




上一篇文章我们提到,按照训练的结果,取平均Ratio的话,是整体略偏高的,预测值大概是真实值的1.001倍,因此需要对预测的结果进行微调。微调的思路有两种,一种是全部门店乘以同一个权重进行调整,另一种是每个门店计算一个单独的权重进行微调,下面我们把两种思路都实现一遍。
1. 全部门店用统一的权重进行微调
运行以下代码计算微调权重。
# 上面是未经过微调的结果,下面开始对所有门店的预测销售金额通过一个统一的微调权重进行微调,并评估微调结果
weights = [(0.99 + (i / 1000)) for i in range(200)] # 创建一个权重的list,共200个
errors = []
for w in weights:
error = rmspe(np.expm1(y_validate), np.expm1(yhat * w)) # 尝试用每一个生成的权重对预测值进行放大,并计算均方根百分比误差存到errors中
errors.append(error)
errors = pd.Series(errors, index = weights) # errors转换成Pandas的Series结构
# 设置画图参数准备画出所有权重的均方根百分比误差值,需要挑一个最小的作为最终的权重
plt.figure(figsize = (9, 6))
errors.plot()
plt.xlabel('权重系数', fontsize = 18)
plt.ylabel('均方根百分比误差', fontsize = 18)
# 找到误差最小的位置
best_index = errors.argmin() # argmin()方法返回序列中最小值的索引
best_weight = errors.index[best_index] # 最佳权重值
best_error = errors.iloc[best_index] # 最佳权重值对应的最小误差
print(f"最佳的偏差校正权重: {best_weight:.3f}")
print(f"对应的最小均方根百分比误差: {best_error:.6f}")
运行完毕后,我们发现输出结果如下。

这个结果和前面不微调时的RMSPE相比要更小。

所有的RMSP的折线图如下,可以看到最小的值大概是在1不到点,就是上图的0.999
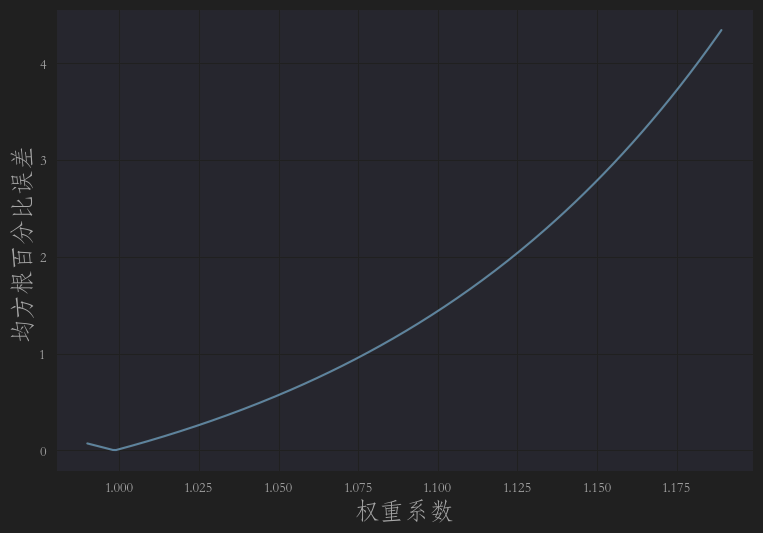
因此,我们采用统一权重对预测结果进行微调还是卓有成效的,下面我们试一下对每个门店用单独的参数进行微调。
2. 每个门店用单独的权重进行微调
运行如下代码:
# 上面是对所有门店预测的销售金额用同一个微调权重进行微调,下面对所有门店用单独的权重进行微调并评估效果
shops = np.arange(1, 1116) # 生成1~1115的门店编号
weights_validate = []
weights_test = []
for shop in shops:
cond = res['Store'] == shop # 筛选出当前门店在 res 里的数据,res保存的是验证集,以及验证集的预测值
df1 = pd.DataFrame(data = res[cond], columns = col_1) # 从res数据集中生成一个新的DF,取出这个门店基于验证集预测出来的预测结果和真实值
weights = [(0.98 + (i / 1000)) for i in range(40)] # 同在验证集中的做法一样,这里生成一个适用于测试集的权重列表,里面的每个权重将用来微调预测结果
errors = []
for w in weights:
error = rmspe(np.expm1(df1['Sales']), np.expm1(df1['Prediction'] * w)) # 为当前门店基于weights中的每个权重计算RMSPE
errors.append(error)
errors = pd.Series(errors, index = weights)
# 找到误差最小的位置
best_index = errors.argmin() # 为当前门店取出RMSPE最小的值对应的索引
best_weight = np.array(weights[best_index]) # 取出当前门店最小的权重
weights_validate.extend(best_weight.repeat(len(df1)).tolist()) # 把最佳权重 复制并扩展成和当前门店数据行数一样的数据集
cond2 = df_test['Store'] == shop # 筛选出测试集中的对应门店
df2 = pd.DataFrame(data = df_test[cond2]) # 生成一个新的DF,从测试集中取出这个门店的数据
weights_test.extend(best_weight.repeat(len(df2)).tolist()) # 把最佳权重 复制并填充到与该门店所有数据行的权重字段
# 按门店编号排序 X_validate,然后把 weights_validate 填进去。
# 再恢复原本的索引顺序。
# 最后把 weights_validate 提取出来单独存储,同时从 X_validate 删除这个辅助列。
# 这几行代码的目的,其实就是 把按门店计算好的权重序列 weights_validate,正确地对齐回 X_validate 原始数据的顺序
X_validate= X_validate.sort_values(by ='Store')
X_validate['weights_validate'] = weights_validate
X_validate = X_validate.sort_index()
weights_validate = X_validate['weights_validate']
X_validate = X_validate.drop(['weights_validate'], axis = 1)
# 按门店编号排序 df_test,然后把 weights_test 填进去。
# 再恢复原本的索引顺序。
# 最后把 weights_test 提取出来单独存储,同时从 df_test 删除这个辅助列。
df_test= df_test.sort_values(by = 'Store')
df_test['weights_test'] = weights_test
df_test = df_test.sort_index()
weights_test = df_test['weights_test']
df_test = df_test.drop(['weights_test'], axis = 1)
逻辑有点复杂,画一个流程图来看一下。
运行结束后,评估一下效果。
yhat_new = yhat * weights_validate # 按照每个门店的微调权重,对每个门店的预测值进行微调
error = rmspe(np.expm1(y_validate), np.expm1(yhat_new)) # 计算所有门店的RMSPE
print(f"RMSPE = {error:.6f} ({error * 100:.4f}%)")
发现RMSPE比按照统一权重微调又好了很多。

我感觉我可以交差了。

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









