








 超级会员免费看
超级会员免费看

主要内容
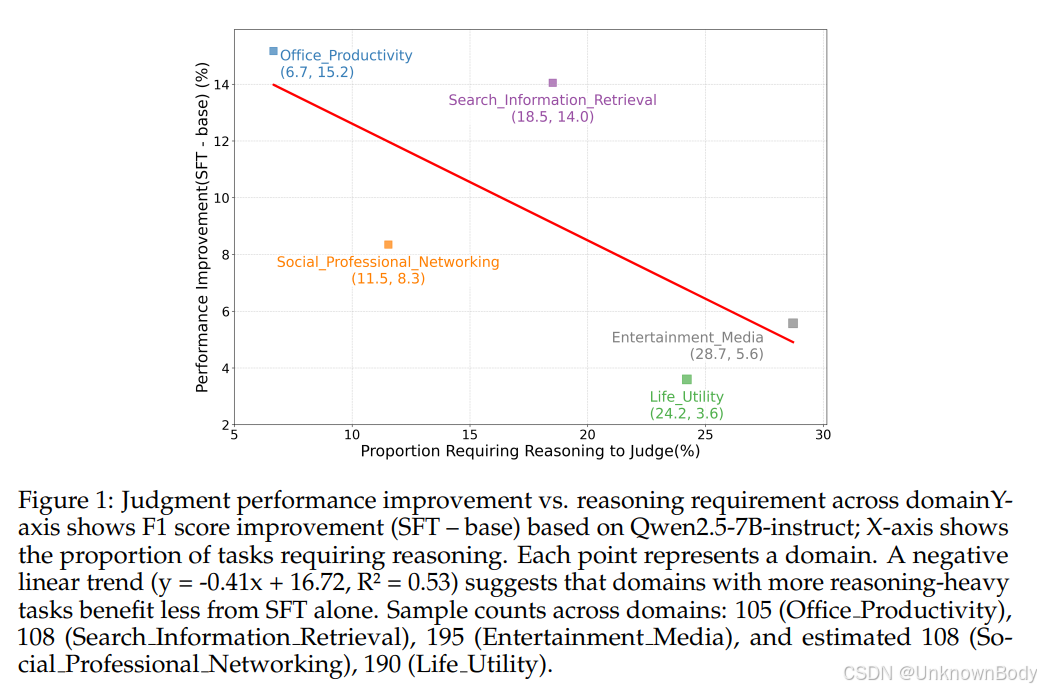
本文探讨了将大型语言模型(LLM)作为评估者(judge)时面临的挑战,特别是监督微调(SFT)在复杂推理任务中的局限性。通过分析评估任务的推理需求,发现SFT的性能提升与高推理需求样本的比例呈负相关,表明SFT在深度推理任务中效果不佳。为解决这一问题,提出了JudgeLRM,一种通过强化学习(RL)训练的面向判断的大型推理模型(LRM)。JudgeLRM设计了基于结果的奖励函数,结合结构奖励(确保推理格式规范)和内容奖励(对齐真实判断偏好),有效提升了模型在高推理需求任务中的评估能力。实验结果显示,JudgeLRM在多个基准测试中显著优于SFT模型和现有先进推理模型,如JudgeLRM-3B超越GPT-4,JudgeLRM-7B在F1分数上比DeepSeek-R1高2.79%,尤其在需要深度推理的判断任务中表现突出。研究还通过案例分析揭示了判断任务中关键的推理行为(如验证、子目标设定、错误识别等),强调判断本质上是推理密集型任务,而非简单的评分过程。
创新点
- 发现SFT的推理局限性:通过实证分析,首次揭示SFT在高推理需求任务中的性能下降趋势,证明传统监督微调无法有效提升模型的判断推理能力。
- 提出JudgeLRM框架:基于强化学习设计了面向判断任务的奖励机制,结合结构和内容奖励,促使模型生成结构化推理路径和准确判断,突破了SFT的局限

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3192
3192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











