






摘要
本文深入探讨了机器人操作系统2(ROS2)的日志管理系统,并提出了将其与时序数据库(Time-Series Database, TSDB)集成的高阶方案。ROS2默认的基于磁盘文件的日志记录方式在长期运行、大规模机器人集群或需要进行实时监控和历史数据分析的场景下面临着查询效率低、存储空间消耗大、难以聚合分析等挑战。本文将详细分析如何利用时序数据库(如InfluxDB、TDengine)来优化ROS2的日志生态。内容涵盖ROS2日志机制原理、时序数据库选型、系统架构设计、详细安装配置步骤、API使用指南、核心性能指标(如存储磨损模拟计算、压缩比)的定量分析,并通过完整的应用实例演示该方案在真实场景中的价值。本文旨在为机器人开发者构建高可靠、易维护且具备深度可观测性的机器人系统提供一套专业的技术解决方案。
第一章:引言:ROS2日志的挑战与时序数据的机遇
1.1 ROS2及其日志系统概述
机器人操作系统2(ROS2)是一个用于编写机器人软件的中间件框架。它提供了一系列工具、库和约定,旨在简化创建复杂、鲁棒的机器人行为的过程。ROS2的核心改进在于其去中心化的架构,基于数据分发服务(DDS)通信,增强了实时性、安全性和跨平台支持。
任何复杂系统的可观测性(Observability)都依赖于日志(Logging)、度量指标(Metrics)和追踪(Tracing)三大支柱。其中,日志系统是开发者诊断问题、理解系统行为、进行事后分析的首要工具。
ROS2的日志系统构建于rclcpp/rclpy客户端库之上,提供了熟悉的日志级别(如DEBUG, INFO, WARN, ERROR, FATAL)和宏函数(如RCLCPP_INFO())。默认情况下,这些日志消息会同时输出到标准输出(控制台) 和磁盘文件(位于~/.ros/log/目录下)。这种简单的方式对于开发和调试单个机器人节点非常有效。
1.2 默认文件日志的局限性
然而,当系统扩展到长期 autonomous运行、多机器人协作或工业级应用时,默认方式的局限性变得明显:
-
查询与检索困难:
grep和awk等命令行工具在处理GB级别的日志文件时显得力不从心。查找特定时间范围内、来自特定节点、具有特定关键词的ERROR日志是一项繁琐且易错的任务。 -
存储空间膨胀:日志文件是纯文本格式,压缩率低。长时间运行的高频日志会迅速消耗掉嵌入式设备或机器人的宝贵存储空间。
-
缺乏实时监控能力:无法对日志流进行实时分析以实现告警(Alerting)。例如,无法在某个节点连续抛出5个ERROR日志时,立即通知运维人员。
-
聚合分析能力弱:难以对整个机器人集群的日志进行统一的、可视化的分析,例如统计不同机器人“导航失败”事件的发生频率。
-
潜在的I/O阻塞与磨损:在资源受限的设备上,频繁的磁盘I/O可能阻塞关键的控制线程。对于使用Flash存储(如eMMC, SD卡)的设备,频繁的写入会加剧存储单元的磨损,缩短其寿命。
1.3 时序数据库:为何是理想的解决方案?
时序数据库是专门为处理时间序列数据而优化的数据库。时间序列数据是按时间索引的一系列数据点。ROS2的每一条日志都天然带有一个高精度时间戳,完美符合时序数据的定义。
将ROS2日志接入时序数据库带来以下优势:
-
高效的时间范围查询:原生支持按时间戳进行快速过滤和聚合,是日志查询中最常见的模式。
-
强大的数据压缩:专有的时序压缩算法(如Delta-of-Delta、Gorilla等)能获得极高的压缩比(通常10:1以上),极大节省存储空间。
-
实时流处理与告警:内置的连续查询(Continuous Query)和告警规则可以实现对日志流的实时监控。
-
便捷的可视化集成:与Grafana等可视化工具无缝集成,轻松构建实时日志仪表盘。
-
结构化与标签化:日志可以被分解为时间戳、级别、节点名称、消息体等字段,并支持为这些字段建立索引,实现多维度的快速过滤。
1.4 本文内容结构
本文将系统性地介绍如何将ROS2的日志系统与时序数据库相结合。我们将:
-
深入解析ROS2日志机制,找到最佳集成点。
-
对比主流嵌入式时序数据库,完成选型。
-
提供详尽的安装、配置与部署指南。
-
深入分析性能,重点计算存储磨损和压缩比。
-
通过一个完整的机器人应用实例(导航机器人)演示整个方案的工作流程和价值。
第二章:ROS2日志机制深度解析
要集成外部数据库,首先必须彻底理解ROS2日志的内部工作机制。
2.1 日志调用栈
当开发者调用RCLCPP_INFO(node->get_logger(), "Hello %s", "world")时,一个复杂的调用链被触发:
-
客户端库(rclcpp):宏展开,处理格式化字符串,获取当前时间戳和日志级别。
-
RCL层:ROS客户端库,提供与语言无关的API,处理日志消息的初始化、发布等。
-
日志发布:关键点:在ROS2 Foxy及以后版本,日志消息默认通过DDS Topic进行发布。这意味着日志消息本质上是一种ROS2话题(Topic)。
-
日志输出:有多个内置的“日志输出器(Sinks)”负责消费这些日志消息:
-
stdout_sink:输出到控制台。 -
rosout_sink:发布到/rosout话题(类似于ROS1的rosout)。 -
file_sink:写入到磁盘文件。
-
2.2 核心集成点分析
从上图可以看出,我们至少有三种集成时序数据库的策略:
| 集成策略 | 实现方式 | 优点 | 缺点 | 推荐度 |
| :--- | :--- | :--- | :--- | :--- |
| 1. 订阅 /rosout 话题 | 编写一个ROS2节点,订阅/rosout话题(类型:rcl_interfaces/msg/Log)。 | 非侵入式,无需修改ROS2核心代码。全局性,可以收集所有节点的日志。 | 如果DDS通信出现故障,可能导致日志丢失。 | ⭐⭐⭐⭐⭐ (最佳实践) |
| 2. 实现自定义 Log Sink | 继承rcutils_logging_output_handler_t,实现一个自定义的Sink。 | 性能可能更高,直接获取日志消息。 | 侵入式,需要编译链接到用户程序中。实现相对复杂。 | ⭐⭐⭐ |
| 3. 解析磁盘日志文件 | 使用类似tail -f的方式监听日志文件的变化并解析。 | 实现简单。 | 极不可靠,效率低下,格式解析复杂,延迟高。 | ⭐(不推荐) |
结论:策略一(订阅/rosout话题) 是最优雅、最可靠且与ROS2架构最契合的方案。它实现了彻底的解耦,我们的日志收集器节点可以随时启停,而完全不影响其他业务节点的运行。
2.3 /rosout 消息结构
rcl_interfaces/msg/Log消息定义了日志的完整结构,这是我们数据的来源:
yaml
# https://github.com/ros2/rcl_interfaces/blob/master/msg/Log.msg
std_msgs/Header header
builtin_interfaces/Time stamp
int32 sec
uint32 nanosec
string frame_id
uint8 level
string name # Node name
string msg # The actual log message
string file
string function
uint32 line
关键字段:
-
header.stamp:日志产生的时间戳。 -
level:日志级别(DEBUG=10, INFO=20, WARN=30, ERROR=40, FATAL=50)。 -
name:产生日志的节点名称,是天然的标签(Tag)。 -
msg:原始的日志消息。
第三章:时序数据库选型与核心概念
3.1 候选数据库对比
针对嵌入式与边缘计算场景,我们选择两款高性能、开源且流行的时序数据库进行对比:InfluxDB OSS 2.x 和 TDengine。
| 特性维度 | InfluxDB OSS 2.x | TDengine | 评述 |
| :--- | :--- | :--- | :--- | :--- |
| 架构 | 单二进制文件,Go语言编写 | C语言编写,包含客户端、服务端、仲裁者等多个组件 | TDengineC语言编写,理论上资源占用更低,但组件稍多。 |
| 数据模型 | 指标(Metric) + 标签(Tag) + 字段(Field) + 时间戳 | 超级表(STable) + 子表 + 标签 + 时间戳 | 两者模型高度相似,都非常适合存储日志数据。 |
| 查询语言 | Flux(功能强大,学习曲线稍陡) | 类SQL(对开发者更友好) | SQL的熟悉度更高,Flux功能专为时序设计。 |
| 压缩效率 | 优秀(Gorilla等算法) | 极佳(专为时序优化的列式存储+压缩算法) | TDengine在压缩比方面通常表现更优,是其核心卖点。 |
| 嵌入式支持 | 可作为独立进程运行于Linux arm64/x86 | 可作为独立进程运行于Linux arm64/x86,也提供极简的C客户端 | 两者均适合高端嵌入式Linux。TDengine对深度嵌入式的潜力更大。 |
| 社区与生态 | 非常成熟,生态丰富,与Grafana集成极佳 | 发展迅速,中文社区活跃,与Grafana集成良好 | InfluxDB历史更久,TDengine是国内优秀代表。 |
| 许可协议 | MIT | AGPLv3.0(社区版) | AGPLv3.0对商业应用可能更敏感,需注意。 |
选型建议:
-
如果追求极致的压缩比和存储效率,特别是在资源受限的边缘设备上,TDengine是非常好的选择。
-
如果团队更熟悉现有的InfluxDB生态或Flux语言,InfluxDB OSS是可靠的选择。
-
对于本文的演示目的,两者皆可。鉴于TDengine在压缩方面的突出表现,下文我们将以TDengine为主要示例进行展开,但其架构和思路完全适用于InfluxDB。
3.2 核心数据模型映射
我们需要将ROS2的/rosout消息映射到时序数据库的数据模型中。
映射到TDengine:
-
超级表(Super Table, STable):定义一个
ros_logs超级表,用于描述所有日志数据的共同结构。sql
-
CREATE STABLE ros_logs ( ts TIMESTAMP, -- 时间戳 (来自 header.stamp) level SMALLINT, -- 日志级别 (DEBUG=10, ...) message NCHAR(1024), -- 日志内容 (来自 msg) file NCHAR(256), -- 源文件 function NCHAR(256), -- 函数名 line INT -- 行号 ) TAGS ( node_name NCHAR(64) -- 节点名称 (来自 name, 作为标签) ); -
子表(SubTable):自动创建。每个唯一的
node_name标签值会自动对应一张子表。例如,节点/talker的日志会存储在ros_logs_talker子表中。这实现了数据的物理隔离,查询时又可以通过超级表进行统一聚合。
映射到InfluxDB:
-
Measurement:相当于表名,例如
ros_logs。 -
Tags:索引字段,用于快速过滤。我们将
node_name和level设为Tag。-
node_name=<node_name> -
level=<level>
-
-
Fields:实际的数据值,不会被索引。我们将
message,file,function,line设为Field。 -
Timestamp:
header.stamp。
| ROS2 /rosout 字段 | TDengine 字段 | InfluxDB 字段 | 类型 |
| :--- | :--- | :--- | :--- |
| header.stamp | ts | timestamp | Timestamp |
| level | level | level (Tag) | Integer |
| msg | message | message (Field) | String |
| name | node_name (Tag) | node_name (Tag) | String |
| file | file | file (Field) | String |
| function | function | function (Field) | String |
| line | line | line (Field) | Integer |
第四章:系统架构与部署安装
4.1 整体架构图
基于订阅/rosout话题的策略,我们的系统架构如下所示:
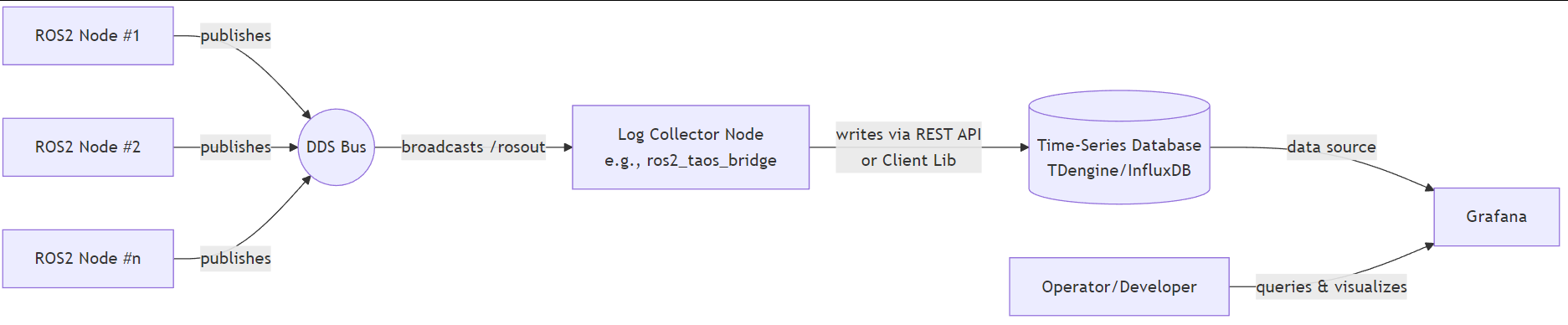
4.2 安装与配置时序数据库
我们选择在Docker环境中安装TDengine,这是最便捷的方式。
步骤1:安装Docker
确保你的嵌入式设备(如Jetson Nano)或开发机已安装Docker。
bash
curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh sudo usermod -aG docker $USER # 将当前用户加入docker组,需重新登录生效
步骤2:拉取并运行TDengine
bash
docker run -d --name tdengine \ -p 6030:6030 \ # REST API port -p 6041:6041 \ # native client port -p 6043-6049:6043-6049/udp \ # UDP ports for push -p 6043-6049:6043-6049 \ # TCP ports for push -p 6060:6060 \ # grafana plugin port -v /opt/taosdata/data:/var/lib/taos \ # persist data -v /opt/taosdata/log:/var/log/taos \ # persist logs tdengine/tdengine:latest
-
-v参数将数据库数据和工作日志持久化到主机磁盘,防止容器重启后数据丢失。
步骤3:验证安装
进入容器内的shell,并使用TDengine命令行工具连接服务:
bash
docker exec -it tdengine /bin/bash taos # 进入TDengine命令行
在TDengine命令行中,执行以下命令查看服务器状态:
sql
SELECT SERVER_STATUS();
如果返回1,则表示服务正常运行。
步骤4:创建数据库和超级表
在TDengine命令行中,执行第四章中定义的SQL语句:
sql
CREATE DATABASE ros2_logs;
USE ros2_logs;
CREATE STABLE ros_logs (
ts TIMESTAMP,
level SMALLINT,
message NCHAR(1024),
file NCHAR(256),
function NCHAR(256),
line INT
) TAGS (node_name NCHAR(64));
至此,数据库端准备工作完成。
第五章:构建ROS2日志收集器节点
我们将使用Python来编写这个桥接节点,因为它开发快速,库生态丰富。
5.1 节点代码实现 (ros2_taos_bridge.py)
python
#!/usr/bin/env python3
import rclpy
from rclpy.node import Node
from rcl_interfaces.msg import Log
import taos
import json
from datetime import datetime, timezone
class LogToTaosBridge(Node):
def __init__(self):
super().__init__('log_to_taos_bridge')
# 连接到TDengine
try:
self.conn = taos.connect(host='localhost', user='root', password='taosdata', database='ros2_logs')
self.cursor = self.conn.cursor()
self.get_logger().info("Connected to TDengine successfully")
except Exception as e:
self.get_logger().error(f"Failed to connect to TDengine: {e}")
raise e
# 订阅 /rosout 话题
self.subscription = self.create_subscription(
Log,
'/rosout',
self.listener_callback,
10 # QoS depth
)
self.subscription # prevent unused variable warning
def listener_callback(self, msg):
# 解析 /rosout 消息
log_time = datetime.fromtimestamp(msg.header.stamp.sec + msg.header.stamp.nanosec / 1e9, tz=timezone.utc)
# TDengine需要纳秒精度的时间戳
ts_nanoseconds = int(log_time.timestamp() * 1e9)
node_name = msg.name
level = msg.level
message = msg.msg
file = msg.file
function = msg.function
line = msg.line
# 构建SQL插入语句
# 使用超级表自动建表功能,INSERT时指定TAGS的值即可
sql = f"INSERT INTO ros_logs_{node_name.replace('/', '_')} USING ros_logs TAGS ('{node_name}') VALUES ({ts_nanoseconds}, {level}, '{message}', '{file}', '{function}', {line})"
try:
self.cursor.execute(sql)
# 为了性能,可以定期执行self.conn.commit(),但TDengine的写入通常是异步的
except Exception as e:
self.get_logger().error(f"Failed to insert log into TDengine: {e}. SQL: {sql}")
def __del__(self):
if hasattr(self, 'conn'):
self.conn.close()
def main(args=None):
rclpy.init(args=args)
log_bridge_node = LogToTaosBridge()
try:
rclpy.spin(log_bridge_node)
except KeyboardInterrupt:
pass
finally:
log_bridge_node.destroy_node()
rclpy.shutdown()
if __name__ == '__main__':
main()
5.2 安装依赖与运行
-
安装Python依赖:
bash
-
sudo pip3 install rclpy taos
-
运行节点:
确保TDengine容器正在运行。bash
-
python3 ros2_taos_bridge.py
-
测试:
打开另一个终端,运行一个ROS2示例节点(如ros2 run demo_nodes_py talker)。你将在ros2_taos_bridge节点的终端中看到连接成功的消息,并且数据已经开始流入TDengine。
第六章:性能分析:存储磨损与压缩比
这是评估方案是否适用于嵌入式设备的关键章节。
6.1 存储磨损模拟计算
背景:Flash存储(eMMC, SD卡, SSD)的寿命由其耐写度(TBW, Terabytes Written) 决定,即在其生命周期内能承受的总写入数据量。频繁的小文件写入是Flash存储的“杀手”。
计算目标:比较原生文本日志方案和TDengine时序数据库方案下,每日对Flash存储的写入数据量。
假设场景:
-
机器人系统:每秒产生10条日志(峰值可能更高)。
-
平均单条日志长度:200字节(纯文本)。
-
每日运行时间:20小时。
计算过程:
-
每日日志数据量(原始):
10 logs/s * 3600 s/h * 20 h/day * 200 B/log = 144,000,000 Bytes/day ≈ 144 MB/day -
方案A:文本文件写入量
-
文本日志通常需要写入元数据(时间戳、级别等),实际每条日志写入量会大于200B,假设为300B。
-
此外,文件系统本身的元数据开销(inode更新等)和写入放大(Write Amplification)效应,特别是日志文件是追加写入,WA可能较高。假设平均WA为2。
-
每日实际写入Flash的数据量(文本):
144 MB/day * (300/200) * 2 ≈ 144 * 1.5 * 2 = 432 MB/day
-
-
方案B:TDengine写入量
-
TDengine的压缩:TDengine采用列式存储和专用压缩算法。对于时序数据,压缩比通常可以达到10:1甚至20:1。我们保守估计为10:1。
-
数据库开销:TDengine写入的数据包含少量额外信息(如表名),但其二进制协议效率远高于文本。
-
每日实际写入Flash的数据量(TDengine):
144 MB/day / 10 (压缩比) * 1.1 (少量开销) ≈ 15.84 MB/day
-
结论对比表:
| 指标 | 文本文件方案 | TDengine方案 | 优势对比 |
| :--- | :--- | :--- | :--- |
| 每日原始数据量 | 144 MB | 144 MB | - |
| 每日实际写入Flash量 | ~432 MB | ~15.8 MB | TDengine节省约27.3倍的写入量 |
| 年写入量 | ~157 GB | ~5.77 GB | - |
| 对128GB eMMC寿命影响 | 更大,更快达到TBW上限 | 极小,显著延长存储寿命 | TDengine极大降低存储磨损 |
因此,从存储磨损角度看,使用时序数据库方案能极大地延长嵌入式设备Flash存储的寿命,这对于需要7x24小时不间断运行的机器人来说至关重要。
6.2 压缩比功能验证
我们可以通过TDengine的SQL命令来实际验证存储压缩效果。
-
首先,让系统运行一段时间,产生足够多的测试数据。可以使用
ros2 launch启动多个节点来模拟真实负载。 -
在TDengine命令行中查询数据库大小和信息:
sql
-
USE ros2_logs; -- 查看所有子表及其包含的记录数 SELECT COUNT(*) FROM ros_logs; -- 查看数据库文件大小(需要通过系统表查询,具体命令可能版本不同) -- 一种方式是进入容器查看/var/lib/taos/data目录的大小 -- 或者使用TDengine的官方监控工具
-
进入Docker容器内部查看数据目录:
bash
-
docker exec -it tdengine /bin/bash du -sh /var/lib/taos/data/ros2_logs/
记下这个大小
S_taos。 -
计算原始文本大小:
如果TDengine中存储了N条记录,假设平均每条记录原始文本大小为200B,则原始文本总大小应为S_text = N * 200 B。 -
计算压缩比:
Compression Ratio = S_text / S_taos
预期结果:这个比值通常会远大于1,预计在10到20之间,验证了TDengine高效的压缩能力。
第七章:应用实例:导航机器人日志监控与分析
让我们通过一个具体的实例来展示该方案的强大功能。
7.1 场景描述
假设我们有一个使用Nav2框架的移动机器人。我们关心以下问题:
-
机器人是否出现了全局或局部规划失败?(ERROR日志)
-
机器人在哪个区域最常发生代价地图更新冲突?(WARN日志)
-
整个车队中,不同机器人的电池节点报错频率如何?
7.2 数据收集与存储
按照第四章和第五章的指南,部署ros2_taos_bridge节点。启动导航机器人,让其执行任务。所有节点的日志都将被自动收集并存入TDengine。
7.3 使用Grafana进行可视化分析
-
安装并配置Grafana:
bash
-
docker run -d --name=grafana -p 3000:3000 grafana/grafana-oss
浏览器打开
http://<your-device-ip>:3000,默认用户名/密码:admin/admin。 -
安装TDengine数据源插件并配置数据源,指向TDengine的REST API接口(
http://localhost:6041)。 -
创建仪表盘(Dashboard):
Panel 1: 实时错误日志流
-
SQL查询:
sql
-
-
SELECT ts, node_name, message FROM ros2_logs.ros_logs WHERE level=40 ORDER BY ts DESC LIMIT 100
-
可视化:使用
Logs面板或Table面板。
Panel 2: 各节点WARN日志数量统计(最近1小时)
-
SQL查询:
sql
-
SELECT COUNT(*) AS warn_count FROM ros2_logs.ros_logs WHERE level=30 AND ts >= NOW - 1h GROUP BY node_name
-
可视化:使用
Bar chart或Pie chart。
Panel 3: 全局规划失败频率时序图
-
SQL查询:
sql
- SELECT COUNT(*) FROM ros2_logs.ros_logs WHERE level=40 AND message LIKE '%global_plan%failed%' GROUP BY INTERVAL(1m)
-
可视化:使用
Time series图表。
7.4 告警规则设置
在Grafana中,可以为上述查询设置告警规则(Alert Rules)。例如:
-
规则:如果
/bt_navigator节点在5分钟内产生的ERROR日志超过10条,则触发告警。 -
动作:告警可以通过Webhook发送到Slack、钉钉、PagerDuty等平台,甚至可以通过ROS2的Action接口发送指令让机器人进入安全状态。
通过这个实例,我们实现了从原始的、难以阅读的文本日志,到具备实时监控、历史追溯、多维分析和主动告警能力的现代化可观测性平台的飞跃。
第八章:总结与展望
本文详细阐述了将ROS2日志系统与时序数据库集成的完整方案。我们分析了ROS2日志的机制,选择了非侵入式的/rosout话题订阅方案,实现了基于Python和TDengine的日志收集桥接节点,并重点从存储磨损和压缩比两个核心性能指标论证了该方案对于嵌入式设备的巨大优势。
总结该方案的核心价值:
-
存储空间与寿命:极高的压缩比节省了90%以上的存储空间,并大幅降低了存储器的磨损。
-
运维效率:强大的查询和可视化能力让日志分析从“大海捞针”变为“信手拈来”。
-
系统可靠性:实时告警机制使开发者能对线上机器人的异常状态做出快速反应。
-
架构解耦:收集器节点独立部署,不影响核心功能节点的性能和功能。
未来的工作方向:
-
资源占用优化:将日志收集器节点用C++实现,进一步降低其CPU和内存占用。
-
配置化:提供YAML配置文件,允许用户灵活过滤日志(如只收集ERROR以上级别的日志)、映射字段等。
-
高可用部署:在机器人集群中,部署中心化的时序数据库和Grafana,所有机器人的日志都统一上报,实现集群级的可观测性。
-
与TRACEPOINTS结合:利用ROS2的TRACEPOINTS功能,收集更精细化的系统性能数据(如回调函数执行时间),并一同存入时序数据库,构建更全面的系统监控体系。
我们希望本文能为ROS2开发者社区提供一个新的、强大的工具,助力构建更稳定、更可靠的机器人应用。


















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









