
DCN v1的核心思想在于它认为卷积核不应该是一个简简单单的矩形
在不同的阶段,不同的特征图,甚至不同的像素点上都可能有其最优的卷积核结构。
因此DCN v1提出在方形卷积核上的每个点学习一个偏移(offset),卷积核可以根据不同的数据学习不同的卷积核结构,如图1所示。
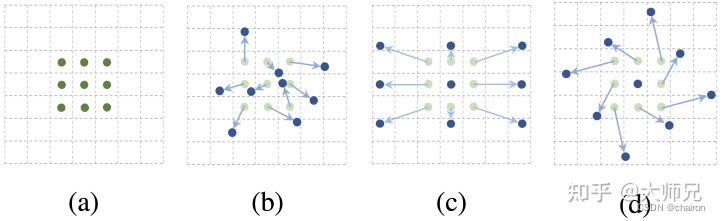
图1:可变形卷积核。(a)是标准的3×3卷积。(b),( c),(d)是给普通卷积加上偏移之后形成的可变形的卷积核,其中蓝色的是新的卷积点,箭头是位移方向。
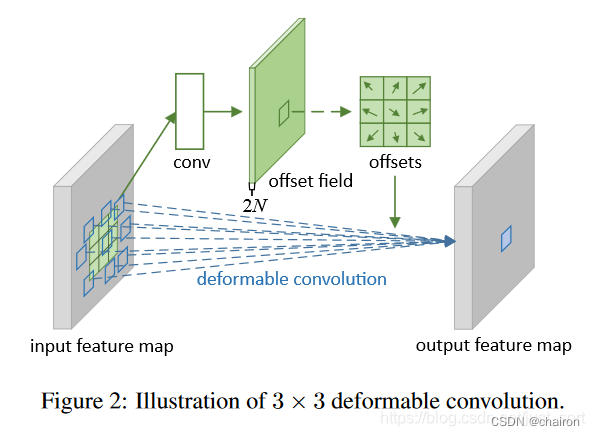
可变形卷积的结构可以分为上下两个部分:
- 上面那部分是基于输入的特征图生成x,y方向的offset
- 下面那部分是基于特征图和offset通过可变形卷积获得输出特征图
假设输入的特征图宽高分别为w,h,下面那部分的卷积核尺寸是 k h k_h kh和 k w k_w kw,那么上面那部分卷积层的卷积核数量应该是 2 ∗ k h ∗ k w 2*k_h*k_w 2∗kh∗kw,其中2代表x,y两个方向的offset。
并且,这里输出特征图的维度和输入特征图的维度一样,那么offset的维度就是[batch, k h k_h kh, k w k_w kw,h,w]
假设下面那部分设置了group参数(代码实现中默认为4),那么第一部分的卷积核数量就是 2 ∗ k h ∗ k w ∗ g r o u p 2*k_h*k_w*group 2∗kh∗kw∗group,即每一个group共用一套offset。下面的可变形卷积可以看作先基于上面那部分生成的offset做了一个插值操作,然后再执行普通的卷积。

具体实现的流程大概如下:
-
step1:求输入特征图 U U U(维度=[b,h,w,c])每个像素的偏移量:经过一个普通卷积,padding设置为same,对应的输出结果维度是[b,h,w,2c],记作 V V V。
-
将输入特征图 U U U中的像素索引值与V相加,得到偏移后的position(即在原始图片U中的坐标值),需要将position值限定为图片大小以内。position的大小为(bhw*2c),但position只是一个坐标值,而且还是float类型的,我们需要这些float类型的坐标值获取像素(双线性差值)。
- 举个例子:我们取一个坐标值,将其转换为四个整数floor(a), ceil(a), floor(b), ceil(b)。
- 将这四个整数进行整合,得到四对坐标(floor(a),floor(b)), ((floor(a),ceil(b)), ((ceil(a),floor(b)), ((ceil(a),ceil(b))。
- 这四对坐标每个坐标都对应 U U U中的一个像素值,而我们需要得到(a,b)的像素值,这里采用双线性差值的方式计算(一方面是因为获得的像素更精确,另外一方面是因为可以进行反向传播)。
-
在得到position的所有像素后,即得到了输出特征图 M M M,将这个新图片M作为输入数据输入到别的层中,如普通卷积。
2.DCNv2
- 增加更多的可变形卷积层
- 除了让模型学习采样点的偏移,还要学习每个采样点的权重,这是对减轻无关因素干扰的最重要的工作
- 使用R-CNN对Faster R-CNN进行知识蒸馏
- 目前只能实现3*3大小的卷积
更多的可变形卷积:
- 在DCN v2将conv3到conv5 block的 3*3卷积全部替换为了可变形卷积,因此可变形卷积层数达到了 12个。这一操作在场景更复杂的COCO数据集有着比较明显的性能提升。
加权采样点偏移:
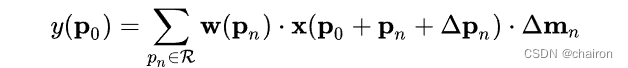
- DCNv2在DCNv1的基础上增加了一个权重系数 m m m,对卷积的在输入特征图上的采样点的偏移量计算权重,去除无关的上下文信息,对于某些不想要的采样点权重可以直接学习成0。
使用R-CNN对Faster R-CNN进行知识蒸馏:
- 在DCN v2中,作者使用了特征模仿(Feature Mimicking)的方式来用R-CNN对Faster R-CNN的优化。特征模仿是一个比较高级的模型迁移策略,它主要用在知识蒸馏中。
- 它先训练一个准确率比较高但是速度慢的大型的Teacher网络,然后再训练一个速度快但是泛化能力略差的小的Student网络。
- 在训练Student网络的过程中,模型不仅要优化它本身任务的损失函数,还要以Teacher网络学习到的特征为目标,优化它的中间的特征层。
- 因为Student网络的参数量是固定的,所以通过这个策略优化之后的Student网络不仅速度很快,而且能够达到了Teacher类似的准确率。
- DCN v2使用R-CNN来指导加了了可变形卷积的Faster R-CNN训练的目的是使可变形卷积能够自行的学到更好的采样点的偏移和权重,从而减少无关因素对模型的负面影响。
代码:
import torch
from torch import nn
from yolox.models.network_blocks import get_activation
class DeformConv2d(nn.Module):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2749
2749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









