




现在进入了机器学习数据处理的深水区 - 特征工程。进行特征工程的目的是:
- 降低维度,减少噪声,提高模型泛化能力;
- 提升训练速度;
- 减少过拟合;
- 让模型更容易解释。
我们本项目的过程将分成如下几步。
1. 了解数据特征
参与训练的数据,除了不能有空值以外,还不能为非数值型字段,因此,我们先过滤一下train训练集中非数值类型的字段看一下该如何处理。
# 过滤一下非数值类型的字段
train.select_dtypes(include=['object']).info()
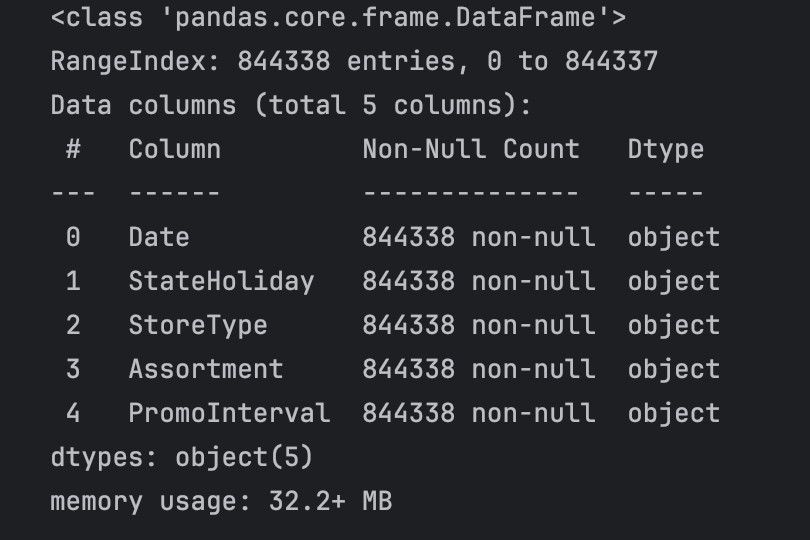
可见有5个字段需要进行处理,我们分别看一下这些字段的取值。
- Date字段
train['Date'].head()
- StateHoliday字段
train['StateHoliday'].unique()

- StoreType字段
train['StoreType'].unique()

- Assortment字段
train['Assortment'].unique()

Date类型的格式为yyyy-mm-dd,其余3个字段都属于枚举类型的值,所以需要把枚举值转换为对应的数值。
2. 处理非数值数据
for data in [train, test]: # 对 train 和 test 两个 DataFrame 都执行下面的操作,使用同一套处理逻辑保证训练集和测试集特征一致。
# 把年月日分别抓取出来并转换成数字
data['year'] = data['Date'].apply(lambda x: int(x.split('-')[0])) # 2013-05-06
data['month'] = data['Date'].apply(lambda x: int(x.split('-')[1]))
data['day'] = data['Date'].apply(lambda x: int(x.split('-')[2]))
month2str = {1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May', 6:'Jun', 7:'Jul', 8:'Aug', 9:'Sep', 10:'Oct', 11:'Nov', 12:'Dec'}
data['monthstr'] = data['month'].apply(lambda x: month2str[x]) # 把数字的月份映射成英文月份
# 处理PromoInterval字段的含义,该字段的值形式为“Jan,Feb,Mar”格式,需要根据日期中的月份monthstr来判断是否在促销月份,并生成新的字段IsPromoMonth
converter = lambda x : 0 if x['PromoInterval'] == 0 else 1 if x['monthstr'] in x['PromoInterval'] else 0
data['IsPromoMonth'] = data.apply(converter, axis = 1)
# 转换StateHoliday、StoreType、Assortment字段的值为数字
cols = ['StoreType', 'Assortment', 'StateHoliday']
mappings = {'0':0, 'a':1, 'b':2, 'c':3, 'd':4} # key-->value
pd.set_option('future.no_silent_downcasting', True)
for col in cols:
data[col] = data[col].replace(mappings).infer_objects(copy=False).astype(int)
以上代码完成了如下功能:
- 把Date字段分解成了year/month/day 3个字段
- 因为PromoInterval字段存放的值是“Jan, Feb, Mar”这样的格式,表示对应的门店在哪些月份有促销。所以新构建了monthstr字段,把新的数值类型的month字段转换成Jan/Feb/Mar这样的英文缩写月份,并判断其值是否在PromoInterval中,如果在,则新构建了一个IsPromoMonth字段并设为1,如果不在,则在新构建的IsPromoMonth中防0
- 由于StoreType/Assortment/StateHoliday字段是枚举类型,所以统一转换成0/1/2/3/4
转换完毕后,train/test数据集的字段都变成数值类型了,这时需要删掉一些不需要的字段。
# 值转换完毕后,删除不需要的字段
df_train = train.drop(['Date', 'monthstr', 'PromoInterval', 'Customers', 'Open'], axis = 1)
df_test = test.drop(['Date', 'monthstr', 'PromoInterval', 'Id', 'Open'], axis = 1)
- Customers字段删除的原因是因为test测试集中没有这个字段,训练集和测试集的字段必须保持一致;
- Id字段是test测试集中特有的索引字段,没实际意义;
- Open字段值含义是门店是否开业,但是实际的值都是1,对于模型训练没有实际的意义,所以删掉(实际上博主也曾保留过该字段进行训练,后来发现预测出来的结果的评估分数比删掉低得多);
接下来我们需要观察一下训练集中各字段之间的相关性,运行如下代码:
plt.figure(figsize = (24, 20))
plt.rcParams['font.size'] = 12
sns.heatmap(df_train.corr(), annot = True, cmap='RdYlGn_r', vmin = -1, vmax = 1)
其中,df_train.corr()计算了各字段之间的皮尔逊相关系数。输出如下:
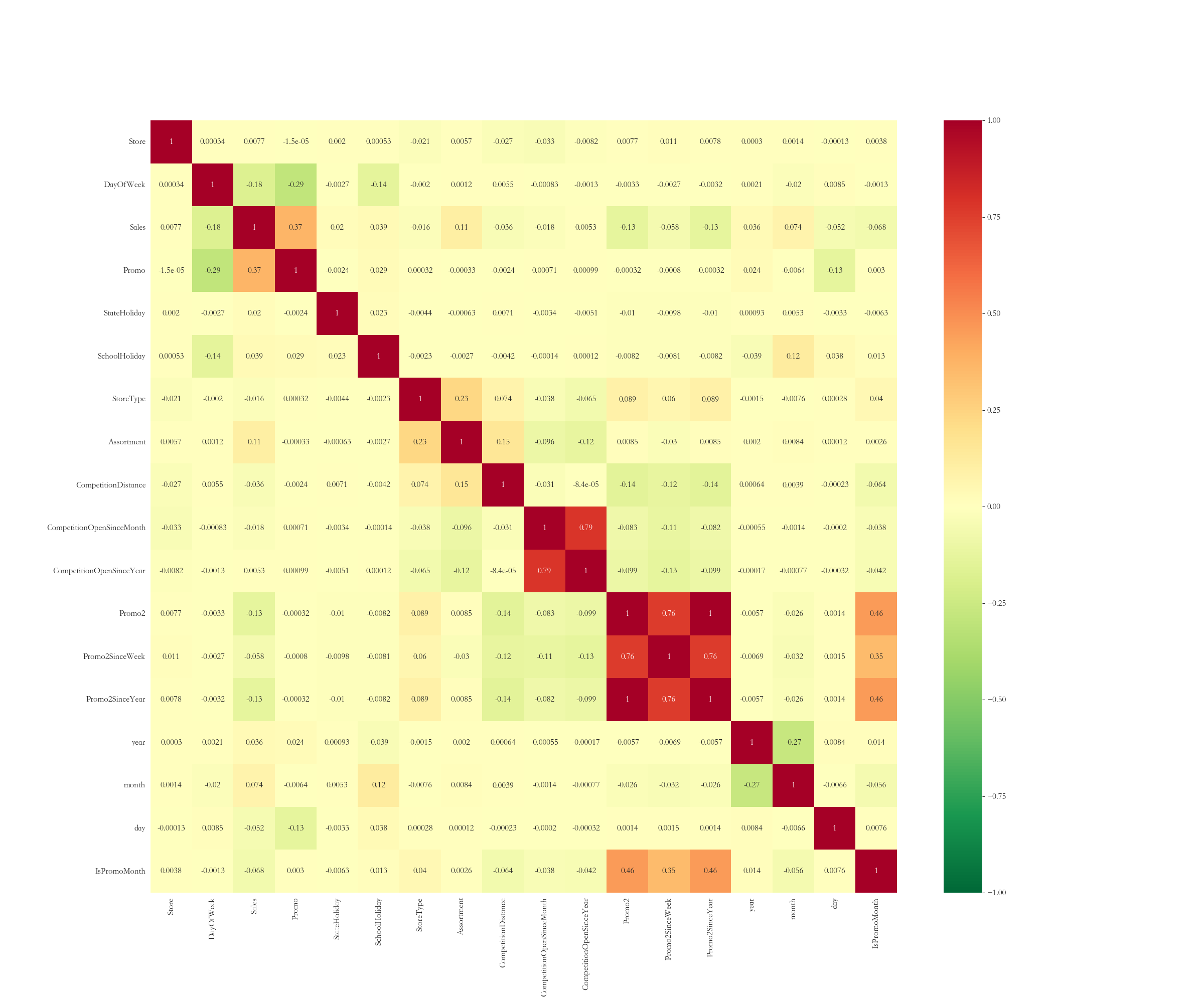
从热力图中可以看到,字段和字段之间相关性越大的,方格中的数字约大,方格中是正数的,表示字段之间是正相关,负数表示负相关。从业务逻辑上来讲,很明显门店编号Store字段和Sales关系肯定很弱,而Promo和Sales关系一定很密切。
由于我们只有train训练集和test测试集,缺少我们训练完成后用来自我评估的验证集,所以需要从训练集中拆出部分数据用来当验证集。
X_train = df_train[6*7*1115:] # 从训练集中抽取一部分作为最终的训练集
X_validate = df_train[:6 * 7 * 1115] # 从训练集中抽取一部分作为最终的验证集
训练集和验证集拆完后,需要各自分离出各自的结果集,结果期其实就是Sales字段,此时Sales字段还是和X_train、X_validate在一个数据集中,需要把这个字段单独拆出来形成各自的y变量。我们一般用大写的 X 和小写的 y 用来表示输入和输出。
# 目标值
y_train = X_train['Sales']
y_validate = X_validate['Sales']
# 特征值
X_train = X_train.drop(['Sales'], axis = 1) # 训练集中删除Sales字段,因为预测结果已经分离存储到y_train
X_validate = X_validate.drop(['Sales'], axis = 1) # 验证集中删除Sales字段,因为预测结果已经分离存储到y_validate
分离完,我们需要观察一下两个y的值的正态分布情况,如果不是典型的正态分布,可能会影响最终结果。
y1 = plt.hist(y_train, bins = 100)
运行结果如下:
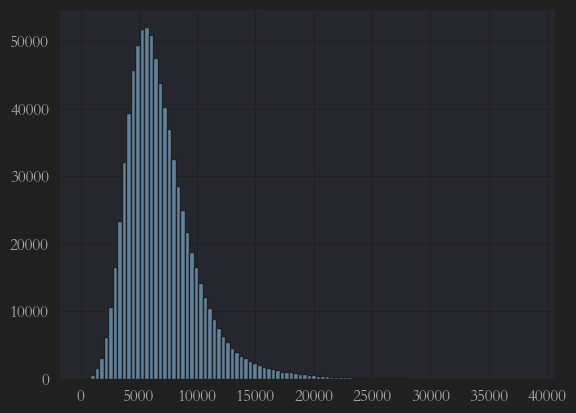
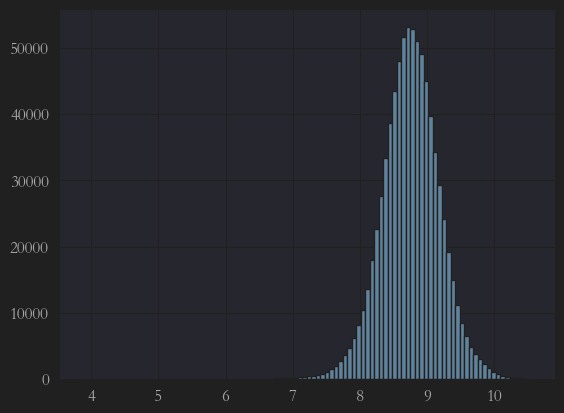
可以看出,训练集中的目标值y_train呈左偏形态,需要执行利用对数函数修正呈正态分布。
y_train = np.log1p(y_train) # 把训练集中的预测结果“销售额”进行对数化,可以使正态化更适合
y_validate = np.log1p(y_validate) # 同样,验证集中的预测结果“销售额”也进行对数化
再次执行一下,发现已经是完美的正态分布了:
y1 = plt.hist(y_train, bins = 100)
好的,那到此为止,所有训练前的数据处理,包括特征工程都完成了,我们下一篇文章就开始进行训练。

















- Rossman商店销售预测 - 特征工程&spm=1001.2101.3001.5002&articleId=153076471&d=1&t=3&u=59aab492ad6642fa9ad60896b442575a)
 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









