






 FairMOT是一种在线多目标跟踪算法,基于Tracking-by-Detection策略,通过将JDE的YOLOv3主干替换成CenterNet,实现了检测方法从Anchor-base到Anchor-free的转变。改进后的算法在embeeding向量与目标位置匹配问题上有所缓解,提高了检测精度和效率。
FairMOT是一种在线多目标跟踪算法,基于Tracking-by-Detection策略,通过将JDE的YOLOv3主干替换成CenterNet,实现了检测方法从Anchor-base到Anchor-free的转变。改进后的算法在embeeding向量与目标位置匹配问题上有所缓解,提高了检测精度和效率。
简介
A Simple Baseline for Multi-Object Tracking是一个online的多目标跟踪(MOT)算法,基于TBD(Traking-by-Detection)的策略,FairMOT主要就是基于JDE做的改进,可以简单的理解为,FairMOT是将JDE的YOLOv3的主干,改成了CenterNet,也就是将检测的方法由Anchor-base换成了Anchor-free,然后同样在已有检测模型上加了了embeeding分支,模型输出检测的结果和embeeding,提供给后续的assiciation使用。
当然这样替换是有道理的,下面我们从原理的部分分析下为什么要这样做。
原理
contributions

FairMOT指出,anchor-base的网络在加入embeeding分支之后,容易造成embeeding向量与实际的目标位置不匹配的问题,其实说的就是JDE╮( ̄▽  ̄)╭。而改为anchor-free方法之后,这种不匹配问题会得到缓解。这是为什么呢?
首先我们需要知道embeeding headmap是啥样的,embeeding headmap和其他特征图有着同样的w和h,但是在channel通道上,不管是128还是512,都不在提供任何其他的信息了。也就是说embeeding headmap的w*h上,每一个点会直接对应到原图一个目标,如果这个点恰好和原图上目标位置偏差比较大,就会不一致了。那么为什么anchor-base的结构很容易不一致,而anchor-free可以改善呢?
本质上是两种方法采样倍率的不一致,像上图左侧的图,注意上面的白色格子很稀疏,这是因为anchor-base的下采样倍率很高,一般在16倍左右构建多尺度,而anchor-free不需要这么大的采样倍率,一般是4,这意味着同样的输入,anchor-free比anchor-base的head map的size大4倍,映射回原图,就是稠密了16倍,当然可以有改善作用了,也就是这个原因,作者决定将anchor-base换成anchor-free,采用了centernet。
Inference
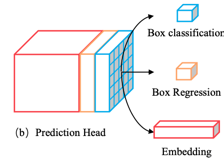
有了上面这个前提,其余的FairMOT和JDE的就非常非常像了,FairMOT同样有两类分支,一类是用来预测,和centernet一致,一类的embedding,加起来一个有四个:
- center results : 1 × H × W 1\times H\times W 1×H×W
- center offset results : 2 × H × W 2\times H\times W 2×H×W
- bbox size results: 2 × H × W 2\times H\times W 2×H×W
- dense embedding map: D × H × W D\times H\times W D×H×W
embedding特征图的厚度是D。这种分支的形式就联合了检测模型和Re-ID模型,将两者合并为一个。
而assiciation的部分和JDE更是完全一致的。
Train
FairMOT的训练数据和JDE是一致的,一共由6个数据集构成,其中有三个数据没有提供PID信息,只提供了检测信息。
| 数据集 | 论文 | 描述 | 图像数量 | ID数量 |
|---|---|---|---|---|
| PRW | 《Person Re-identification in the Wild》 | The PRW dataset is annotated from the same video as the Market-1501 dataset, i.e., captured with 6 cameras in the summer of 2014 in Tsinghua University. We have annotated 11,816 video frames, 932 identities belonging to 34,304 bounding boxes. | 5701 | 933 |
| MOT17 | MOT16的增强版,MOT16重复的数据从MOT117中剔除 | 5316 | 547 | |
| ETHZ | 《Robust Multi-Person Tracking from Mobile Platforms》 | 2056 | 0 | |
| CUHK-SYSU | 《End-to-End Deep Learning for Person Search》 | 11206 | 11931 | |
| cityperson | 2500 | 0 | ||
| caltech | 《Caltech Pedestrian Detection Benchmark》 | About 250,000 frames (in 137 approximately minute long segments) with a total of 350,000 bounding boxes and 2300 unique pedestrians were annotated. | 26729 | 1043 |
训练的损失函数有三个:
还是分为centernet的损失和embedding的损失:
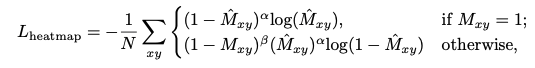
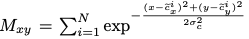
其中centernet的center的损失和cornernet是一致的。
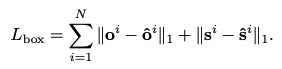
offset和xy的损失就是L1。
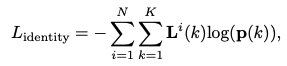
embeeding的损失是交叉熵。
实验结果
embeeding实验结果
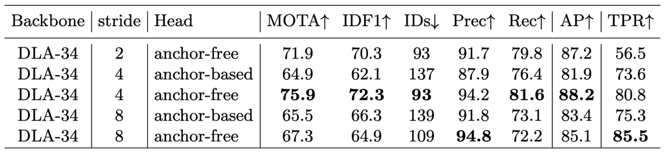
在embeeding实验中,FairMOT比较了DLA-34 backbone下不同采样倍率下的anchor-base和anchor-free方法的ReID的效果,但是从这个实验本身是有问题的。
四倍的下采用样对于anchor-base的检测方法不合理,只有一个尺度的8倍下采样anchor-base的检测方法不合理,YOLOv3和JDE都使用8,16和32三个尺度的下采样倍率,单尺度和4倍的下采样是CenterNet的改进之一,DLA是否适用于anchor-base?在CenterNet前,没人用DLA作为检测的backbone;
综合上述几点,这个实验对anchor-base是不公平的。
MOT实验结果

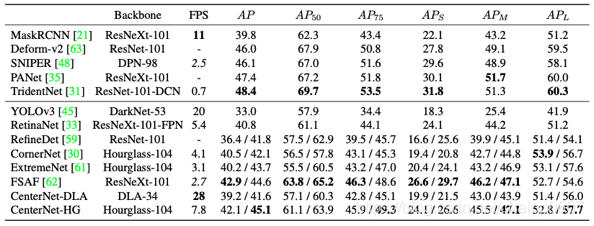
上面这个表格比较了MOT challenge两个数据集上JDE和FairMOT的实验结果,MOTA和效率都有提高,但是需要注意的一点是,在之前MOT:通用性能评价标准提到,对于TBD策略的MOT算法,一个优秀的检测器本身就对最后效果有促进作用,所以我们可以看下CenterNet和YOLOv3的检测对比,同样是效果和效率都有提示,所以FairMOT本身就占了检测器的便宜。
总结
最后,不论如何,FairMOT最终的效果是不错的,而且提供了JDE策略在anchor-free模型上的范式,对于两个已有方法的合理组合,达到了1+1>2的效果。


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









