








 超级会员免费看
超级会员免费看

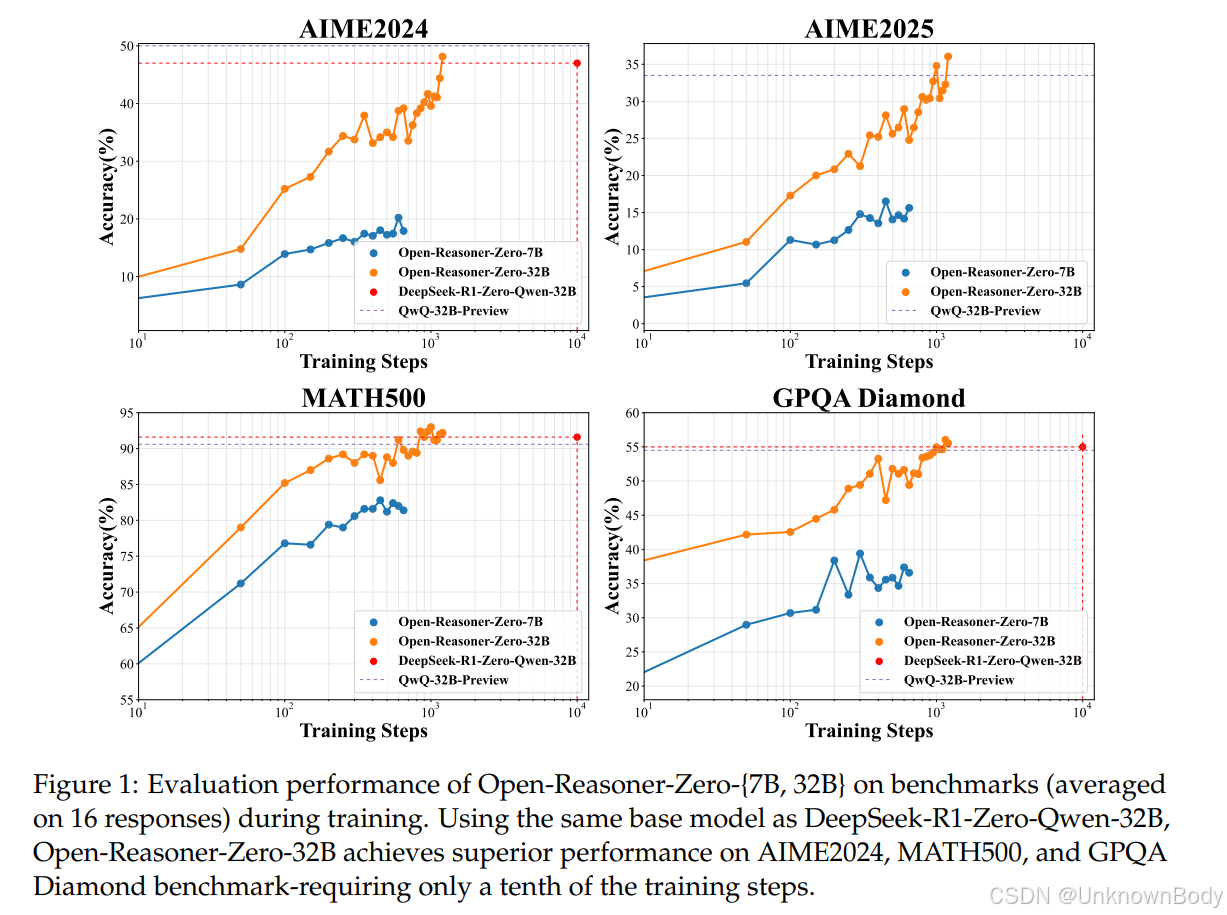
主要内容
- 研究目标:提出首个开源的大规模推理导向强化学习(RL)训练框架Open-Reasoner-Zero(ORZ),聚焦可扩展性、简单性和可访问性,直接在基础模型上进行RL训练以提升复杂推理能力。
- 核心方法:
- 算法:使用香草近端策略优化(PPO)算法,结合广义优势估计(GAE),参数设置为λ=1、γ=1,无需KL正则化。
- 奖励函数:基于规则的简单二元奖励(正确答案得1,否则0),使用Math-Verify库验证数学答案正确性,避免复杂奖励工程。
- 数据集:精心筛选和合成约129k数学和推理任务样本,通过模型过滤策略确保数据质量,并针对困难样本进行针对性训练。
- 关键发现:
- 简单PPO算法和规则奖励函数足以实现响应长度和基准性能的稳定扩展,与DeepSeek-R1-Zero相比,训练步骤减少至1/10,性能更优。
- 数据规模和模型规模是提升推理能力的关键,无饱和迹象,小模型(如0.5B)也能实现有效改进。
- 实验结果:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











