




 本文详细介绍了SwinTransformer的结构,包括其由MMBasicLayer构成的基本单元,以及PatchPartition、Stage1-4的流程。重点讲解了SwinTransformerBlock如何利用窗口和滑动机制进行注意力计算,以及如何通过循环移位和掩码解决窗口数量变化的问题。
本文详细介绍了SwinTransformer的结构,包括其由MMBasicLayer构成的基本单元,以及PatchPartition、Stage1-4的流程。重点讲解了SwinTransformerBlock如何利用窗口和滑动机制进行注意力计算,以及如何通过循环移位和掩码解决窗口数量变化的问题。
一、前言
SwinTransformer 在 2021 年荣获 ICCV 最佳论文奖,是目前最主流的 backbone 之一。
对 SwinTransformer 不了解的话,可以先去 bilibili 看一下李沐老师的视频,个人觉得非常细致,链接放在这里了:Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili
论文名:《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
二、SwinTransformer 结构图
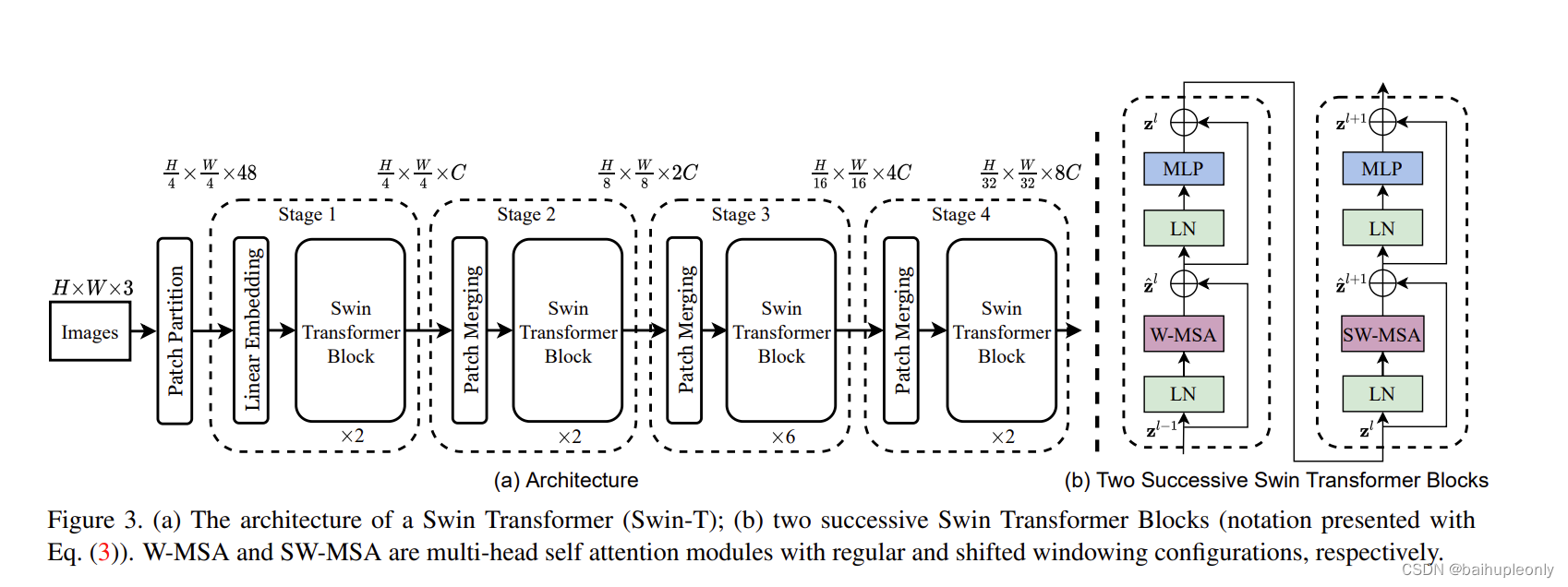
SwinTransformer 是由多个 MMBasicLayer 拼接而来的(即图中 Stage1,2,3,4)而每一个 MMBasicLayer 是由 Linear Embedding 或 Patch Merging 衔接一系列 SwinTransformer Block 组成。
SwinTransformer 总是成对出现,如上图右所示,具体原因下面介绍。
三、SwinTransformer 前馈流程
1)Patch Partition:将图像特征 [H,W,C] 打成多个 Patches(原文中 Patch_size = 4*4),则每个 Patch 中的总特征数为 3*4*4 = 48,特征变为 [H/4,W/4,48]。
2)Stage1:特征进入第一层 MMBasicLayer (即 Stage0),经过 Linear Embedding 后将特征投影到指定维度 C(卷积来实现的),特征变为 [H/4,W/4,C]。
之后特征又经过 SwinTransformer Block 形状不改变,所以 Stage1 最终输出的特征为 [H/4,W/4,C]
3)Stage 2:特征进入第二层 MMBasicLayer(即 Stage1),经过 Patch Merging 后对特征进行合并,合并策略如下图。
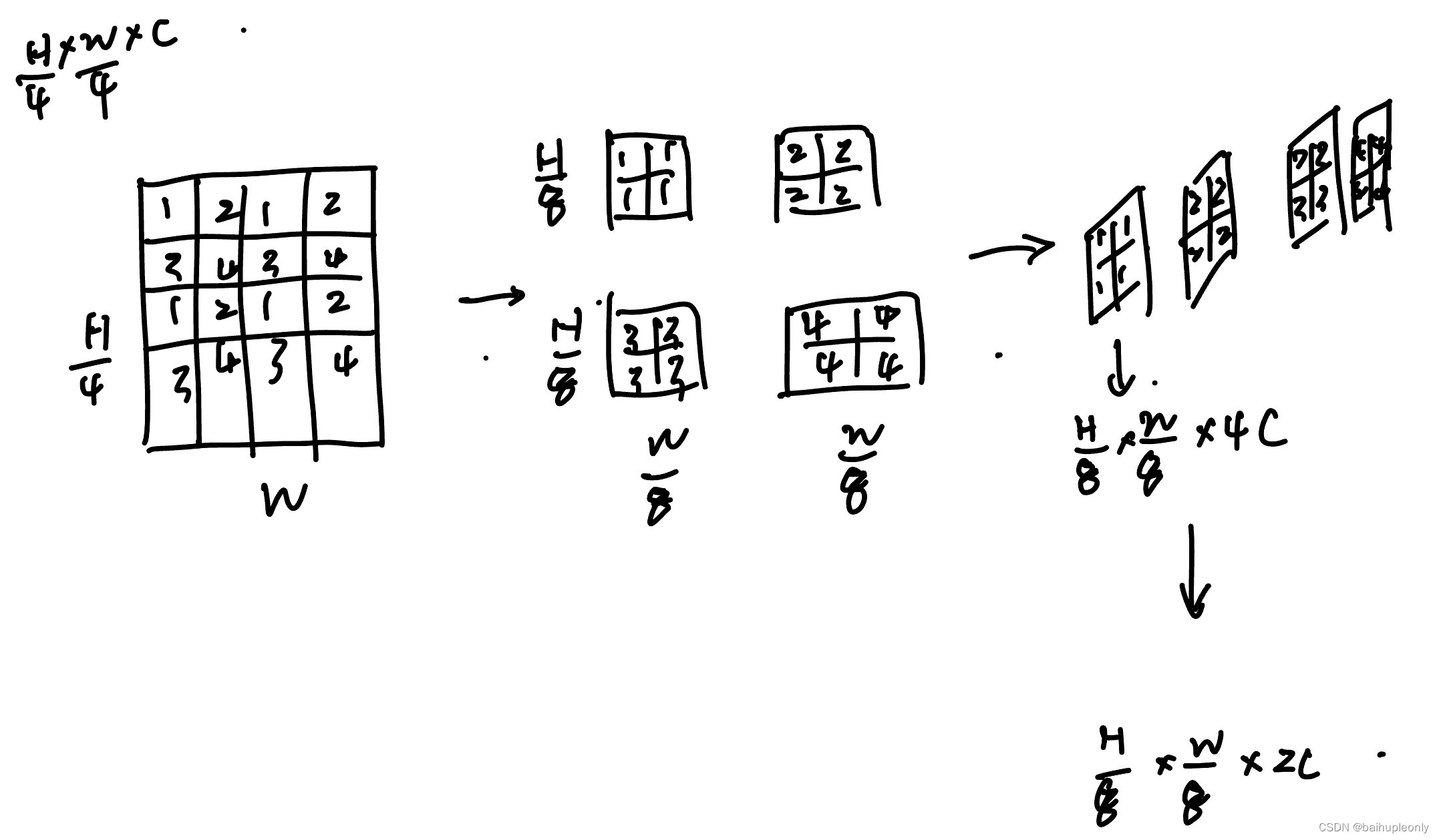
按照上述合并方式,先将四个大小为 [H/8,W/8,C] 的特征沿着 channel 维度拼接得到 [H/8,W/8,4C]。然后,文章考虑到传统卷积特征提取是 H、W 缩小为原来的一半,通道翻倍。为了保持一致,该层又处理把通道从 4C 变为 2C,即 [H/8,W/8,4C]。
然后,将特征 [H/8,W/8,2C] 送入 SwinTransformer Block 中,输出特征尺度不变。
4)Stage N:重复3),在最后一层 Stage 之后,通常连接着下游具体任务的解码器,最终输出所需要的指标。
四、SwinTransformer Block 详解
首先,SwinTransformer 是在 Transformer 的基础上,增加了“窗口”这个概念。一个窗口中包含多个 Patch,注意力的计算只在各个窗口内进行,而不是在全局所有 Patch 中进行,节省了计算资源。如下图左所示。
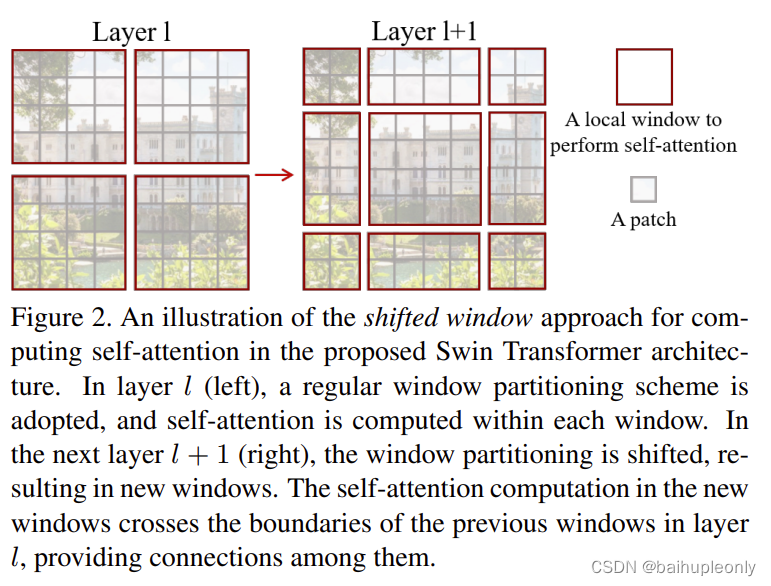
但是,窗口之间的信息又如何交互呢?作者又提出了“滑动”的概念,将窗口按照“窗口大小的一半”向右下方进行滑动,整张图就被新的窗口所划分了,实现了原来窗口间信息的交互。如上图右所示。
所以 SwinTransformer Block 总是成对出现,不仅完成原窗口内的 Patch 的注意力计算,同时通过滑动窗口,实现了窗口间 Patch 的注意力计算。(作者是真的牛掰!)
存在问题:窗口进行滑动之后,整张图就不是原来的 4 个窗口了,而是 9 个窗口了,这时候该如何计算注意力呢?
解决:作者提出了“循环移位+掩码+复原” 的方式,在不增加算力的前提下,使得该问题得到解决。
具体: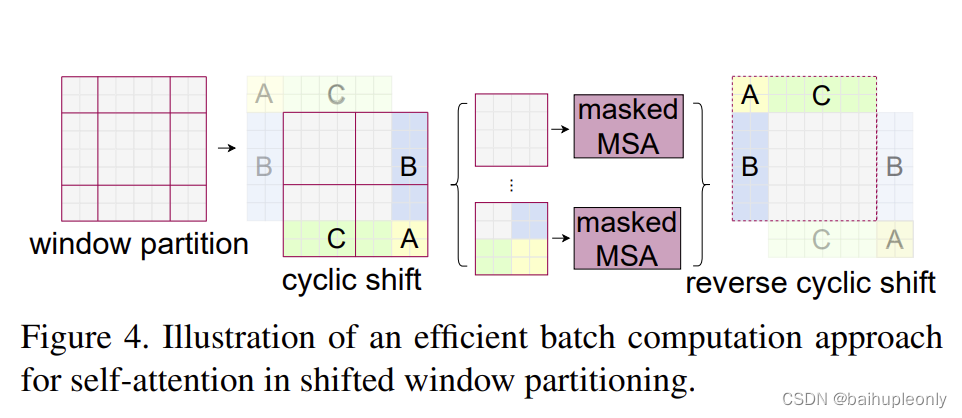
1)循环位移:A、C 移动到最底下,再把 B、A 移动到最右边,整个图的窗口数量又变 成了 4。
2)掩码:针对不同区域生成 4 种不同的 Mask(新左上、新右上、新左下、新右下)
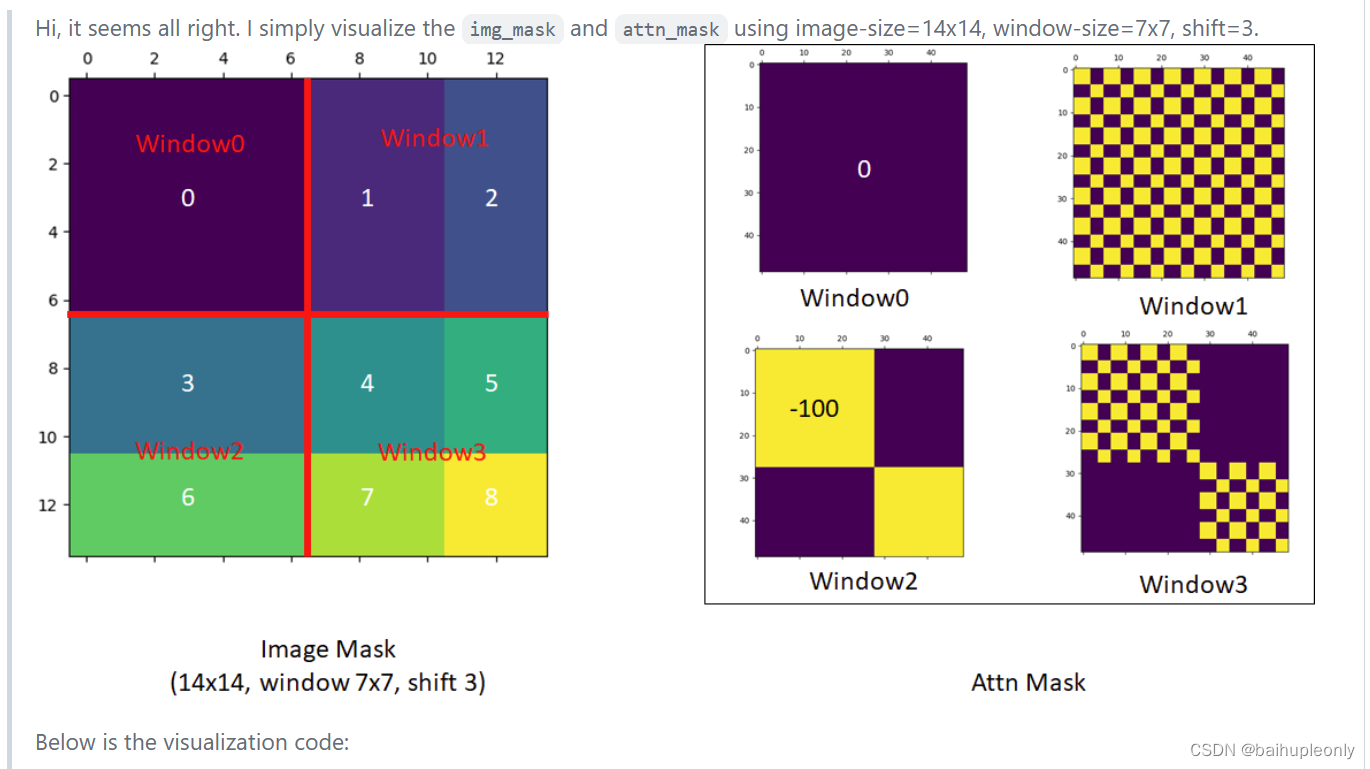
更为详细的解释可以看下图(以左下角3、6区的 Mask 为例子):
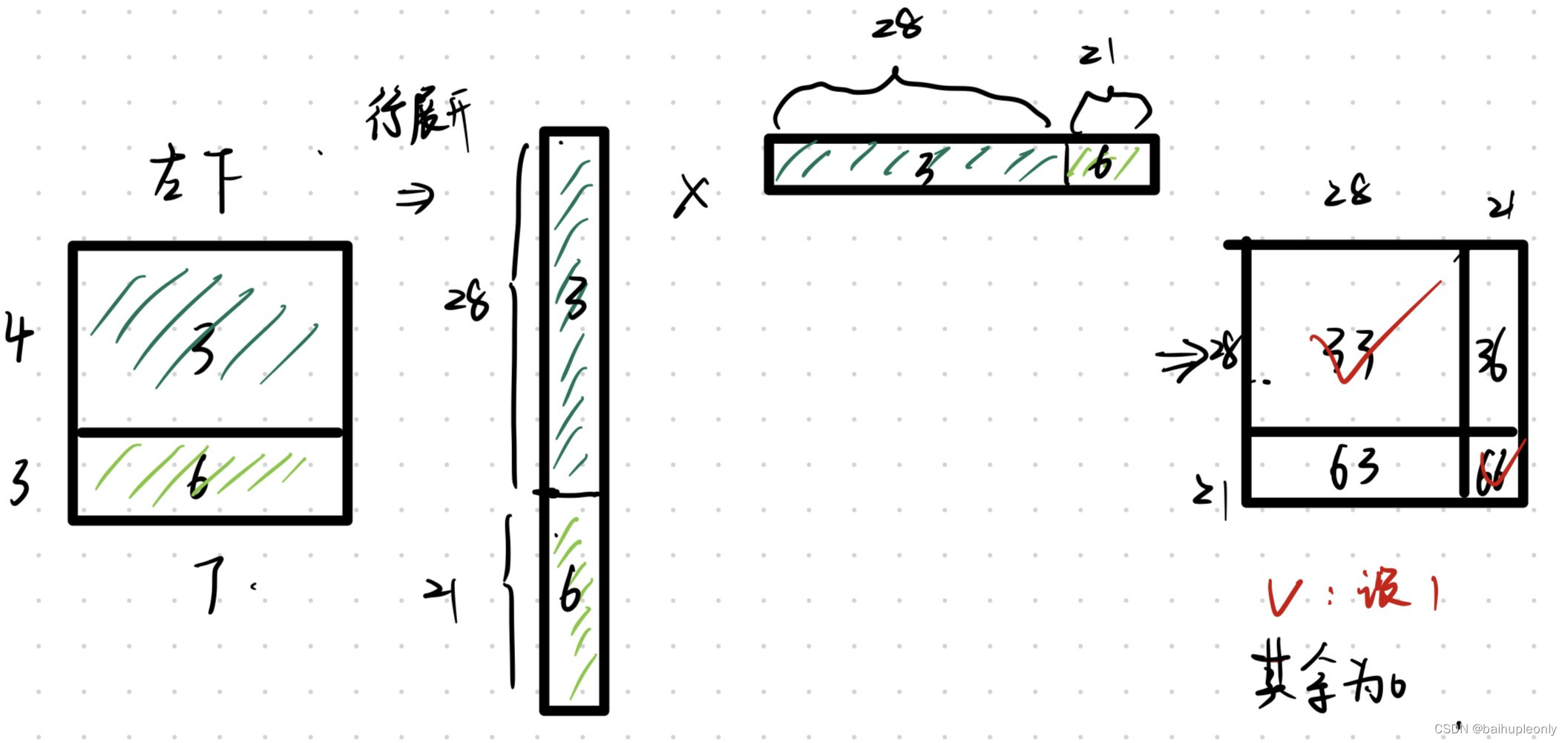
3)复原:在与 Mask 结合后,按照区域位置进行复原,然后特征可以继续被送入下一 个 Stage。
五、总结
看了好多遍 SwinTransformer,这回结合代码看总算理解的更深了一步,强烈建议小白看我上面链接里面推荐的视频。
这是本人的第二篇学习笔记博客,如有问题,欢迎指正,感谢各位大佬!!

















 7002
7002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









