





 超级会员免费看
超级会员免费看

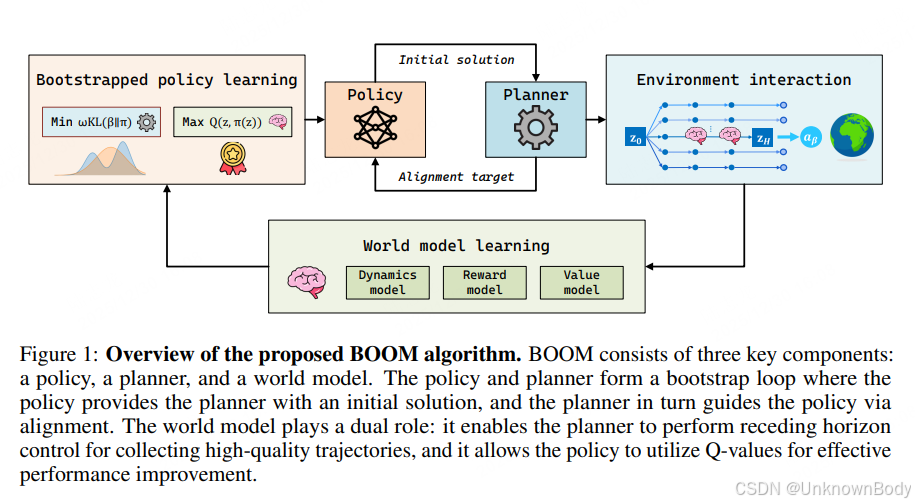
文章核心总结与翻译
一、主要内容
本文针对基于模型的强化学习(MBRL)中在线规划与离线策略学习结合时存在的智能体分歧(actor divergence) 问题,提出了BOOM(Bootstrap Off-policy with WOrld Model)框架。该框架通过 Bootstrap 循环紧密整合规划与离线策略学习:策略为规划器提供初始解,规划器通过模型预测优化精炼动作,再通过行为对齐引导策略更新,同时联合学习的世界模型为规划器提供轨迹模拟能力,为策略优化提供价值目标。
在 DeepMind Control Suite 和 Humanoid-Bench 两大高维连续控制基准的14项任务中,BOOM 均实现了最先进(SOTA)的训练稳定性和最终性能,显著优于 SAC、DreamerV3、TD-MPC2 等主流基线方法。
二、创新点
- 无似然对齐损失(likelihood-free alignment loss):针对在线规划器的非参数化动作分布,通过最小化前向 KL 散度,在无需显式获取规划器动作似然的情况下,实现策略与规划器行为的对齐。
- 软价值加权机制(soft value-weighted mechanism):基于学习到的 Q 函数对回放缓

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











