





 超级会员免费看
超级会员免费看

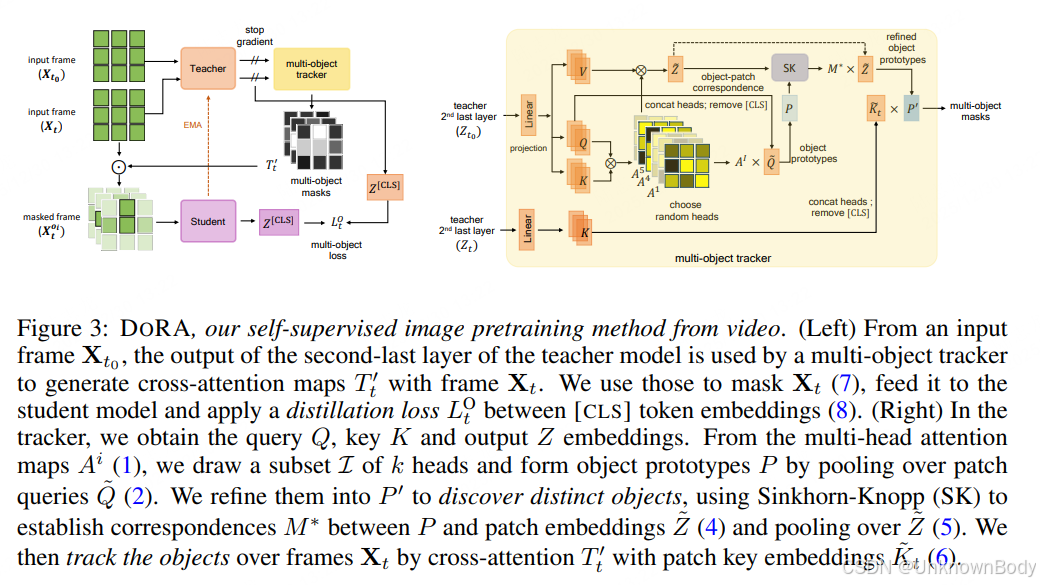
文章总结与翻译
一、主要内容
该研究聚焦自监督学习中数据利用效率的提升,核心探索“单段长时无标签视频能否媲美ImageNet用于图像编码器训练”这一问题,主要内容包括三方面:
- 数据集构建:提出“Walking Tours(WT)”数据集,包含10段第一人称视角(以城市漫步为主,含野生动物 safari)的4K高清视频,单段时长59分钟-2小时55分钟,无剪辑、无人工标注,涵盖丰富物体、动作、自然场景与光照过渡,兼具真实性与语义密度。
- 方法创新:设计自监督预训练方法DORA,以“先跟踪再识别”为核心,基于Transformer交叉注意力机制,端到端实现物体的自动发现与跨帧跟踪;通过Sinkhorn-Knopp聚类优化目标补丁对应关系,生成多样化跟踪目标视图,并结合蒸馏损失完成训练,无需额外目标检测器或光流网络。
- 实验验证:在图像分类、语义分割、目标检测、视频目标分割等多个下游任务中验证,单段WT视频预训练的DORA性能媲美甚至超越ImageNet预训练的DINO等主流方法,全10段视频预训练后性能进一步提升,证实长时连续视频在自监督学习中的高效价值。
二、创新点
- 数据层面

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











