




 博客主要介绍了深度学习中的Dropout和DropPath。Dropout在训练时按概率使神经元失活,能提高网络泛化能力、防止过拟合,但会减缓收敛速度,且与BatchNorm不易兼容;DropPath在训练时随机删除多分支结构,可作正则化手段,但会增加训练难度。
博客主要介绍了深度学习中的Dropout和DropPath。Dropout在训练时按概率使神经元失活,能提高网络泛化能力、防止过拟合,但会减缓收敛速度,且与BatchNorm不易兼容;DropPath在训练时随机删除多分支结构,可作正则化手段,但会增加训练难度。
一、Dropout
1. 概念
Dropout 在训练阶段会让当前层每个神经元以drop_prob( 0 ≤ drop_prob ≤ 1 0\leq\text{drop\_prob}\leq1 0≤drop_prob≤1)的概率失活并停止工作,效果如下图。
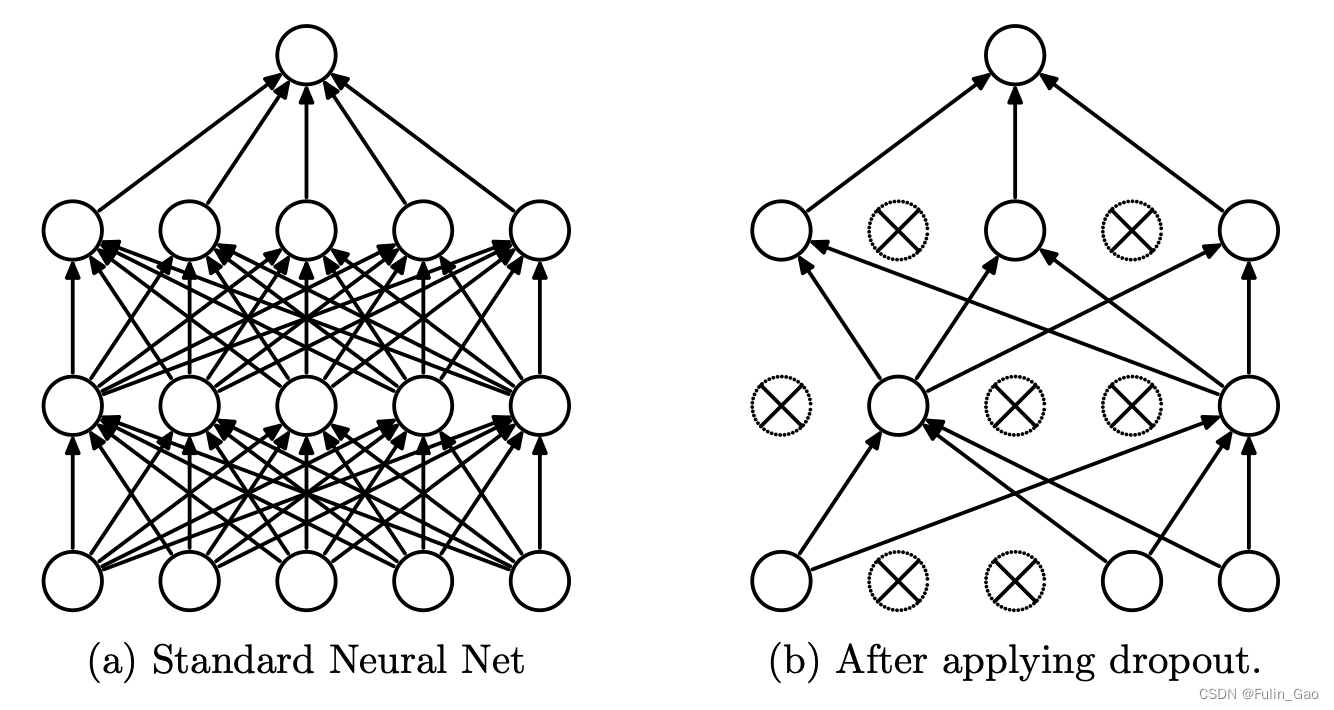
在测试阶段不会进行Dropout。由于不同批次、不同样本的神经元失活情况不同,测试时枚举所有情况进行推理是不现实的,所以原文使用一种均值近似的方法进行逼近。详情如下图:
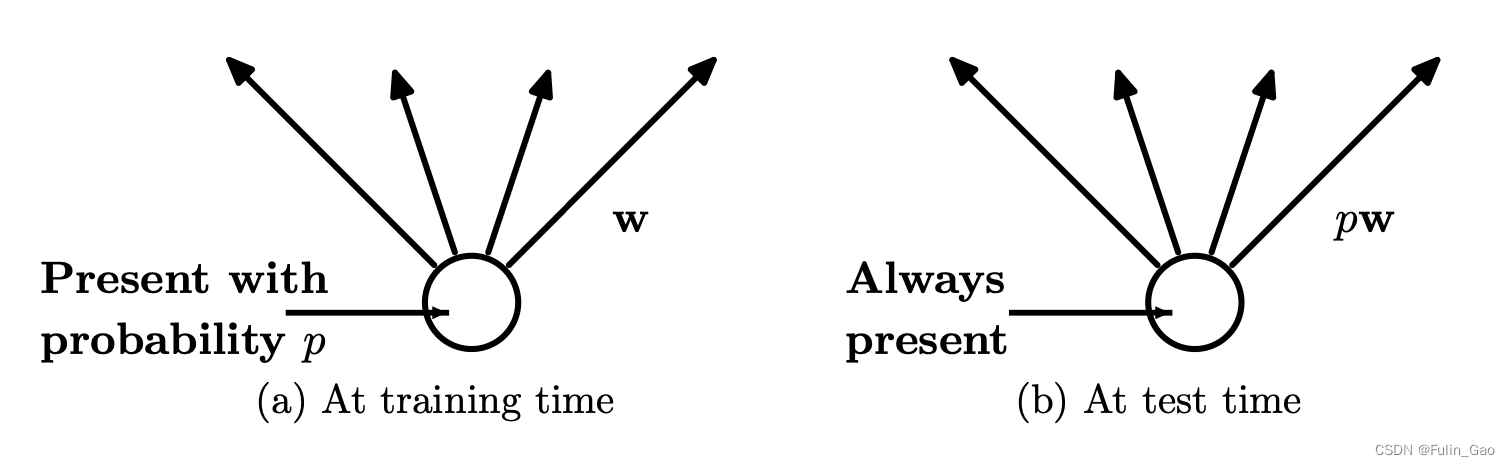
如图, w \bold{w} w为一个神经元后的权重。假设该神经元的输出均值为 μ \mu μ,若训练阶段该神经元的存活概率为 p p p,则Dropout使其输出均值变为 p × μ p\times\mu p×μ,为使测试时该神经元输出逼近训练输出,测试阶段该神经元输出会被乘上 p p p以使测试与训练输出均值相同。
简单来说,训练时Dropout按照概率drop_prob使神经元停止工作,测试时所有神经元正常工作,但其输出值要乘上1-drop_prob( p = 1 − drop_prob p=1-\text{drop\_prob} p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3569
3569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











