






为什么需要使用大模型辅助召回?
通过向量召回的方式从文档库里召回和用户问题相关的文档片段,同时输入到LLM中,增强模型回答质量。
常用的方式直接用用户的问题进行文档召回。但是很多时候,用户的问题十分口语化,描述的也比较模糊,这样会影响向量的质量,进而影响模型回答的效果。
策略一:HYDE
介绍一下HYDE思路?
1、用LLM根据用户Query生成k个“假答案”。(大模型生成答案采用sample模式,保证生成的k个答案不一样。此时的回答内容很可能是存在知识性错误,因为如果能回答正确,那就不需要召回补充额外知识。)
2、利用向量化模型,生成的k个假答案和用户Query变成向量;
3、将k+1个向量取平均:其中dk为第k个生成的答案,q为用户的问题,f为向量化操作。
4、利用融合向量v从文档库中召回答案。融合向量中既有用户的问题信息,也有想要答案的模式信息,可以增强召回效果。
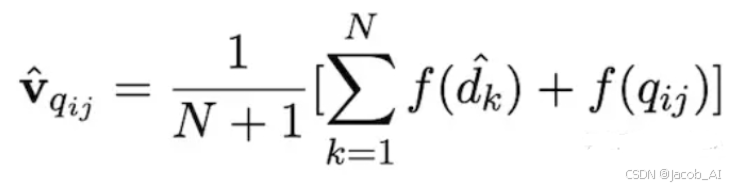
策略二:FLARE
为什么需要FLARE?
对于大模型外挂知识库,通常的做法是根据用的Query一次召回文档片段,让模型生成答案。只进行一次文档召回在长文本生成的场景下效果往往不是很好,生成的文本过长,有可能扩展出和Query相关性较弱的内容,如果模型没有这部分内容,容易产生模型幻觉问题。一种解决思路是随着文本的生成,多次从向量库中召回内容。
FLARE有哪些召回策略?
1、每生成固定的n个token就召回一次;
2、每生成一个完整的句子就召回一次;
3、用户Query一步步分解为子问题,需要解答当前子问题时候,就召回一次;
已有的多次召回方案比较被动,召回文档的目的是为了得到模型不知道的信息,1、2策略并不能够保证不需要找回的时候不召回,需要召回的时候触发召回。3方案需要设计特定的Prompt工程,限制了其通用性;

















 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









