








 超级会员免费看
超级会员免费看

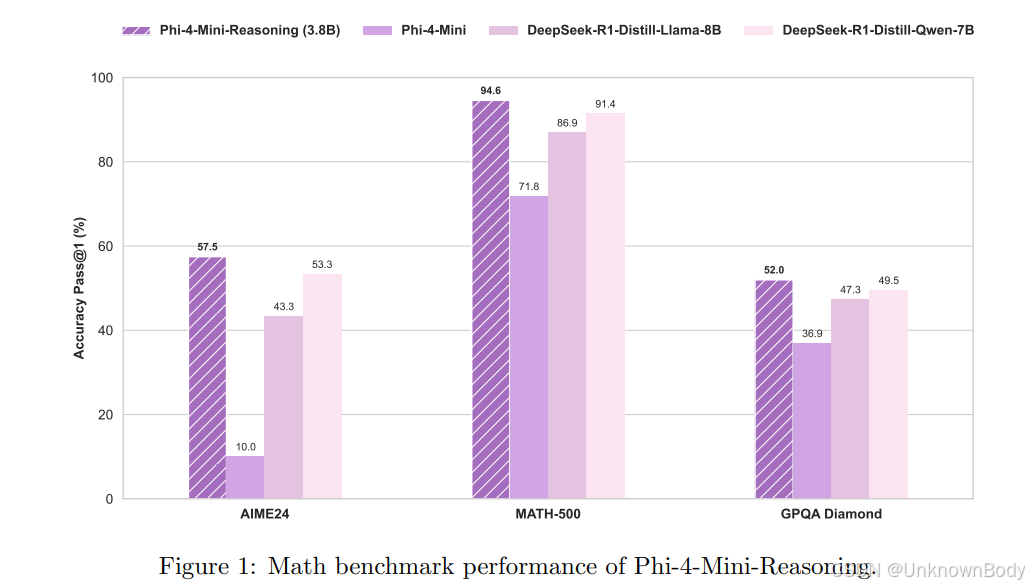
主要内容
- 研究背景:大语言模型(LLMs)在自然语言处理任务中表现出色,但在处理复杂多步问题时推理能力受限,思维链(CoT)方法可提升其推理能力。小语言模型(SLMs)提升推理能力面临挑战,虽有研究表明蒸馏可改善其推理性能,但有效蒸馏策略尚未明确,且简单应用孤立技术可能导致性能下降。
- 多阶段持续训练方法
- 蒸馏作为中间训练:使用Deepseek - R1模型生成的合成思维链数据,对基础模型进行下一令牌预测训练,以赋予基础模型通用的CoT推理能力。
- 蒸馏作为监督微调:从中间训练数据集中选择紧凑且具代表性的子集进行微调,构建涵盖不同数学领域、难度超过“大学水平”的数据集,提升模型性能和泛化能力。
- Rollout偏好学习:利用被过滤掉的错误输出构建偏好数据集,通过直接偏好优化(DPO)提升模型性能。
- 带可验证奖励的强化学习(RL):在蒸馏和偏好训练后的模型上进行RL,介绍了近端策略优化(PPO)、基于组的相对策略优化(GRPO)等算法,并针对训练中出现的问题提出提示优化、奖励重平衡和温度退火等改进方法。
- 合成CoT数据生成

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2137
2137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











