




一、引言
论文: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
作者: Microsoft Research Asia
代码: Swin Transformer
特点: 提出滑动窗口自注意力 (Shifted Window based Self-Attention) 解决Vision Transformer输入高分辨率图像注意力模块计算复杂度高的问题。
二、框架
Swin Transformer的整体框架图如下:
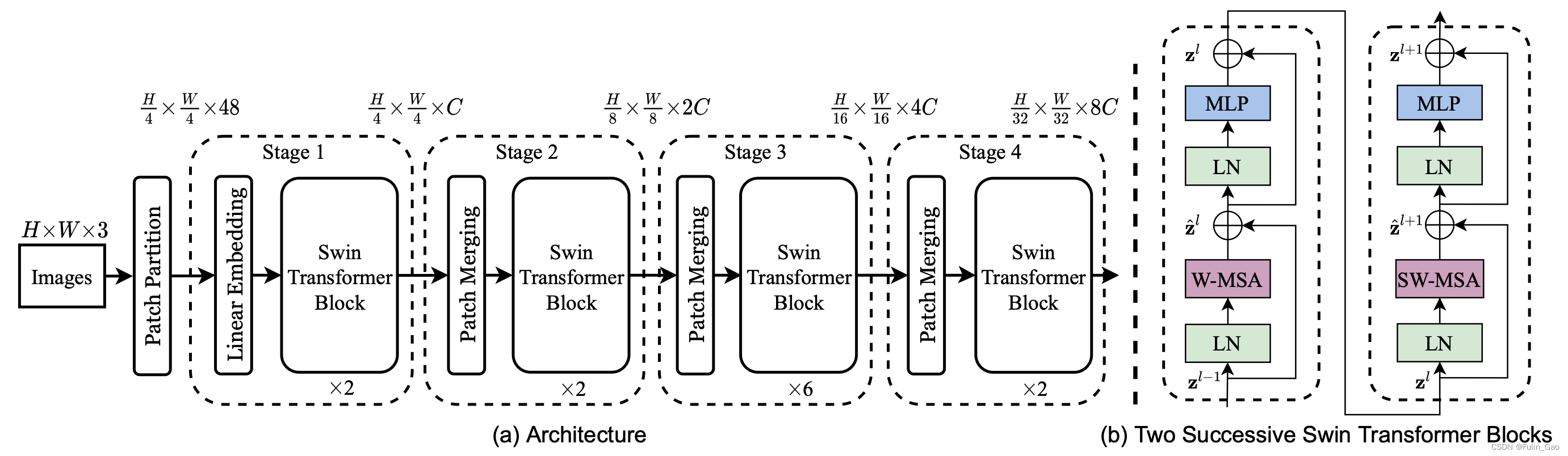
可见,Swin Transformer主要包括Patch Partition+Linear Embedding、Swin Transformer Block、Patch Merging几个组件。每经历一个Stage特征图都会缩小2倍、通道数放大2倍,这与ResNet网络的特征尺度变化过程很类似。
Swin Transformer Block的最小单位为上图右侧两个连续的Block,两个Block的差别仅在于注意力模块是窗口多头自注意力 (W-MSA) 还是滑动窗口多头自注意力 (SW-MSA)。所以每个Stage中包含的Block数量都是2的整数倍。
2.1 Patch Partition+Linear Embedding
Patch Partition是要将图像拆分成多个 4 ∗ 4 ∗ 3 4*4*3 4∗4∗3大小的Patch(4*4是每个Patch包含的像素点数,3是原始图像通道数),如下图所示:

之后将每个Patch按行展平,于是每个Patch形成一个 1 ∗ 1 ∗ 48 1*1*48 1∗1∗48的像素点。 48 = 4 ∗ 4 ∗ 3 48=4*4*3 48=4∗4∗3,原本一个像素点通道数为3,一个Patch有 4 ∗ 4 4*4 4∗4个像素点,所以展平后一个Patch变成一个通道数为48的像素点。所有Patch展平后按原位置拼接则形成 H 4 ∗ W 4 ∗ 48 \frac{H}{4}*\frac{W}{4}*48 4H∗4W∗48的特征图。
通过Linear Embedding(例如核为 1 ∗ 1 1*1 1∗1的2D卷积)将通道数从48映射到 C C C(原文中 C = 96 C=96 C=96)。最后通过LayerNorm将所有通道数为 C C C的像素点归一化。
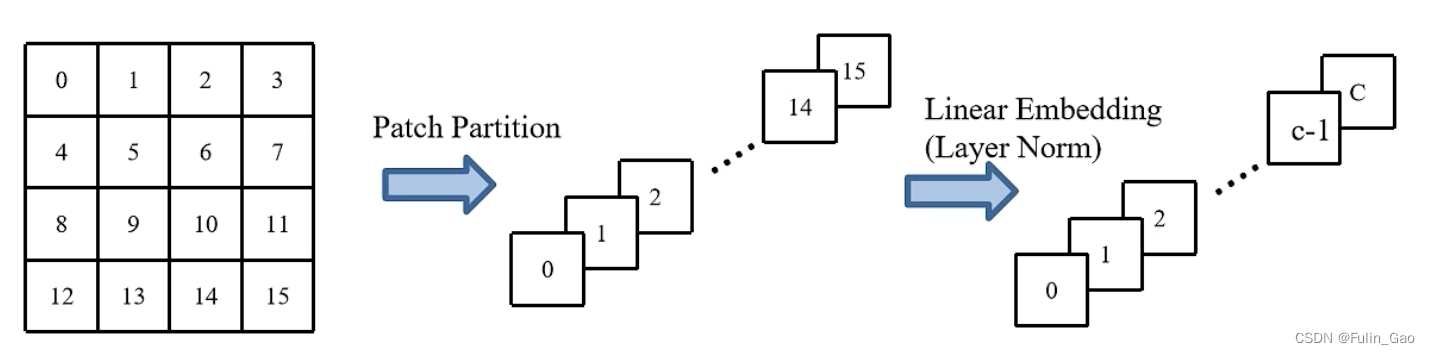
上图为一个Patch上16个像素点的Patch Partition+Linear Embedding过程(图中一个小方格代表一个有3个通道的像素点, c = C 3 c=\frac{C}{3} c=3C)。
事实上,Patch Partition+Linear Embedding就是要将图像尺寸从 H ∗ W ∗ 3 H*W*3 H∗W∗3转换为 H 4 ∗ W 4 ∗ C \frac{H}{4}*\frac{W}{4}*C 4H∗4W∗C。 与Vision Transformer取Patch时采取的策略一致,Swin Transformer并没有分两步完成该操作,而是通过一个卷积核大小为 4 ∗ 4 4*4 4∗4、步长为4、输出通道数为96的2D卷积层进行特征提取,再通过LayerNorm对所有token进行归一化(一个token对应 H 4 ∗ W 4 ∗ C \frac{H}{4}*\frac{W}{4}*C 4H∗4W∗C的特征图中的一个像素点)。
2.2 Swin Transformer Block
下图为Vision Transformer(左)和Swin Transformer(右)中Block的结构图:
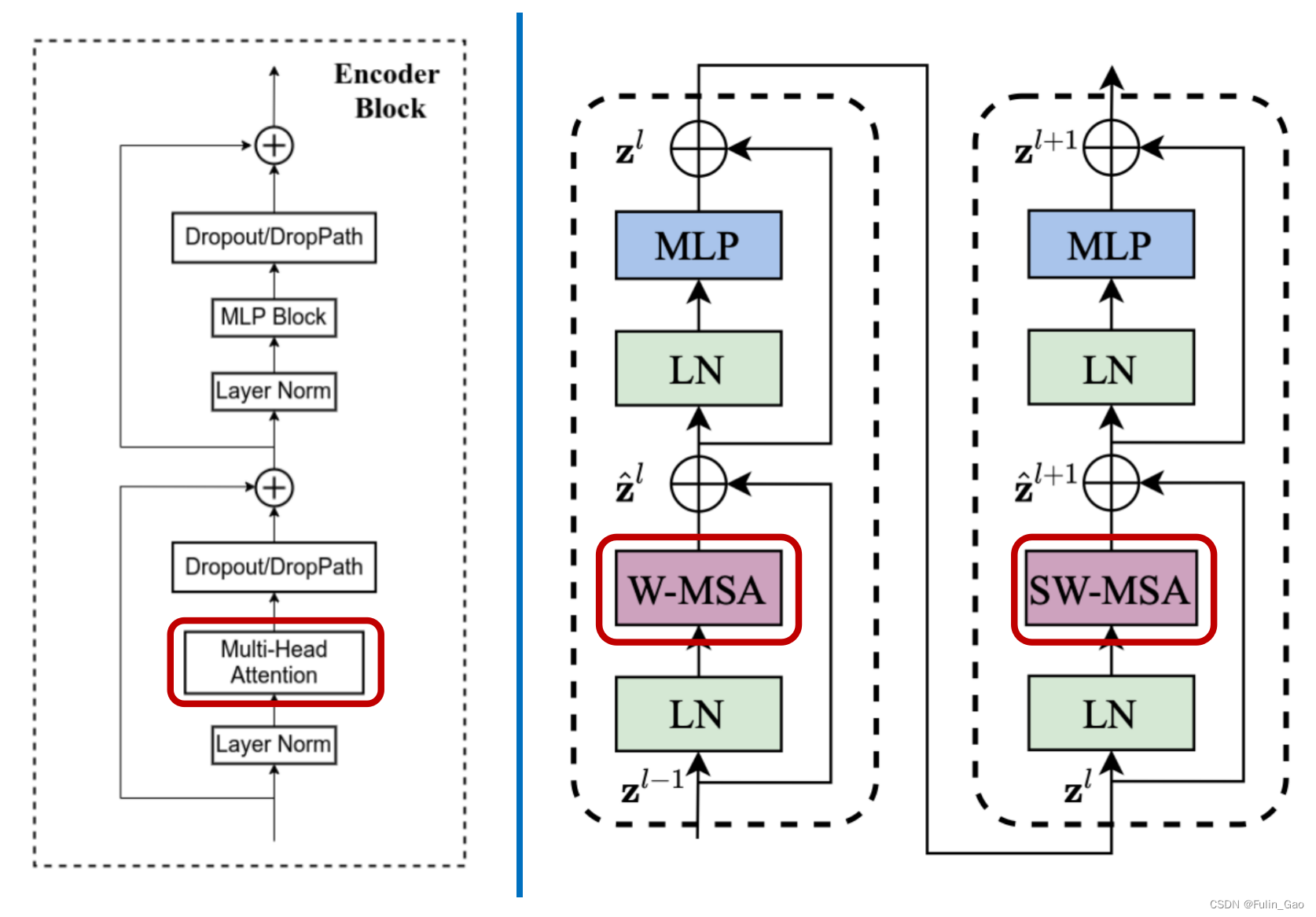
其中,Swin Transformer中也有DropPath但是没有画出来,并且他们的MLP模块均为如下结构:

可见,两者结构基本一致,主要区别如下:
(1) Vision Transformer的每一个Block都一样,而Swin Transformer中两个不同的Block是一个基本单位,两个Block顺序连接,不会单独出现。
(2) Vision Transformer使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











