




 本文介绍了Objects365目标检测数据集,它由旷视和北京智源人工智能研究院联合推出,图像在自然场景收集,标注丰富。文中给出了2019和2020版本的下载地址,还说明了如何筛选所需类别,将指定类型的数据标注转换成XML格式,并生成对应图片及标注列表。
本文介绍了Objects365目标检测数据集,它由旷视和北京智源人工智能研究院联合推出,图像在自然场景收集,标注丰富。文中给出了2019和2020版本的下载地址,还说明了如何筛选所需类别,将指定类型的数据标注转换成XML格式,并生成对应图片及标注列表。
Objects365数据简介及数据转换为XML格式
注:Obj365和COCO数据集转换为xml格式以及转为yolo的txt格式,xml数据统计处理更改见GitHub:https://github.com/lidc1004/Object-detection-converts
1. Objects365数据集介绍
-
Objects365是旷视和北京智源人工智能研究院联合推出了目标检测任务的新基准。它的所有图像数据都是在自然场景设计和收集的。该Objects365目标检测数据集主要用于解决具有365个对象类别的大规模检测,并为目标检测研究提供多样化、实用性的基准。官方网站:http://www.objects365.org/overview.html -
Objects365在63万余张图像上标注了365个对象类,训练集中有超过1000万个边界框,超越了Pascal VOC、ImageNet和COCO数据集。下表给出了Objects365与之前所有的目标检测数据集在图像数量、边界框数量、对象类数量等参数上的对比。经过研究后发现,Objects365的图像数量是COCO的5倍,边界框是COCO的11倍,对象种类数和平均边界框数也是最大的。Objects365包括了人、衣物、居室、浴室、厨房、办公、电器、交通、食物、水果、蔬菜、动物、运动、乐器14个大类,每一类都有数十个小类。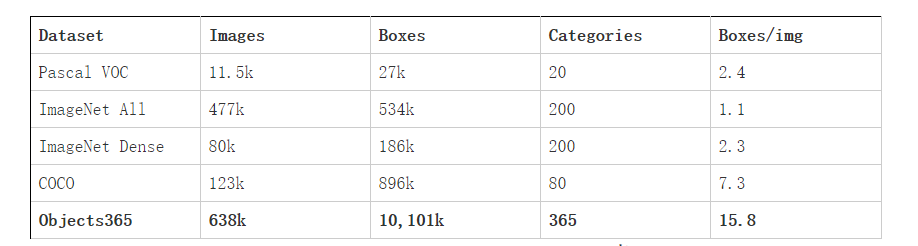
2. 数据集获取
Objects365数据集共两个版本:2019 Objects365目标检测数据集,2020 Objects365物体检测数据集。
- 2019版本官方不在提供下载,这里提供百度云盘下载地址:链接: https://pan.baidu.com/s/1q1kpu1TWSobRhoXr-TE9PA 提取码: qiva 复制这段内容后打开百度网盘手机App,操作更方便哦
- 2020版本官方下载地址:https://open.baai.ac.cn/data-set-enter-detail/12647
3. 数据集处理
Objects365数据集较大,实际使用时可能不需要那么多类别,故需要筛选自己需要的类别并将指定类型的数据标注转换成XML格式,并生成对应的图片及标注列表。其中365种类别在object365_dict.txt中详细显示,博客Object365数据集365种类别名称中也有具体内容。
其中XML格式定义如下:
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename> //文件名
<source> //图像来源
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //图像尺寸(宽、高以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //是否用于分割
<object> //检测到的物体
<name>horse</name> //物体类别
<pose>Right</pose> //拍摄角度
<truncated>0</truncated> //是否被截断
<difficult>0</difficult> //目标是否难以识别
<bndbox> //bounding-box(包含左上角和右下角x,y坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> //检测到多个物体,依次顺延
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
3.1 数据准备
- Objects365数据集目录结构如下:
/path/to/objects365
Annotations
train
train.json
val
val.json
Images
train
*.jpg
val
*.jpg
3.2 数据处理
主要包含两个代码,obj365_main.py和object365_to_voc.py,整体数据处理过程以及其他目标检测数据集转换为xml格式以及yolo的txt格式,详情见个人GitHub,链接:https://github.com/lidc1004/Object-detection-converts,有帮助请点个star。
如果登不进去也可在博客资源下载,代码下载链接(不需要积分):https://download.youkuaiyun.com/download/lidc1004/19269039
处理过程如下:
python obj365_main.py -i "data/obj365" -o "output/sport" -c 80 92 97 112 113 132 141 143 144 165 170 177 182 183 187 195 199 202 214 228 272 279 291 297
其中 -i 为数据集输入路径, -o为转换输出路径, -c为类别序号,可根据实际情况进行选择。
3.3 数据输出
输出目录结构如下
/path/to/output
annotations_xml_train // 标注目录
xxx.xml // 标注文件
yyy.xml // 标注文件
annotations_xml_val // 标注目录
xxx.xml // 标注文件
yyy.xml // 标注文件
annotations_xml_object365_train.txt
annotations_xml_object365_val.txt
其中列表文件格式
XML文件路径 图片路径 [类别1 类别2 ...]
XML文件路径为相对于输出目录的相对路径,图片路径为相对于输入目录的相对路径


















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









