




总览:
1.目标检测数据,365类,约600k训练图片,超过一千万的bboxes。迄今为止最大的目标检测数据集(全注释的)。
2.服务于更好的未来研究:局部敏感类型的任务,如目标检测,语义分割
3.在COCO测试下,Objects365上预训练的模型比在ImageNet上预训练的模型高5.6个点(90K次迭代)。而在540K次迭代下,仍然高2.7个点。同时到达同样的精度,前者finetuing 时间为后者的1/10。
数据使用性能:
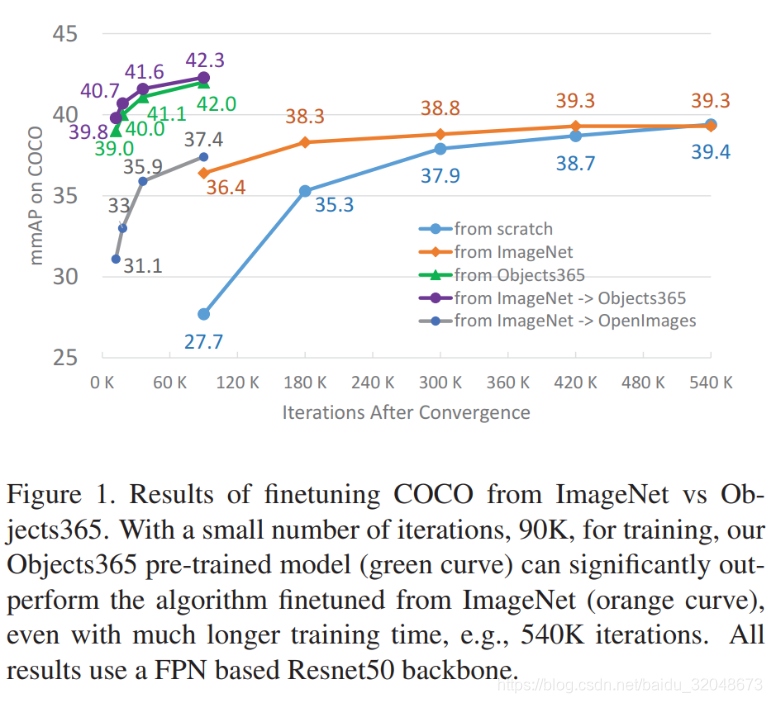
数据对比:
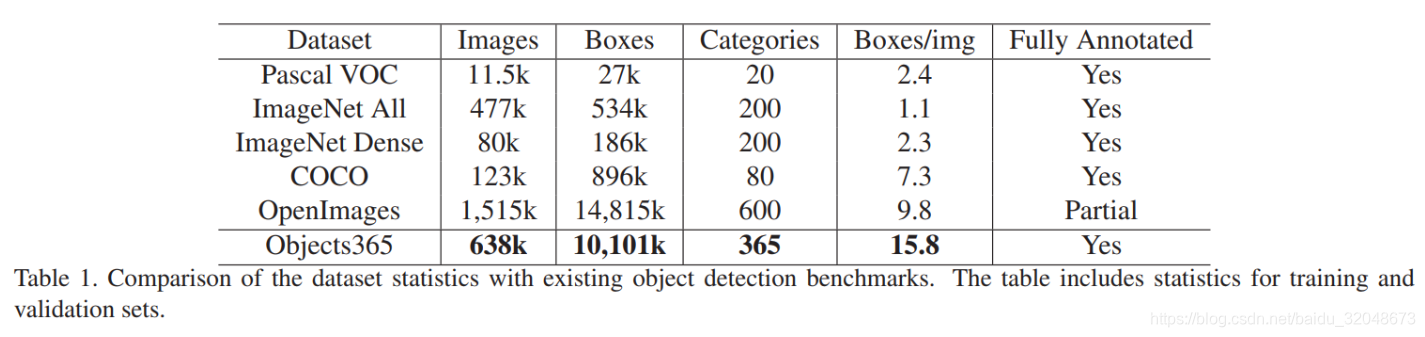
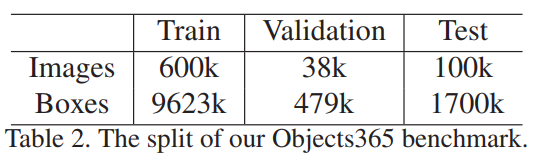
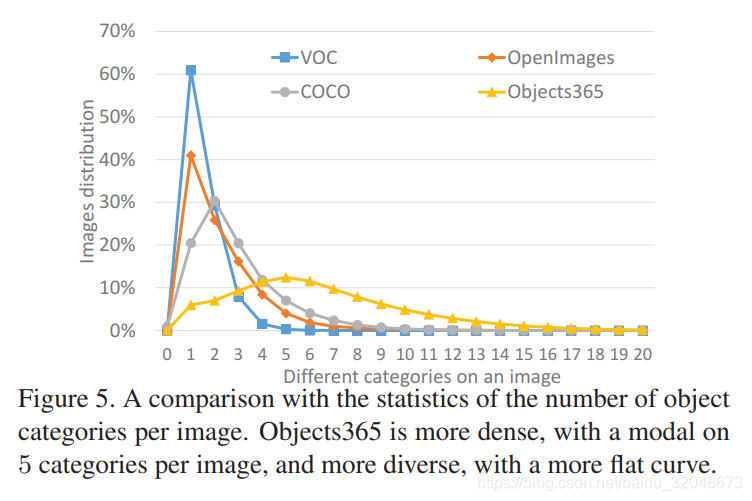
 介绍Objects365数据集,拥有365类目标,超600k训练图片,逾千万bboxes,为迄今最大全注释目标检测数据集。预训练模型在COCO测试中表现优于ImageNet模型,且达到相同精度所需时间仅为后者十分之一。
介绍Objects365数据集,拥有365类目标,超600k训练图片,逾千万bboxes,为迄今最大全注释目标检测数据集。预训练模型在COCO测试中表现优于ImageNet模型,且达到相同精度所需时间仅为后者十分之一。
总览:
1.目标检测数据,365类,约600k训练图片,超过一千万的bboxes。迄今为止最大的目标检测数据集(全注释的)。
2.服务于更好的未来研究:局部敏感类型的任务,如目标检测,语义分割
3.在COCO测试下,Objects365上预训练的模型比在ImageNet上预训练的模型高5.6个点(90K次迭代)。而在540K次迭代下,仍然高2.7个点。同时到达同样的精度,前者finetuing 时间为后者的1/10。
数据使用性能:
数据对比:
 998
1472
764
998
1472
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























