




第2章深度学习和神经网络
激活函数
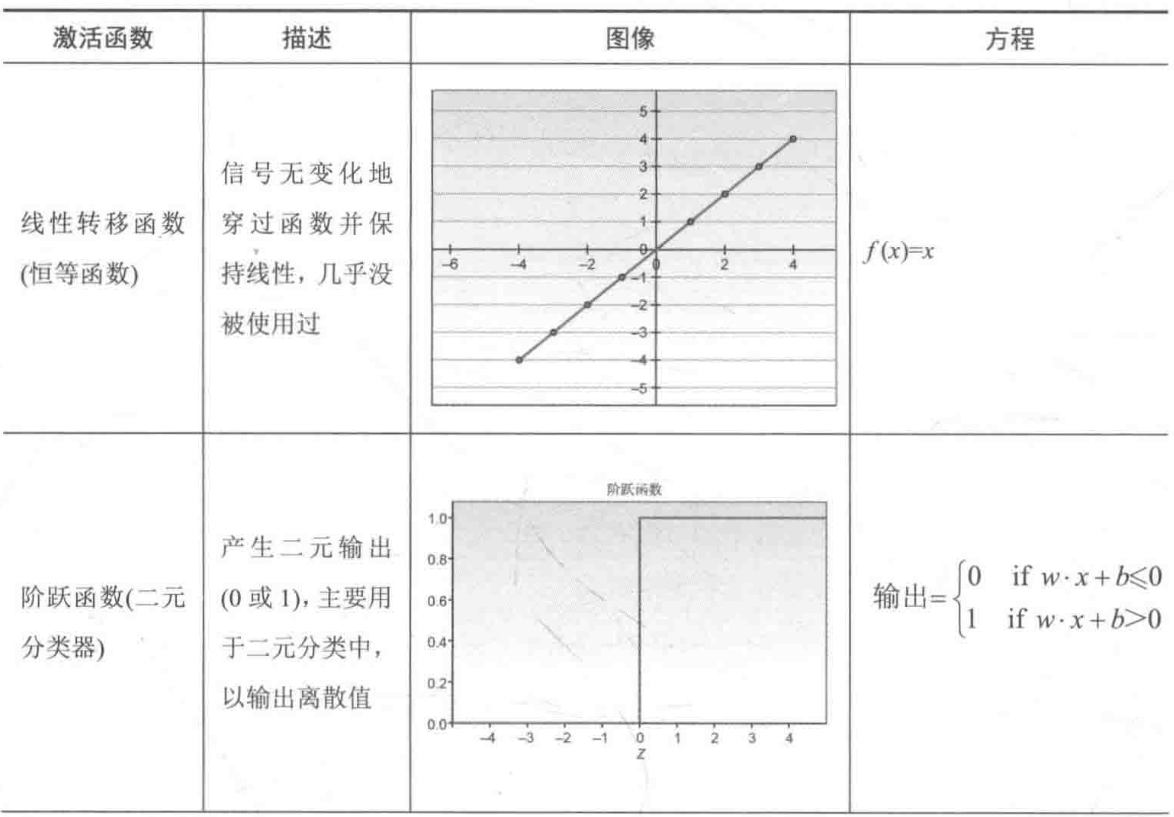

sigmoid/Logistic 函数
- 特点:
- 输出可解释为概率,但存在 “饱和区”(输入绝对值大时梯度趋近于 0),导致梯度消失。
- 输出非零中心化,可能影响后续层学习。
- 应用:二元分类输出层,如逻辑回归、神经网络二分类Fast类怎么加速的?:任务。
softmax 函数
- 特点:
- 适用于多分类问题(如图像分类 10 个类别)。
- 与交叉熵损失函数结合时,梯度计算更稳定。
- 应用:多分类任务的输出层,如 ImageNet 图像分类。

修正线性单元(ReLU)
- 特点:
- 解决梯度消失问题(正数区域梯度为 1,更新效率高)。
- 计算速度快,缓解过拟合(稀疏激活特性)。
- 缺点:负数区域输出恒为 0,可能导致 “神经元死亡”(无法更新)。
- 应用:几乎所有神经网络的隐藏层,如 CNN、RNN。
Leaky ReLU
- 特点:
- 负数区域梯度非零,解决 ReLU 的 “死亡” 问题。
- 超参数 α 可调整,但实际中常取固定值,效果优于 ReLU。
- 应用:替代 ReLU 用于隐藏层,尤其在对负数输入敏感的场景。
优化算法
优化是通过调整模型参数(如权重和偏置),使误差函数(损失函数)最小化的过程。其核心是找到一组参数,使得模型预测值与真实值的差距最小。深度学习中,优化算法通常基于梯度下降原理,通过迭代更新参数来逼近最优解。
梯度下降算法及其变体
1. 批梯度下降(Batch Gradient Descent, BGD)
- 原理:使用整个训练集计算梯度并更新参数。
- 优点:梯度计算稳定,收敛路径平滑,易找到全局最优解。
- 缺点:
- 训练集大时计算成本高,内存需求大。
- 迭代速度慢,不适用于大规模数据。
- 应用场景:小规模数据集或计算资源充足的场景。
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
- 原理:每次使用一个训练样本计算梯度并更新参数。
- 优点:
- 计算效率高,每次迭代仅需一个样本。
- 随机性强,易跳出局部最优,接近全局最优。
- 缺点:
- 梯度噪声大,收敛路径震荡,需小学习率稳定。
- 无法利用矩阵运算加速,训练速度可能慢于批量处理。
- 应用场景:大规模数据集或在线学习场景。
3. 小批梯度下降(Mini-Batch Gradient Descent, MB-GD)
- 原理:将训练集划分为小批量(Mini-Batch),每次用一个批量计算梯度
- 优点:
- 结合 BGD 和 SGD 的优势,兼顾计算效率和稳定性。
- 支持矩阵运算加速,训练速度快。
- 缺点:
- 超参数(批量大小)需调优,过小易受噪声影响,过大内存压力大。
- 应用场景:默认优化方式,适用于大多数深度学习任务。
| 方法 | 更新粒度 | 计算复杂度 | 优点 | 缺点 |
|---|---|---|---|---|
| 批量梯度下降 (BGD) | 整个训练集 | 高 | 优化稳定,适合小规模数据 | 计算开销大,不适合大规模数据集 |
| 随机梯度下降 (SGD) | 单个样本 | 低 | 实现简单,收敛快,接近全局最优,适合大规模数据集 | 优化过程不稳定,可能震荡,收敛不精确 |
| 小批量梯度下降 (Mini-Batch GD) | 小批量样本 (K 个样本) | 中 | 平衡效率和稳定性,适合大规模数据集 | 噪声仍然存在,需要调节小批量大小 |
勿混淆batch_sizce和cpoch(训练轮数)的概念。当训练集中的所有数据都被训练了一 次时,意味着完成了一个epoch。batch指要计算梯度的那组训练样本的数量。例如, 如果训练数据集中有1000个样本,设置batch_size=256,则epoch 1=batch1(256 个样本)+batch2(256个样本)+batch3(256个样本)+batch4(232个样本)。
误差函数
一、误差函数的定义
误差函数(Error Function),也称成本函数(Cost Function)或损失函数(Loss Function),用于衡量神经网络预测值与真实值之间的差异。其核心目标是量化模型的 “错误程度”,为模型优化提供方向(如梯度下降的优化目标)。
二、误差函数的意义
- 优化方向指引:误差函数值越小,模型预测越接近真实值,优化算法(如梯度下降)通过最小化误差函数更新模型参数。
- 模型评估标准:作为衡量模型性能的量化指标,指导超参数调优和架构设计。
三、常见误差函数类型及应用
1. #均方误差(Mean Squared Error, MSE)
- 公式:
 其中,(hat{y}_i) 为预测值,(y_i) 为真实值,N 为样本数。
其中,(hat{y}_i) 为预测值,(y_i) 为真实值,N 为样本数。 - 适用场景:回归问题(如房价预测、温度预测)。
- 优点:数学性质良好,导数计算简单,梯度方向明确。
- 缺点:对异常值敏感(平方项放大极端误差)。
- 使用条件:
-
任务类型为回归问题
- 输出为连续数值,而非离散类别。例如:
- 房价预测(输出价格数值)、温度预测(输出具体温度值)、股票价格走势预测等。
- 核心要求:预测值与真实值的差异可通过数值距离衡量,且数值差异的大小具有实际意义。
- 输出为连续数值,而非离散类别。例如:
-
输出层无需激活函数或使用线性激活
- 回归任务的输出层通常不使用激活函数,或仅使用线性激活(如恒等函数),直接输出连续值。
- 若使用非线性激活(如 sigmoid),需确保输出范围符合任务需求(如温度预测中 sigmoid 将输出限制在 (0,1),显然不合理)。
-
数据分布相对均匀,异常值较少
- MSE 对异常值敏感(平方项放大极端误差),若数据中存在显著异常值(如房价数据中混入豪宅价格),可能导致模型过度拟合异常样本。
- 解决方案:预处理时去除异常值,或改用平均绝对误差(MAE)。
2. #交叉熵损失(Cross-Entropy Loss)
- 公式:
 其中,M 为类别数,(y_{i,j}) 为真实类别概率(one-hot 编码),(hat{y}_{i,j}) 为预测概率。
其中,M 为类别数,(y_{i,j}) 为真实类别概率(one-hot 编码),(hat{y}_{i,j}) 为预测概率。 - 适用场景:分类问题(如图像分类、情感分析)。
- 优点:梯度稳定,当预测概率接近真实标签时,梯度逐渐减小,训练过程更平滑。
- 示例:多分类任务中,配合 softmax 激活函数,输出类别概率分布。
- 使用条件:
-
任务类型为分类问题
- 输出为离散类别标签,而非连续数值。例如:
- 图像分类(区分 “猫”“狗”“鸟” 等类别)、手写数字识别(0-9 类别)、情感分析(正面 / 负面)。
- 核心要求:模型需预测样本属于各分类的概率,而非具体数值。
- 输出为离散类别标签,而非连续数值。例如:
-
输出层激活函数匹配分类场景
- 多分类任务:使用
softmax激活函数,将输出转换为概率分布(各分类概率和为 1),如 ImageNet 图像分类。 - 二分类任务:使用
sigmoid激活函数,输出属于正类的概率(范围 [0,1]),如垃圾邮件检测。
- 多分类任务:使用
-
标签需为 one-hot 编码或概率分布
- one-hot 编码:真实标签转换为仅目标类别为 1、其余为 0 的向量。例如,三分类中真实类别为第 2 类时,标签为
[0, 1, 0]。 - 软标签场景:若标签本身是概率分布(如教师模型的输出),交叉熵可衡量预测分布与软标签的差异(如知识蒸馏)。
- one-hot 编码:真实标签转换为仅目标类别为 1、其余为 0 的向量。例如,三分类中真实类别为第 2 类时,标签为
-
模型输出非归一化的 logits
- 交叉熵损失的输入是神经网络前向传播的原始输出(logits,未经过 softmax/sigmoid 归一化),损失函数内部会自动处理概率计算。
- 错误示例:若将 softmax 的输出再次输入交叉熵,会导致梯度计算错误,必须直接使用 logits 作为损失函数输入。
-
数据不平衡场景需额外处理
- 交叉熵损失对类别不平衡敏感(如少数类样本占比不足 1%),可能导致模型偏向多数类。
- 解决方案:使用加权交叉熵(对少数类增加权重)、数据增强(扩充少数类样本)或焦点损失(Focal Loss)。
3. 平均绝对误差(Mean Absolute Error, MAE)
- 公式:

- 特点:对异常值鲁棒性优于 MSE,但导数不光滑,优化效率略低。
四、误差函数的选择原则
- 任务类型:
- 回归问题:首选 MSE,次选 MAE。
- 分类问题:多分类用交叉熵 + softmax,二分类用交叉熵 + sigmoid。
- 数据特性:
- 含异常值的数据:MAE 优于 MSE。
- 概率输出需求:交叉熵更适合(如需要预测类别概率)。
- 数学性质:
- 交叉熵的梯度特性更适合分类任务,避免 sigmoid/tanh 的梯度消失问题。
五、关键总结
误差函数是深度学习模型优化的核心目标,其选择直接影响模型的训练效率和预测性能。均方误差和交叉熵分别作为回归和分类任务的标配函数,而理解其数学原理(如梯度计算、对异常值的敏感性)是调优模型的基础。
第3章卷积神经网络
CNN基本组件
一、卷积层(Convolutional Layer)
核心作用:通过滑动卷积核对输入图像进行特征提取,捕捉图像中的局部模式(如边缘、纹理等)。
- 工作原理
- 卷积操作:卷积核在输入图像上按指定步幅滑动,对每个局部区域进行加权求和,生成特征图。
- 激活函数:通常在卷积后应用 ReLU 等非线性激活函数,引入非线性能力,增强网络表达力。
- 关键超参数
- 滤波器数量:决定输出特征图的深度,数量越多,提取的特征越丰富。
- 核大小:常见为 3×3、5×5,小核可提取精细特征,大核捕捉全局模式。
- 步幅(Stride):控制卷积核滑动的步长,步幅越大,输出特征图尺寸越小。
- 填充(Padding):通过在图像边缘补零,保持特征图尺寸(如 “same” 填充)或缩小尺寸(如 “valid” 填充)。
- 公式:
二、池化层(Pooling Layer)
核心作用:对特征图进行下采样,减少参数数量和计算复杂度,同时保留关键特征。
- 常见类型
- 最大池化(Max Pooling):提取局部区域的最大值,保留显著特征,应用最广泛。
- 平均池化(Average Pooling):计算局部区域的平均值,平滑特征,减少噪声。
- 关键参数
- 池化大小:如 2×2、3×3,决定下采样的比例(如 2×2 池化使特征图尺寸减半)。
- 步幅:通常与池化大小相同,确保无重叠下采样。
| 维度 | 卷积层(Convolutional Layer) | 池化层(Pooling Layer) |
|---|---|---|
| 核心目标 | 提取图像局部特征(如边缘、纹理、形状等),构建层次化特征表示。 | 对特征图下采样,减少参数数量与计算复杂度,保留关键特征。 |
| 特征处理 | 通过卷积核滑动窗口提取空间特征,逐层抽象从低级到高级的语义信息。 | 压缩特征图尺寸,降低空间维度,增强特征的平移不变性。 |
| 数学操作 | 加权求和:输入图像与卷积核进行滑动卷积,生成特征图。 | 下采样:对局部窗口内的像素取最大值(最大池化)或平均值(平均池化)。 |
| 可学习参数 | 有(卷积核权重、偏置),需通过训练优化。 | 无(仅执行固定逻辑操作,如取最大值)。 |
| 关键参数 | - 滤波器数量:决定输出特征图深度。 - 核大小:常见 3×3、5×5,控制局部感知范围。 - 步幅(Stride)、填充(Padding):调整特征图尺寸。 | - 池化大小:常见 2×2、3×3,决定下采样比例。 - 步幅:通常与池化大小相同(如 2×2 池化搭配步幅 2)。 |
| 特征抽象 | 浅层提取边缘、线条等低级特征,深层组合为语义概念(如 “车轮”“人脸”)。 | 不改变特征语义,仅通过降维增强特征的鲁棒性(如对图像平移、缩放的不变性)。 |
| 参数与计算量 | 增加参数数量(如 3×3 卷积核 + 64 滤波器,输入 3 通道时参数为 (3×3×3×64=1728)。 | 减少参数与计算量(如 2×2 最大池化使特征图尺寸减半,参数减少 75%)。 |
| 过拟合控制 | 通过权值共享与局部连接缓解过拟合,但深层网络仍需结合 Dropout 等技术。 | 直接通过降维减少模型复杂度,间接抑制过拟合。 |
| 典型应用位置 | 通常位于网络前端与中部,逐层堆叠以提取多层特征。 | 常紧跟在卷积层之后,每 1-2 个卷积层后添加一次池化。 |
三、全连接层(Fully Connected Layer)
核心作用:将提取的特征整合,通过权重矩阵映射到分类空间,实现最终分类。
- 结构特点
- 层中每个神经元与上一层所有神经元相连,将多维特征压缩为一维向量。
- 输出层常搭配 Softmax 激活函数,生成各类别的概率分布。
- 应用场景
- 位于网络末端,完成特征整合与分类决策,如 ImageNet 图像分类任务中输出 1000 类的概率。
添加dropout层以避免过拟合
一、过拟合定义
过拟合指模型在训练集上表现优异,但在未见过的验证集或测试集上泛化能力差,本质是模型 “记住” 了训练数据的细节特征,而非学习通用模式。例如,复杂网络可能过度拟合训练数据中的噪声或特殊样本,导致在新数据上预测失效。
二、dropout 层定义
dropout 是一种正则化技术,在训练过程中以指定概率(舍弃率p)随机关闭神经元,迫使网络学习更鲁棒的特征。被关闭的神经元在当前迭代中不参与前向传播和反向更新,相当于训练多个 “子网络” 的集成,提升模型泛化能力。
三、dropout 层的重要意义
- 减少神经元依赖:防止神经元间形成固定协同适应关系(如某组神经元仅在特定输入下激活),迫使网络学习更独立的特征表示。
- 类比解释:如用杠铃锻炼时绑住单臂,迫使双臂均衡发力;dropout 通过随机丢弃神经元,避免某部分神经元主导预测,使网络整体学习更均衡。
- 抗噪声能力:通过随机丢弃,模型对输入噪声的敏感度降低,减少对特定样本的依赖。
四、dropout 层在 CNN 架构中的位置
- 典型位置:通常添加在全连接层(FC)之间,或扁平化(Flatten)操作之后。因全连接层参数多、易过拟合,dropout 在此处效果显著。
- Keras 实现:
from keras.layers import Dropout model.add(Dropout(rate=0.3)) # 舍弃率0.3,即30%神经元被随机关闭 - 参数调优:舍弃率
rate常见取值 0.3~0.5,过拟合严重时可增大,但过高会导致信息丢失(如rate=0.5)。
五、核心总结
dropout 通过随机丢弃神经元打破网络的固定依赖模式,是缓解过拟合的有效手段。在 CNN 中,其与 L2 正则化、数据增强等技术结合使用时,可显著提升模型在未知数据上的泛化能力。
第4章构造DL项目以及超参数调优
正则化技术
正则化技术用于缓解神经网络的过拟合问题,通过限制模型复杂度或扩充训练数据,提升模型的泛化能力。
一、L2 正则化
1. 定义与原理 通过在误差函数中添加正则项,强制权重值趋近于 0,从而简化模型结构,避免过拟合。
其中,λ为正则化参数,m 为样本数,(|w|)为权重的 L2 范数
2. 作用机制
- 权重更新时,正则项导数促使权重值减小(即 “权重衰减”),削弱不重要特征的影响。
- 简化网络结构:权重趋近于 0 时,部分神经元作用被抑制,等效于减少网络复杂度。
3. 实现与调优
- 在 Keras 中,通过
kernel_regularizer=regularizers.l2(λ)添加到层中。 λ为超参数,默认值常有效,过拟合时可增大 λ 以增强正则化强度。
二、Dropout 层
1. 定义与原理 训练时以一定概率(舍弃率p)随机关闭神经元,迫使网络学习更鲁棒的特征,减少神经元间的依赖。
2. 作用机制
- 每次迭代中,神经元以概率
p被临时丢弃,剩余神经元需独立学习特征,避免单一神经元主导预测。 - 等效于集成多个 “子网络”,提升模型泛化能力。
3. 实现与调优
- 在 Keras 中,通过
Dropout(p)添加到层间,典型p取值为 0.3~0.5。 - 过拟合时增大
p,但过高会导致信息丢失,需结合验证集调整。
三、数据增强
1. 定义与原理 通过对原始图像进行几何变换或像素调整,生成新训练样本,扩充数据集多样性,避免模型记忆特定样本特征。
2. 常用技术
- 几何变换:翻转、旋转、缩放、裁剪。
- 像素调整:亮度变化、对比度调整、噪声添加。
- 示例:对数字图像旋转或翻转后,仍保留类别标签(如 “6” 旋转后仍为 “6”)。
3. 实现与作用
- 在 Keras 中,通过
ImageDataGenerator配置变换参数(如horizontal_flip=True)。 - 作为 “廉价” 的正则化方法,无需额外标注数据,直接提升模型对样本变异的适应性。
四、核心总结
| 技术 | 核心思想 | 优势 | 调优关键点 |
|---|---|---|---|
| L2 正则化 | 强制权重衰减,简化网络 | 计算高效,不改变网络结构 | λ 需根据过拟合程度调整 |
| Dropout | 随机丢弃神经元,减少依赖 | 避免复杂协同适应 | 舍弃率p通常 0.3~0.5 |
| 数据增强 | 扩充训练数据多样性 | 无额外成本, |
批量归一化
一、协变量偏移问题
- 定义:当神经网络训练时,隐藏层输入的分布随参数更新而不断变化,导致后续层需持续适应新分布,这种现象称为协变量偏移。
- 影响:
- 深层网络中,输入分布的变化会导致梯度消失或爆炸,训练收敛缓慢。
- 模型需频繁调整参数以适应新分布,降低训练效率。
二、BN 的工作原理
- 核心目标:通过标准化隐藏层输入,减少内部协变量偏移,使各层输入分布稳定。
- 数学步骤:

- 关键作用:
- 使输入分布稳定在均值 0、方差 1 附近,加速梯度下降收敛。
- Γ和β允许网络自主调整最优分布,避免标准化抑制特征表达。
三、BN 在 Keras 中的实现
- 添加方式:在卷积层或全连接层后插入
BatchNormalization层。from keras.layers import BatchNormalization model.add(Conv2D(64, kernel_size=3, ...)) model.add(BatchNormalization()) # 对卷积输出进行归一化 model.add(Activation('relu')) - 参数说明:
- 无需手动设置超参数,Γ和β由网络自动学习。
- 训练时计算批量均值和方差,推理时使用全局均值和方差(基于训练集统计)。
四、BN 的核心优势
- 加速训练:稳定输入分布,允许使用更大学习率,减少迭代次数。
- 提升泛化能力:类似正则化,降低模型对特定输入的依赖,减少过拟合。
- 支持更深网络:缓解深层网络的梯度问题,使训练极深层网络成为可能(如 ResNet)。
五、总结
批量归一化通过标准化隐藏层输入,解决了神经网络中的协变量偏移问题,是现代深度学习架构(如 CNN、ResNet)的关键组件。其数学原理简洁高效,实现方便,已成为提升模型性能的标配技术。
第7章使用R-CNN、SSD、YOLO进行目标检测
R-CNN
R-CNN不是通过深度神经网络来定位的单个端到端系统,更像是多个独立算法的组合。
缺点:
-
目标检测非常缓慢,2000个RoI(Region of Interest)。
-
训练是多级独立,不共享计算资源。
-
训练在时间和空间上都很昂贵。
R-CNN模型结构

R-CNN包括以下四个步骤:
-
为输入图像使用选择性搜索来选取多个高质量的提议区域。 这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
- 变形+提特征: 将每(截个候选区域变形后输入预训练CNN断输出层)提取固定长度的特征向量。
- 分类: 用每个类别的SVM分类器,基于特征向量判断候选区域是否包含该类物体。
- 定位: 用回归模型,基于特征向量精调候选区域的边界框位置和大小。
在类别预测和边框预测的时候:
-
累积多张图片的特征数据(通常5000张图片生成数百GB特征文件)。
-
使用liblinear等优化器一次性求解全局最优权重。
Fast R-CNN
-
整图特征提取:
- 输入图像(如 600×800×3)通过CNN主干网络(如VGG16)
- 输出一张共享特征图(如 37×50×512,尺寸缩小16倍)
-
候选区域映射:
- 将Selective Search生成的候选框坐标(原图坐标系)映射到特征图坐标系
- 映射公式:
特征图坐标 = 原图坐标 / 下采样比例 - 示例:原图候选框 [160, 240, 320, 480] → 特征图区域 [10, 15, 20, 30]
- 放在ROI Pooling层,经过全连接层后进行分类和回归
| 算法 | 核心突破 | 遗留问题 |
|---|---|---|
| R-CNN | 首用CNN+候选区域 | 速度慢、训练复杂 |
| Fast R-CNN | 特征共享(一张共享特征图)+对每个候选框图做ROI Pooling | 候选区域生成仍用CPU |
| Faster R-CNN | 用RPN(Region Proposal Network)替代Selective Search(选择高质量的提议区域) | 真正端到端 |
SSD
一、SSD 架构总览
- 设计目标:针对目标检测任务,提出单阶段 (One-Stage) 检测框架,相比两阶段 (Two-Stage) 方法(如 R-CNN)更高效,兼顾速度与精度。
- 核心思想:通过多尺度特征图直接预测目标边界框和类别,避免生成候选区域的耗时步骤。
- 工作流程:1输入图像骨干网络vgg等进行深度特征提取生成一个基础特征图2额外添加一些卷积层来生成更多、更深的特征图用于检测。5生成默认锚框4预测概率和框并NMS处理
二、SSD 关键组件
1. 基础网络
- 基于经典 CNN 架构(如 VGG、ResNet)作为骨干网络,提取基础特征。
- 示例:使用 VGG16 作为基础网络,移除全连接层,保留卷积层用于特征提取。
2. 多尺度特征层
- 机制:利用骨干网络不同深度的特征图,构建多尺度检测层(如 8×8、4×4 等尺寸),分别检测不同大小的目标。
- 浅层特征图(尺寸大):检测小目标。
- 深层特征图(尺寸小):检测大目标。
- 优势:无需生成候选区域,直接在各尺度特征图上预测边界框和类别概率,提升检测速度。
3. 边界框与类别预测
- 每个特征图的每个位置预设多个锚框 (Anchor Boxes),对应不同尺寸和宽高比。
- 对每个锚框,同时预测:
- 边界框偏移量(相对于锚框的调整)。
- 类别概率(属于各目标类别的概率)。
4. 非极大值抑制 (NMS)
- 处理同一目标的多个重叠预测框,保留置信度最高的框,去除冗余。
- 步骤:按置信度排序→迭代删除与当前最高置信度框重叠超过阈值的框。
| 框架 | 阶段数 | 候选区域生成 | 检测速度 | 精度 |
|---|---|---|---|---|
| R-CNN 系列 | 两阶段 | 有(如 Selective Search) | 慢 | 高 |
| SSD | 单阶段 | 无 | 快(如 30 FPS) | 中等(优于 YOLOv1,略低于 Faster R-CNN) |
核心总结
- SSD 通过单阶段多尺度检测,避免候选区域生成,大幅提升检测效率,适用于对实时性要求高的场景(如自动驾驶、监控系统)。
- 多尺度特征层设计是 SSD 的核心创新,使模型能同时处理不同大小的目标,而 NMS 则确保检测结果的准确性。
- 相比两阶段方法,SSD 牺牲部分精度换取速度,是工程落地中性价比高的选择。
YOLO
常识

卷积作用:提取特征、共享参数、平移不变性、降维
网络为什么要许多层卷积
层度加深,卷积核减小带来的好处
卷积核好处
卷积层带来的好处(浅层时?加深后?)
感受野?
层数和感受野的关系:层数增加 → 感受野扩大,深层需要大感受野以理解全局语义,浅层需要小感受野保留局部细节。
为什么倾向使用卷积层而不使用全连接层?:大幅降低参数量、保留空间结构信息,破坏空间拓扑关系、高效提取平移不变特征,同一物体出现在不同位置需重新学习参数。
R-CNN工作流程,要知道它是两阶段窗口,为什么是两阶段,两阶段的特点,和优点(检测精确度高、两阶段)。
Fast类怎么加速的?
SSD工作流程、(工作原理)
yolo核心思想、(工作原理)、不考工作流程、问有多少个边界框需要去预测?还要知道预测类别。
第5章先进的CNN架构的优缺点:对这些网络架构要了解(核心构建)?他们的优缺点?带来了什么样的观念上的改变?
“Same” Padding 的目标是让卷积操作后的输出特征图与输入特征图的大小保持一致。具体来说,如果卷积核大小是 K×K,步长为 1,那么“same” padding 的填充大小 P 通常满足:(K-1)/2这样填充后,输出特征图的大小就会与输入特征图的大小相同。
为什么倾向使用卷积层而不使用全连接层?
1大幅降低参数量、2保留空间结构信息,破坏空间拓扑关系、3高效提取平移不变特征,同一物体出现在不同位置需重新学习参数。
感受野?
在输入图像(或特征图)上,某个特定层(通常是卷积层或池化层)的单个输出单元(神经元)“看到”或“感受”到的区域大小。
感受野就是这个输出单元的值,是由输入图像上多大范围(区域)内的原始像素(或前一层的特征)计算得来的。
卷积作用
提取特征、共享参数、平移不变性、降维。
- 特征分层提取:通过滑动窗口捕捉图像局部特征(如边缘、纹理),浅层卷积学习基础元素(如直线),深层组合成复杂结构(如车轮、人脸)。
- 保留空间信息:直接处理图像矩阵,维持像素间位置关系,避免全连接层的扁平化信息丢失。
- 参数共享:局部连接和权值共享减少参数数量,例如 3×3 卷积核仅需 9 个参数即可处理任意尺寸区域。
网络为何需要多层卷积
- 从简单到复杂、从局部到全局地学习特征。
- 浅层卷积学习边缘、角点等低级特征,深层逐步组合为物体部件(如眼睛、车轮)乃至整体结构(如人脸、汽车)。
- 如 CNN 通过 5-6 层卷积可识别 ImageNet 千类物体,依赖多层特征的逐层抽象。
- 增强表达能力:多层非线性变换(卷积 + 激活函数)使网络能拟合复杂视觉模式,解决非线性分类问题。获得强大的函数拟合能力。
- 逐步扩大感受野,理解图像的上下文和整体结构。
- 高效地利用参数,复用基础特征。
- 在提炼信息(降维)的同时提升语义级别、更抽象的特征学习。
深度加深与卷积核减小的好处?
1. 深度加深的优势:同上
2. 卷积核减小(如 3×3 替代 5×5)的优势
- 参数数量锐减:3×3 卷积核参数仅为 5×5 的 36%(9 vs. 25),减少过拟合风险,如 VGG 用连续 3×3 卷积替代大核。
- 等效感受野与更多非线性:两个 3×3 卷积层的感受野等效于 5×5 卷积,但包含两次 ReLU 激活,增强特征表达能力。
- 增加非线性层
- 计算效率更高
卷积核的核心好处
提取特征、共享参数、平移不变性、降维
- 局部连接局部感受野:仅处理图像局部区域,符合视觉感知的局部性(如人类识别物体先关注局部部件)。
- 参数共享:同一卷积核在图像不同位置使用相同权重,减少参数数量,且对平移不变性有效(如边缘检测不依赖位置)。
- 多尺度特征捕捉:不同大小卷积核(3×3、5×5)可捕捉不同尺度特征,小核适合细节,大核适合整体结构。
- 平移不变性
卷积层带来的好处
一、浅层卷积的核心优势
-
保留空间结构信息
- 直接处理原始像素,维持图像局部拓扑关系(如边缘、角点位置)。
- 避免全连接层破坏空间结构的问题。
-
提取局部细节特征
- 小感受野(3×3/5×5)聚焦微观模式:边缘(梯度变化)、纹理(重复模式)、颜色斑点。
-
高效参数利用
- 参数共享:同一卷积核滑动检测全图相似特征(如所有竖边)。
- 局部连接:仅计算局部区域,参数量远低于全连接层(如3×3卷积核仅需9个权重)。
-
平移不变性基础
二、加深卷积层的核心优势
-
感受野指数级扩大
-
组合低级特征为高级语义:特征抽象层级提升:
边缘 → 纹理 → 部件 → 物体整体(如:竖边+横边 → 窗户 → 建筑) -
增强语义判别能力
- 深层特征对类别语义敏感(如“猫 vs 狗”),而非浅层的低级纹理。
- 可学习复杂决策边界(如根据“车轮+车窗+车灯”组合识别汽车)。
-
鲁棒性提升:即对输入中的扰动、噪声、形变、遮挡、视角变化等不敏感,仍能做出正确判断。
局部连接、参数共享和空间保留机制
- 平移不变性:同一特征在图像不同位置的响应一致,如卷积核检测边缘时不依赖其在图像中的位置。
- 可堆叠性:多层卷积叠加等效于大感受野,同时保持计算效率,如两个 3×3 卷积层等效于 5×5 感受野,但参数更少。
- 稀疏交互:仅与局部区域连接,降低计算复杂度,适合处理高维图像数据。
检测和分类
分类:判断整个图片、输出单一类别标签;acc、混淆矩阵;关注全局
检测:定位目标、预测;输出多个坐标和类别标签;IOU、map;关注全局兼顾局部
R-CNN 核心工作原理
要知道它是两阶段窗口,为什么是两阶段,两阶段的特点,和优点(检测精确度高、两阶段)。
- 精度高的原因:
- 阶段1保障高召回率(不漏物体)
- 阶段2实现精细化分类与定位(CNN特征 + SVM + 边界框回归)
- 阶段1:生成候选区域(Region Proposal)
- 阶段2:对每个候选区域独立处理
-
为输入图像使用选择性搜索来选取多个高质量的提议区域。 这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域都将被标注类别和真实边界框。
- 变形+提特征: 将每(截个候选区域变形后输入预训练CNN断输出层)提取固定长度的特征向量。
- 分类: 用每个类别的SVM分类器,基于特征向量判断候选区域是否包含该类物体。
- 定位: 用回归模型,基于特征向量精调候选区域的边界框位置和大小。
在类别预测和边框预测的时候:
- 候选区域生成:早期用 Selective Search 生成约 2000 个候选框,后续 Faster R-CNN 引入区域建议网络(RPN)提升效率。
- 特征提取与分类:对候选框提取 CNN 特征,用 SVM 或全连接层分类,并用回归调整边界框坐标。
| 算法 | 核心突破 | 遗留问题 |
|---|---|---|
| R-CNN | 首用CNN+候选区域 | 速度慢、训练复杂 |
| Fast R-CNN | 特征共享(一张共享特征图)+对每个候选框图做ROI Pooling | 候选区域生成仍用CPU |
| Faster R-CNN | 用RPN(Region Proposal Network)替代Selective Search(选择高质量的提议区域) | 真正端到端 |
SSD 工作原理
- 单阶段检测:无需候选区域,直接在多尺度特征图上预测边界框和类别概率,提升速度。
- 多尺度特征层:
- 浅层特征图(如 8×8)检测小目标,深层(如 4×4)检测大目标,每个位置预设不同尺寸锚框。
- 对每个锚框输出边界框偏移量和类别概率,通过非极大值抑制(NMS)合并重叠框。
- 工作流程:
- 输入图像到骨干网络vgg等提取特征生成一个特征图
- 额外用一些卷积层来生成个更多的特征图用于预测
- 生成默认锚框
- 预测概率和框并NMS非极大值抑制处理
YOLO 核心思想
yolo核心思想、(工作原理)、不考工作流程、问有多少个边界框需要去预测?还要知道预测类别。
- 核心思想:YOLO 将目标检测任务视为回归问题,直接从图像中回归出边界框和类别概率 。它把输入图像划分为 S×S 的网格,每个网格负责预测图像中某一部分的目标 。若目标的中心点落在某个网格内,该网格就负责预测这个目标的边界框和类别 。这种方式使 YOLO 能在一个神经网络中同时完成分类和定位任务,避免了传统两阶段检测算法(如 Faster R-CNN)中先生成候选区域再进行分类和边界框回归的复杂过程,极大地提升了检测速度,同时其单阶段设计允许模型同时预测多个目标,还能从全局视角捕获目标之间的上下文关系,简化了模型训练流程 。
- 边界框预测数量与预测类别:每个网格预测B个bounding box(边界框)。
- 每个bounding box除了预测位置之外,
- 还要附带预测一个confidence值(置信度)。
- 每个网格还要预测C个类别的分数.
- 工作流程:
- 通多多层卷积池化提取特征输出特征图
- 划分特征图为S*S网格,每个网格输出值,(x,y,w,h,p,类别)
- NMS非极大值抑制算法处理。
第5章先进的CNN架构的优缺点:
一、LeNet-5

1. 优点
- 结构简单高效:首个成功应用的 CNN 架构,包含卷积层、池化层和全连接层,参数少,适合小数据集(如 MNIST 手写数字识别)。
- 基础架构启发:奠定了 CNN 的基本组件(卷积、池化、全连接),为后续架构提供设计范式。
2. 缺点
- 处理能力有限:仅适用于低分辨率、简单场景(如 28×28 像素图像),无法处理复杂自然图像。
- 缺乏非线性激活:早期版本使用 sigmoid 激活函数,存在梯度消失问题,训练效率低。
二、AlexNet

1. 优点
- 突破性性能:2012 年 ImageNet 夺冠,首次证明 CNN 在大规模视觉任务中的优势。
- 关键创新:
- 引入 ReLU 激活函数,解决 sigmoid 的梯度消失问题,加速训练。
- 使用 Dropout 层减少过拟合,提升模型泛化能力。
- 局部响应归一化(LRN)增强特征竞争力。
2. 缺点
- 计算资源密集:模型参数多(约 6000 万),需 GPU 并行计算,早期硬件部署困难。
- 架构不够优化:部分模块(如 LRN)后续被证明非必需,可简化。
三、VGGNet

1. 优点
- 结构统一简洁:仅使用 3×3 卷积核和 2×2 池化层,重复堆叠形成深层网络(如 VGG-16 含 16 层),设计范式清晰。
- 特征表达强:通过多层小卷积核的叠加,等效于大感受野,捕捉更复杂特征。
2. 缺点
- 参数数量爆炸:VGG-16 参数达 1.38 亿,训练需大量内存和计算资源,部署成本高。
- 效率低下:重复堆叠相同模块,计算冗余,推理速度慢。
四、Inception/GoogLeNet
1. 优点
- 多尺度特征融合:通过 Inception 模块并行使用 1×1、3×3、5×5 卷积和池化,捕捉不同尺度特征,提升检测精度。
- 参数高效:引入 1×1 卷积降维(如瓶颈结构),相比 VGG 参数减少 75%(仅 500 万参数)。
- 创新架构:首次使用全局平均池化替代全连接层,减少过拟合。
2. 缺点
- 结构复杂:模块设计繁琐,实现和调优难度大,对新手不友好。
- 训练耗时:多分支并行计算增加训练时间,需优化硬件配置。
五、ResNet(残差网络)
1. 优点
- 解决深度瓶颈:通过残差连接(y = x + F(x)),允许训练极深层网络(如 ResNet-152),避免梯度消失。
- 性能卓越:在 ImageNet 等任务中准确率显著提升,且深层网络仍保持训练稳定性。
- 泛化能力强:残差学习机制使模型对噪声和扰动更鲁棒。
2. 缺点
- 计算成本高:残差块增加前向和后向传播的计算量,推理速度较慢。
- 内存占用大:深层网络需要更多显存,部署到边缘设备困难。
六、核心对比与引用
| 架构 | 核心优势 | 主要短板 | 关键创新点 |
|---|---|---|---|
| LeNet-5 | 简单高效,奠定 CNN 基础 | 仅适用于简单任务 | 卷积 + 池化 + 全连接范式 |
| AlexNet | 首次证明 CNN 大规模潜力 | 参数多,硬件要求高 | ReLU、Dropout、LRN |
| VGGNet | 结构统一,特征表达强 | 参数爆炸,效率低 | 全 3×3 卷积核堆叠 |
| Inception | 多尺度特征,参数高效 | 架构复杂,调优困难 | Inception 模块、1×1 卷积降维 |
| ResNet | 突破深度限制,性能卓越 | 计算成本高,内存占用大 | 残差连接、恒等映射 |
基础NMS计算
输入框(格式:[x1, y1, x2, y2, score]):
A:[10, 20, 50, 60, 0.9]
B:[15, 25, 55, 65, 0.8]
C:[40, 30, 60, 70, 0.6]
D:[60, 10, 90, 40, 0.7]
参数:IoU阈值=0.5。
计算过程:
1.按得分score排序:[A(0.9), B(0.8), D(0.7), C(0.6)]。
处理A:
保留A,计算其余框的IoU:
IoU(A, B)=交集(35×35)/并集(40×40+40×40-35×35)=0.66 >0.5 → 抑制B。
IoU(A, C)=0.14 <0.5 → 保留C。
IoU(A, D)=0 → 保留D。此时候选框:[D(0.7), C(0.6)]
处理D(下一最高分):
IoU(D, C)=0 → 保留C。
处理C:无剩余框需比较。
结果:保留[A, D, C]。
- x1_inter =
max(8, 13)= 13- y1_inter =
max(15, 22)= 22- x2_inter =
min(45, 52)= 45- y2_inter =
min(55, 62)= 55计算交集面积(Area_inter)
交集区域的宽和高均为正值,说明有重叠:
- 宽 =
x2_inter - x1_inter=45-13= 32- 高 =
y2_inter - y1_inter=55-22= 33- Area_inter = 宽 × 高 =
32×33= 1056
预测20个西瓜中哪些是好瓜,这20个西瓜中实际有15个好瓜,5个坏瓜,某个模型预测的结果是16个好瓜,4个坏瓜。其中,预测的16个好瓜中有14个确实是好瓜,预测的4个坏瓜中有3个确实是坏瓜。注:好瓜为正例,坏瓜为反例。
(1)画出混淆矩阵。
(2)什么是精确率(Presion),计算准确率P。
(3)什么是召回率(Recall),计算召回率R。
(4)写出F1值的计算公式,求出本例中F1值。
| T | F | |
| P | 14 | 2 |
| N | 1 | 3 |

混淆矩阵包含四部分的信息:
1) 真阴率(TN)表明实际是负样本预测成负样本的样本数。
2) 假阳率(FP)表明实际是负样本预测成正样本的样本数。
3) 假阴率(FN)表明实际是正样本预测成负样本的样本数。
4) 真阳率(TP)表明实际是正样本预测成正样本的样本数。
精确度 (Precision)

一句话速记:预测中的真正比例——
召回率 (Recall)

一句话速记:真实中的真正比例 |
准确率 (Accuracy)

一句话速记:对角线/所有
F1 分数 (F1 Score)

一句话速记:2pr/(r+p)
inception
假设输入特征图通道数为a,各分支卷积核数量为为b,特征图尺寸不变。


分支1:(a*1*1+1)*b
分支2:(a*1*1+1)*b+(b*3*3+1)*b
分支3:(a*1*1+1)*b+(b*5*5+1)*b
分支4:(a*1*1+1)*b
- 输出特征图元素数量:因题目说 “特征图尺寸不变”,输出尺寸仍为 (S *S) ,通道数为分支的输出通道数(这里各分支输出通道数是 b ,所以元素数量 =S*S*b)。
resnet
 ResNet采用了与Inception相同的模式并创建了残差块。这些残差块堆叠在彼此之上以 形成网络架构。ResNet尝试解决在训练超深网络时致使网络退化的梯度消失问题。 ResNet团队引入了跳跃连接,使信息可直接从早期的层流入网络的深层,并为梯度的 传递创建了一个可替代的旁路。ResNet的根本性突破在于,使人们有可能训练数百层的超深神经网络。
ResNet采用了与Inception相同的模式并创建了残差块。这些残差块堆叠在彼此之上以 形成网络架构。ResNet尝试解决在训练超深网络时致使网络退化的梯度消失问题。 ResNet团队引入了跳跃连接,使信息可直接从早期的层流入网络的深层,并为梯度的 传递创建了一个可替代的旁路。ResNet的根本性突破在于,使人们有可能训练数百层的超深神经网络。
左侧残差块参数量计算
左侧残差块是典型的 “双 3×3 卷积 + 残差连接” 结构,流程为:
输入 x → 3×3 Conv → Batch Norm(参数 2 )→ ReLU(无参数 )→ 3×3 Conv → Batch Norm(参数 2 )→ + 输入 x(残差连接,无参数 )→ ReLU(无参数 )
逐层计算参数量:
-
第一层 3×3 卷积:
输入通道数为a,卷积核尺寸3×3,输出通道数b。
参数量 =(a × 3×3 + 1) × b = (9a + 1)b(+1是每个卷积核的偏置 )。 -
Batch Norm:b×2 -
第二层 3×3 卷积:
经过第一层卷积后,输入通道数变为b(因为第一层输出通道是b),卷积核尺寸3×3,输出通道数b。
参数量 =(b × 3×3 + 1) × b = (9b + 1)b。 -
残差连接与其他层:
ReLU无参数,残差连接是直接相加,也无参数。
所以,左侧残差块总参数量 = 第一层参数量 + 第二层参数量 +两个Batch Norm= (9a + 1)b + (9b + 1)b = 9ab + b + 9b² + b +2*b×2= 9ab + 9b² + 2b +4b。
右侧残差块参数量计算(Batch Norm无参数版本)
右侧残差块是 “带 1×1 卷积调整通道的残差结构”(应对输入输出通道不一致时的残差连接 ),流程为:
输入 x → 3×3 Conv → Batch Norm(无参数 )→ ReLU(无参数 )→ 3×3 Conv → Batch Norm(无参数 )→ + [输入 x → 1×1 Conv 调整通道](残差连接支路 )→ ReLU(无参数 )
逐层计算参数量:
-
第一层 3×3 卷积:
输入通道数a,卷积核尺寸3×3,输出通道数b。
参数量 =(a × 3×3 + 1) × b = (9a + 1)b。 -
第二层 3×3 卷积:
输入通道数b,卷积核尺寸3×3,输出通道数b。
参数量 =(b × 3×3 + 1) × b = (9b + 1)b。 -
残差连接支路的 1×1 卷积:
输入通道数a(与原始输入通道一致 ),卷积核尺寸1×1,输出通道数b(要和主支路输出通道匹配,才能相加 )。
参数量 =(a × 1×1 + 1) × b = (a + 1)b。 -
其他层:
Batch Norm和ReLU无参数,残差相加无参数。
所以,右侧残差块总参数量 = 第一层参数量 + 第二层参数量 + 残差支路参数量 = (9a + 1)b + (9b + 1)b + (a + 1)b
展开计算:
= 9ab + b + 9b² + b + ab + b
= 10ab + 9b² + 3b 。
总结
- 左侧残差块(纯双 3×3 卷积残差):
9ab + 9b² + 6b - 右侧残差块(带 1×1 卷积通道调整):
10ab + 9b² + 3b

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









