







《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书
对于VQ-VAE的具体应用,我们提出一种称为有限标量量化(FSQ)的简单方案来替换VQ-VAE中的向量量化(VQ)。这个新方案希望解决传统VQ中存在的两个主要问题:
- 消除辅助损失。
- 提高码本利用率。
有限标量量化(Finite Scalar Quantization,FSQ)的离散化思路非常简单,就是“四舍五入”。
13.3.1 FSQ算法简介与实现
将VAE表示投影到少量维度(通常少于10)。每个维度被量化为一组固定的值,由这些数值集合的乘积给出(隐式的)码本(codebook)。

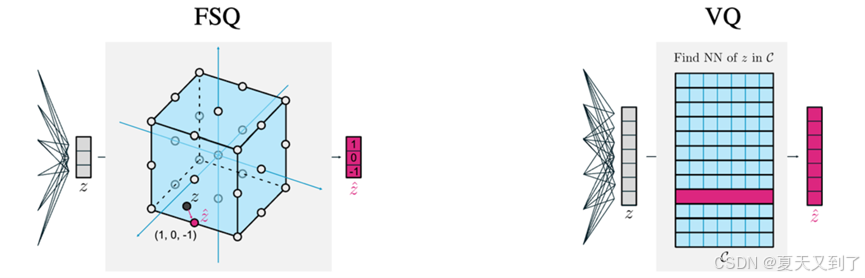 图13-6 FSQ与VQ算法
图13-6 FSQ与VQ算法
对于具体训练,FSQ在使用重构损失训练的自动编码器中,我们获得了对编码器的梯度,这迫使模型将信息分散到多个quantization bins中,因为这减少了重构损失。最终结果是,我们获得了一个使用所有码字的量化器,而不需要任何辅助损失。
尽管FSQ的设计要简单得多,但本文在图像生成、多模态生成、深度估计等任务中获得了有竞争力的结果。FSQ的优点是不会遭受码本坍塌(codebook collapse),并且不需要VQ中为了避免码本坍塌而使用的复杂机制(承诺损失、码本重新播种、码分割、熵惩罚等)
下面是一个FSQ的具体实现,读者可以参考学习:
class FSQ(nn.Module):
def __init__(self, levels, dim, num_codebooks, ...):
self.levels = levels # 例如[8, 5, 5, 5]
self.dim = dim # token的长度,例如1024
self.num_codebooks = num_codebooks #codebook的数量,RVQ相关
#是否需要Factorized codes技巧
self.need_project = True if dim != len(levels) else False
if self.need_project:
self.project_down = nn.Linear(dim, len(levels))
self.project_up = nn.Linear(len(levels), dim)
def forward(self, z_e, return_indices = False):
# 判断是否是视频(四维度向量,转换成二维度)
....
if self.need_project:
z = self.project_down(z_e)
codes = self.quantizer(z)
indices = None
if return_indices:
indices = self.code_to_indices(codes) # 请移步github repo查看
out = self.project_up(codes)
# 视频数据特殊处理
....
return codes if not return_indices else (codes, indices)
def bound(self, z):
'''
levels的下标是从0开始的,所以要减1;除2是为了得到half_l方便在[-half_l, half_l]上
进行缩放区间
最终的目的是要把levels中的每个数都缩放到[-half_l, half_l]的区间,
并且按照level中的不同number等分
'''
half_l = (self.levels - 1) * (1 + eps) / 2
# 奇数天然就关于某个数对称,但是偶数不对称,因此我们需要一个offset来处理偶数
offset = torch.where(self.levels % 2 == 0, 0.5, 0.0)
'''
将一个区间缩放到[-1, 1]使用tanh函数,因此我们需要让我们区间可以被tanh所处理,
能够覆盖[-1, 1]。
因此使用atanh函数对shift进行处理
'''
shift = (offset / half_l).atanh()
# (z + shift).tanh()缩放至[-1, 1]
# 乘 half_l - offset缩放至[-half_l, half_l]
return (z + shift).tanh() * half_l - offset
def round_ste(self, z):
zhat = z.round() #量化
return z + (zhat - z).detach()#VQ保证梯度传播的基本操作
def quantizer(self, z):
quantized = self.round_ste(self.bound(z))
half_width = self.levels // 2
return quantized / half_width # Renormalize to [-1, 1].
13.3.2 人脸数据集的准备
我们最终将使用FSQ完成人脸的生成。首先就是完成人脸数据集的获取,这里直接使用kaggle提供的数据集下载地址直接完成数据集的下载,这个人脸数据集的安装命令如下:
pip install kagglehub
人脸数据集的下载,代码如下所示。
import kagglehub
#Download latest version
path = kagglehub.dataset_download("badasstechie/celebahq-resized-256x256")
print("Path to dataset files:", path)
上面代码可以直接下载人脸数据集,读者也可以在随书附带的源码中获取相应的人脸数据。
下一步就是人脸数据集的载入。我们可以通过载入人脸数据地址的方法来读取相应的内容,代码如下所示。
import os
import einops
import torchvision
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
from torchvision import transforms
import glob
class CelebADataset(Dataset):
def __init__(self, folder_path = "./dataset/celeba_hq_256/", img_shape=(128, 128)):
super().__init__()
self.img_shape = img_shape
self.filenames = []
# 遍历文件夹中的文件
for filename in os.listdir(folder_path):
if filename.endswith('.jpg'):
# 打印文件的完整路径
self.filenames.append(os.path.join(folder_path, filename))
def __len__(self) -> int:
return len(self.filenames)
def __getitem__(self, index: int):
path = self.filenames[index]
img = Image.open(path)
pipeline = transforms.Compose([
transforms.CenterCrop(168),
transforms.Resize(self.img_shape),
transforms.ToTensor()
])
return pipeline(img)
上面代码用于载入人脸数据,并通过transforms模块对人脸数据的维度进行调整。
13.3.3 基于FSQ的人脸重建方案
接下来考虑基于FSQ的人脸重建方案。这里使用的编码器以及解码器,我们都可以使用13.2节中已经实现的解码器和编码器,并修正其中的vq部分,代码如下所示。
import torch,einops
import encoder
import decoder
import config
from vector_quantize_pytorch import VectorQuantize
import quantizer
from vector_quantize_pytorch import FSQ
class Tokenizer(torch.nn.Module):
def __init__(self, config = config.Config()):
super(Tokenizer, self).__init__()
self.config = config
self.image_size = config.image_size
self.patch_size = config.patch_size
self.grid_size = self.image_size // self.patch_size
scale = config.d_model ** -0.5
self.latent_tokens_enc = torch.nn.Parameter(scale * torch.randn(self.grid_size ** 2, config.d_model))
self.latent_tokens_dec = torch.nn.Parameter(scale * torch.randn(self.grid_size ** 2, config.d_model))
self.positional_embedding = torch.nn.Parameter(scale * torch.randn(self.grid_size ** 2, config.d_model)) # [ 7*7, 384 ]
self.latent_token_positional_embedding = torch.nn.Parameter(scale * torch.randn(self.grid_size ** 2, config.d_model))
self.encoder = encoder.Encoder(config,self.positional_embedding, self.latent_token_positional_embedding)
self.decoder = decoder.Decoder(config,self.positional_embedding, self.latent_token_positional_embedding)
self.vq = FSQ(dim = config.token_dim,levels = [8, 5, 5, 5])
#模型训练用
def forward(self, x):
z_q,indices = self.encode(x,self.latent_tokens_enc)
decoded_imaged = self.decoder(z_q,self.latent_tokens_dec)
return decoded_imaged
def encode(self, x,latent_tokens):
embedding = self.encoder(x,latent_tokens)
quantized, indices = self.vq(embedding)
return quantized,indices
def decode_tokens(self, tokens):
z_q = self.vq.get_codes_from_indices(tokens)
return self.decoder(z_q)
上面代码只输出重建的部分。而对于vq本身的损失,我们可以根据文本的输出损失进行计算。对应的训练代码如下所示。
import tokenizer
import math
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
import config
device = "cuda"
model = tokenizer.Tokenizer(config=config.Config())
model.to(device)
save_path = "./saver/ViLT_generator.pth"
model.load_state_dict(torch.load(save_path),strict=False)
BATCH_SIZE = 32
seq_len = 49
import get_face_dataset
train_dataset = get_face_dataset.CelebADataset()
train_loader = (DataLoader(train_dataset, batch_size=BATCH_SIZE,shuffle=True))
optimizer = torch.optim.AdamW(model.parameters(), lr = 2e-4)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max = 12000,eta_min=2e-7,last_epoch=-1)
criterion = torch.nn.MSELoss()
latent_loss_weight = 0.25
for epoch in range(2):
pbar = tqdm(train_loader,total=len(train_loader))
for inputs in pbar:
optimizer.zero_grad()
inputs = inputs.to(device)
imaged = model(inputs)
reconstruction_loss = criterion(imaged, inputs)
autoencoder_loss = reconstruction_loss
autoencoder_loss.backward()
optimizer.step()
lr_scheduler.step() # 执行优化器
pbar.set_description(f"epoch:{epoch +1}, train_loss:{autoencoder_loss.item():.5f}, lr:{lr_scheduler.get_last_lr()[0]*1000:.5f}")
if (epoch+1) % 3 == 0:
torch.save(model.state_dict(), save_path)
torch.save(model.state_dict(), save_path)
读者可以自行尝试进行模型训练,在此过程中需要注意的是,由于本章我们实现的是图像的生成任务,对资源耗费比较大。因此在训练时需要根据自身硬件配置对batch_size的大小进行相应调整,以确保训练能够顺利进行。


















 6145
6145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









