




程序员都知道,程序其实就是管输入、输出,中间的代码需要实现,只要输入、输出对就算对了。因此,我们要处理数据,第一步就是了解你的数据。
声明一下,本项目我也是跟着B站一个博主一步步做的,所以这里放一下他的 视频地址,有兴趣的同学也可以去看看,当然我也在做的过程中改良了一些代码。
1. 导入要用到的包
没啥解释的,numpy/pandas/matplotlib/seaborn要导入,本项目使用的算法是xgboost,也要导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import xgboost as xgb
import time
2. 载入数据
Kaggle官方提供的数据zip包中包含了4个csv文件:
- train.csv: 训练集,记录了门店的历史销售数据,给开发者自己使用。
- test.csv: 测试集,格式基本同train.csv,但是唯独少了销售金额列,最终用来基于训练好的模型,生成提交给Kaggle平台进行评估模型训练效果。
- store.csv: 门店主数据,记录了门店的。
- sample_submission.csv: 提交数据样例。
我们主要使用的就是train.csv和store.csv两个文件。好的,那我们导入数据。
train = pd.read_csv('./data/train.csv', dtype={'StateHoliday':np.string_})
test = pd.read_csv('./data/test.csv', dtype={'StateHoliday':np.string_})
store = pd.read_csv('./data/store.csv')
3. 查看数据
导入完毕后,我们需要查看一下数据集,对数据集有一个直观的认识,一般有如下几种方式:
- df.head(n): 查看数据集的前n行记录,不传n则默认是查看前5行
- print(df.shape): 统计一下数据集的行数、列数
- df.isnull().sum(): 按列统计一下数据集的空值情况
- df.info(): 统计数据集每列非空值个数以及每列的数据类型
- df[‘field_name’].unique(): 对于有限取值的字段(枚举类型或日期类型等),列出所有可能的值
可能不完整,我也是在不断学习中,但是通过上述方式,基本上可以对手头的数据有大概的了解。
执行如下代码:
display(train.head(), test.head(), store.head())
执行结果如下:
-
train.head()

-
test.head()
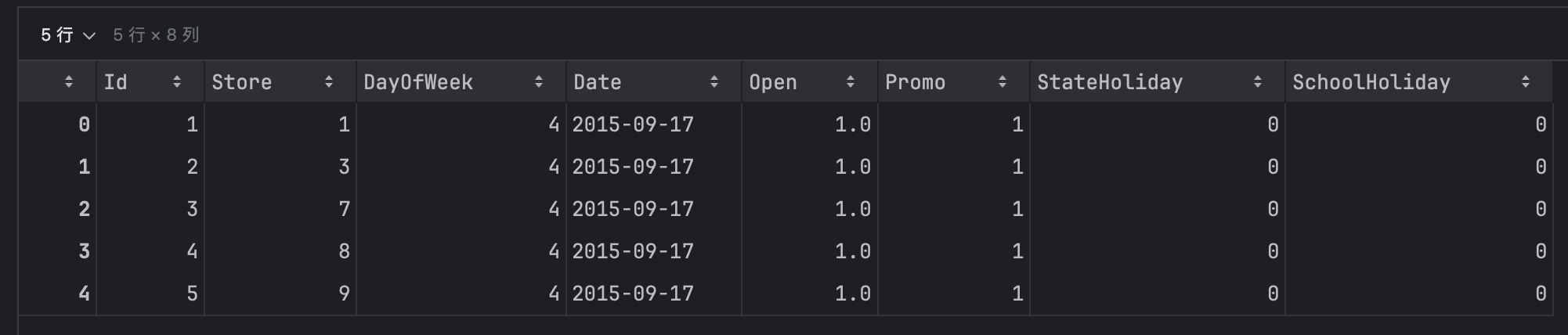
-
store.head()

我们发现,train和test两个数据集,结构基本一样,test少了一个Sales字段,因为test就是最终用来生成预测数据的。而store数据集,记录的就是门店主数据。
数据字典如下:
- train.csv/test.csv
| 编号 | 字段名 | 字段类型 | 字段含义 | 字段可能取值 |
|---|---|---|---|---|
| 1 | Store | 数字 | 门店编号 | 1/2/3 |
| 2 | DayOfWeek | 数字 | 该条销售记录在当前周的天数 | 5 |
| 3 | Date | 字符串 | 销售日期 | yyyy-mm-dd |
| 4 | Sales | 数字 | 销售金额 | 1000.5 |
| 5 | Customers | 数字 | 当天光顾门店的顾客数 | 123 |
| 6 | Open | 数字 | 当天是否开业 | 0-否,1-是 |
| 7 | Promo | 数字 | 是否有促销 | 0-否,1-是 |
| 8 | StateHoliday | 数字 | 是否是州假期 | 0-否,1-是 |
| 9 | SchoolHoliday | 数字 | 是否是学校假期 | 0-否,1-是 |
- store.csv
| 编号 | 字段名 | 字段类型 | 字段含义 | 字段可能取值 |
|---|---|---|---|---|
| 1 | Store | 数字 | 门店编号 | 1/2/3 |
| 2 | StoreType | 枚举 | 门店类型 | a/b/c/d |
| 3 | Assortment | 枚举 | 商品组合程度 | a/b/c |
| 4 | CompetitionDistance | 数字 | 竞争对手离门店的的距离 | 570.0 |
| 5 | CompetitionOpenSinceMonth | 数字 | 竞争对手开业月份 | 9.0 |
| 6 | CompetitionOpenSinceYear | 数字 | 竞争对手开业年份 | 2013 |
| 7 | Promo2 | 数字 | 是否处于持续促销 | 0-否,1-是 |
| 8 | Promo2SinceWeek | 数字 | 持续促销开始周数 | 2 |
| 9 | Promo2SinceYear | 数字 | 持续促销开始年份 | 2013 |
| 10 | PromoInterval | 字符串 | 促销月份 | Jan,Feb,Mar |
我们先从训练集train入手,执行如下代码查看各字段空值情况:
train.isnull().sum()
返回如下:
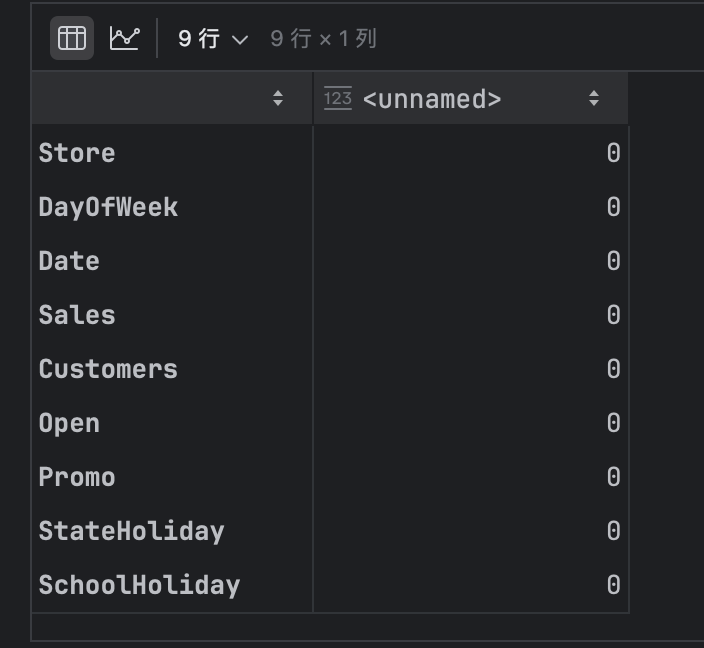
我们发现训练集居然取值非常规范,没有任何空值。注意这是一个不太正常的现象,一般来讲没有这么理想,但是,谁知道呢,可能是Kaggle官方提供的数据做了修正
好,那既然训练集非常完美,那么我们看一下测试集,运行代码:
test.isnull().sum()
返回值如下:
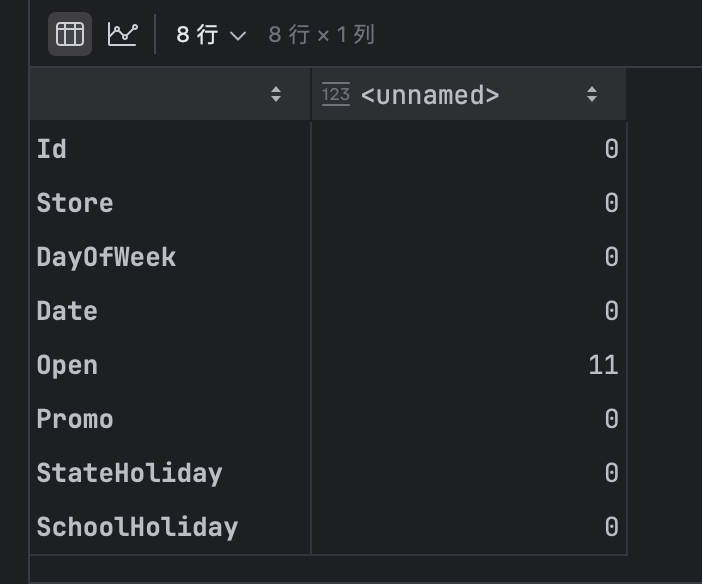
OK,测试集也还好,只有一个Open字段有11个空值,我们需要处理这11个空值。
这里插一个知识,在用算法进行机器学习过程中,我们的每个最终参与计算的字段,是不能有空值的,而且值必须为数字形式,不能为字符串形式,这个后面会涉及。
运行如下代码,打印出所有Open字段为空值的记录
cond = test['Open'].isnull()
test[cond]
返回结果如下
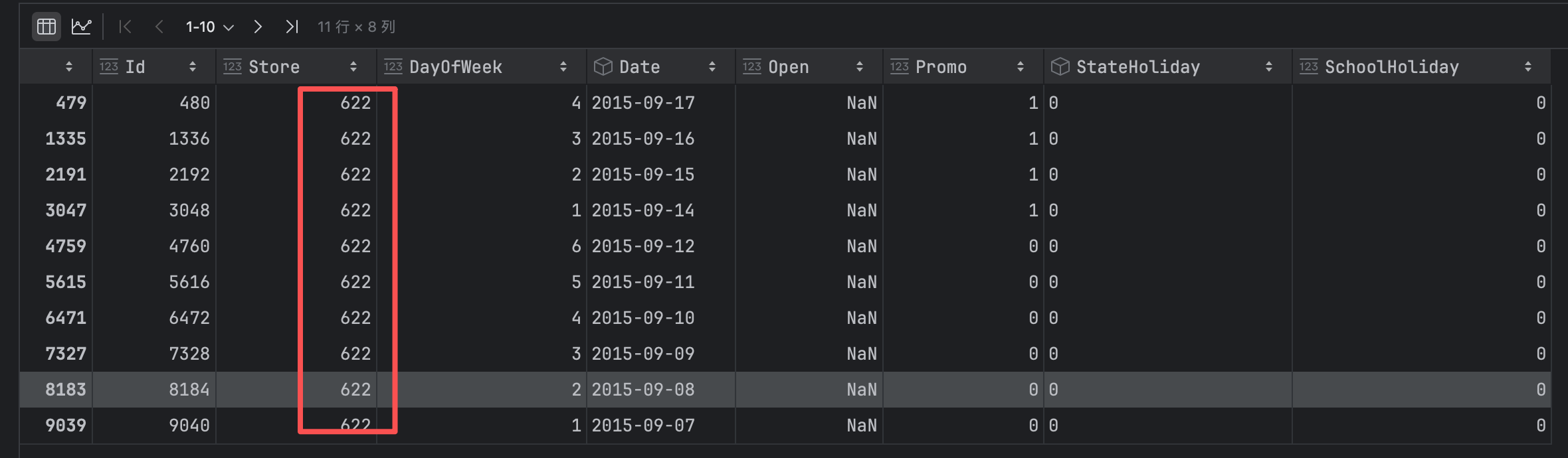
发现所有Open字段为空的都是编号为622的门店。按照上面对train训练集的探查,所有字段都有值,所以我们就猜测是不是能从train训练集中获得信息来填充test测试集。
所以我们去train数据集中过滤一下622门店的数据,运行以下代码:
cond = train['Store'] == 622
df = train[cond]
df.sort_values(by = 'Date').iloc[-50:, :]
上面代码中,我们按门店过滤一下数据,只取622门店,并且按照日期排序,并取最后50条记录(train训练集的时间跨度是2013-01-01 ~ 2015-07-31,测试集是2015-08-01 ~ 2015-09-17,我们看一下2015年7月622门店的开业情况,推测一下9月那几天可能的情况),对比发现,7月的那几天除了有一个周末,其余天数都是开业的,所以虽然我不知道测试集中2015-09-07 ~ 2015-09-17是否真的开业,但是我们知道2015-07的那几天的开业情况,所以我们“认为”9月份那几天全部补成1是大差不差的(虽然纯属一本正经地胡说八道,但是总比毫无缘由的拍脑袋强)。
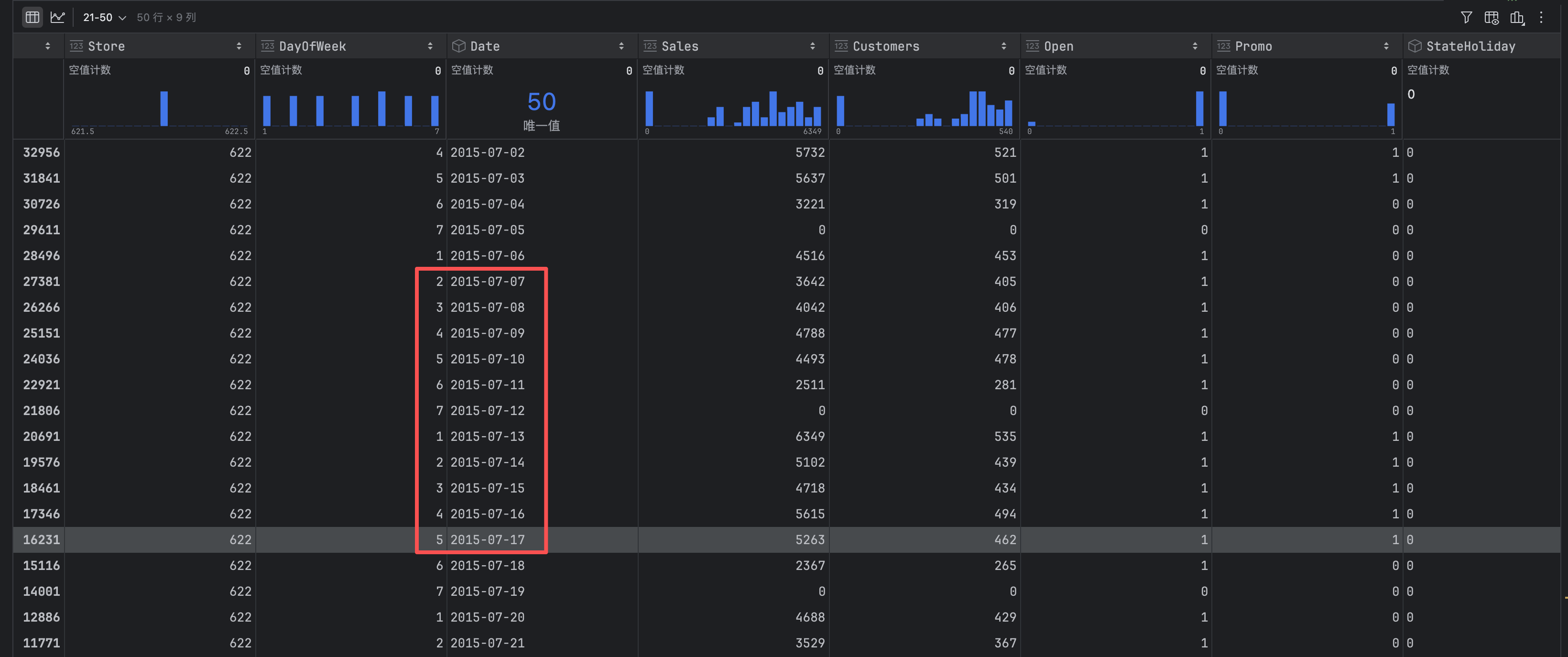
好了,如果我们把test数据集的Open字段补全了,那我们测试集的数据就算完整了。
接下来看store门店主数据。运行如下代码:
store.isnull().sum()
糟糕的情况来了,我们发现缺失值的情况还是满严重的,如下。
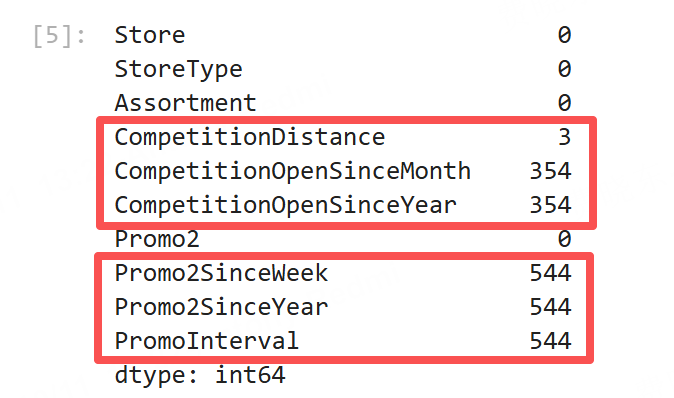
共有 6 个字段缺失。其中,CompetitionOpenSinceMonth和CompetitionOpenSinceYear缺失数量一致,Promo2SinceWeek、Promo2SinceYear和PromoInterval这三个字段缺失数量一致。因此,我们有一个猜测,他们是不是同时缺失?
先把这6个字段单独定义出来:
v1 = 'CompetitionDistance'
v2 = 'CompetitionOpenSinceMonth'
v3 = 'CompetitionOpenSinceYear'
v4 = 'Promo2SinceWeek'
v5 = 'Promo2SinceYear'
v6 = 'PromoInterval'
然后运行如下代码,看一下CompetitionOpenSinceMonth和CompetitionOpenSinceYear的空值情况,这里统计从store数据集中取v2/v3字段同时为空的数据集的行列数。
# 查看一下v2和v3同时为空的记录条数,发现2个字段会同时为空
store[(store[v2].isnull()) & (store[v3].isnull())].shape
返回如下:
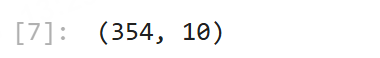
果然,行数是354,两个字段是同时为空的。再验证其他3个字段:
# 查看一下v4/v5/v6同时为空的记录条数,发现3个字段会同时为空
store[(store[v4].isnull()) & (store[v5].isnull()) & (store[v6].isnull())].shape
返回:
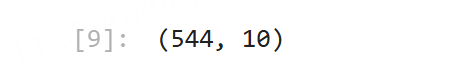
其他3个字段也是同时为空的。好,那到现在为止,3个数据集我们都摸清楚了空值情况了,接下来就要处理数据了。

















 4055
4055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









