








 超级会员免费看
超级会员免费看

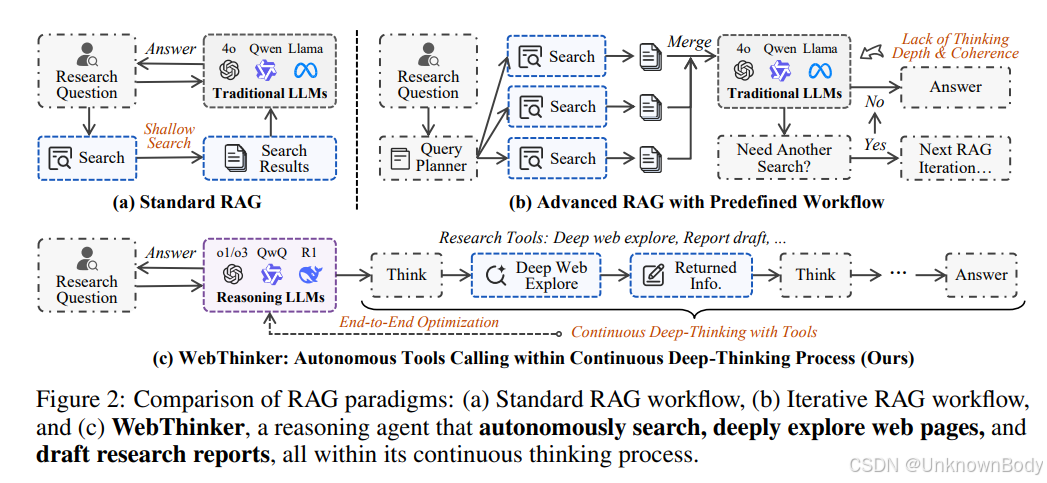
- 主要内容
- 研究背景:大推理模型(LRMs)在复杂信息研究任务中存在局限,现有开源深度搜索代理的预定义工作流程限制了其探索网络信息的能力,开发通用、灵活的开源深度研究框架迫在眉睫。
- 相关工作:介绍LRMs和检索增强生成(RAG)的研究现状,指出LRMs依赖静态内部知识,RAG在复杂推理场景和综合报告撰写任务中存在不足。
- 方法:提出WebThinker框架,包含问题解决模式和报告生成模式。前者利用深度网络探索器(Deep Web Explorer)解决复杂推理任务;后者通过自主思考 - 搜索 - 起草(Autonomous Think-Search-and-Draft)策略生成综合报告。同时,采用基于强化学习的训练策略优化模型。
- 实验:在复杂推理基准测试(如GPQA、GAIA等)和科学报告生成任务(Glaive)上评估WebThinker,对比多种基线方法。结果表明WebThinker性能卓越,且在不同LRM骨干模型上具有良好适应性。
- 创新点
- 自主研究能力:WebThinker能在思考过程中自主搜索、深度探索网页并起草研究报告,实现端到端任

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











