






基于音频偏置的噪声鲁棒小足迹关键字识别模型
第一章 语音增强之《DCCRN-KWS: An Audio Bias Based Model for Noise Robust Small-Footprint Keyword Spotting》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是西北工业大学,腾讯科技有限公司。

一、任务
将DCCRN编码器与基于扩展时间卷积的KWS模型级联,得到了在多任务学习框架下学习的DCCRN-KWS模型。为了帮助去噪任务,作者进一步引入了音频上下文偏差模块,以利用真实的关键字样本并偏差网络,以便在噪声条件下更好地区分关键字。引入特征合并和复杂上下文线性模块,分别加强识别和有效利用上下文信息。
二、动机
从“通过多任务学习将deep complex Unet (DCUnet)的架构与多通道声学模型相结合”中受到启发,作者将DCCRN和KWS级联。
三、挑战
低信噪比的声环境,给关键字定位系统带来了巨大的挑战。
四、方法
1.kws模块
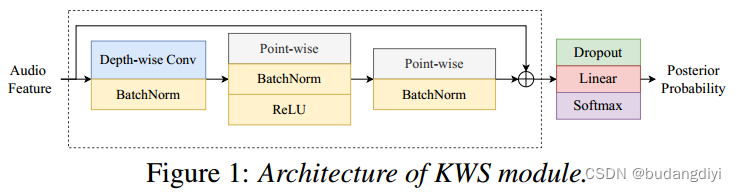
KWS模块由多个(DTC)块组成。首先使用一个扩展的深度一维卷积层来获得时间背景,然后使用两层点向卷积来整合来自不同通道的潜在特征。最后,使用带有softmax函数的全连接(FC)层来估计关键字的后验概率。
2.DCCRN-KWS网络结构
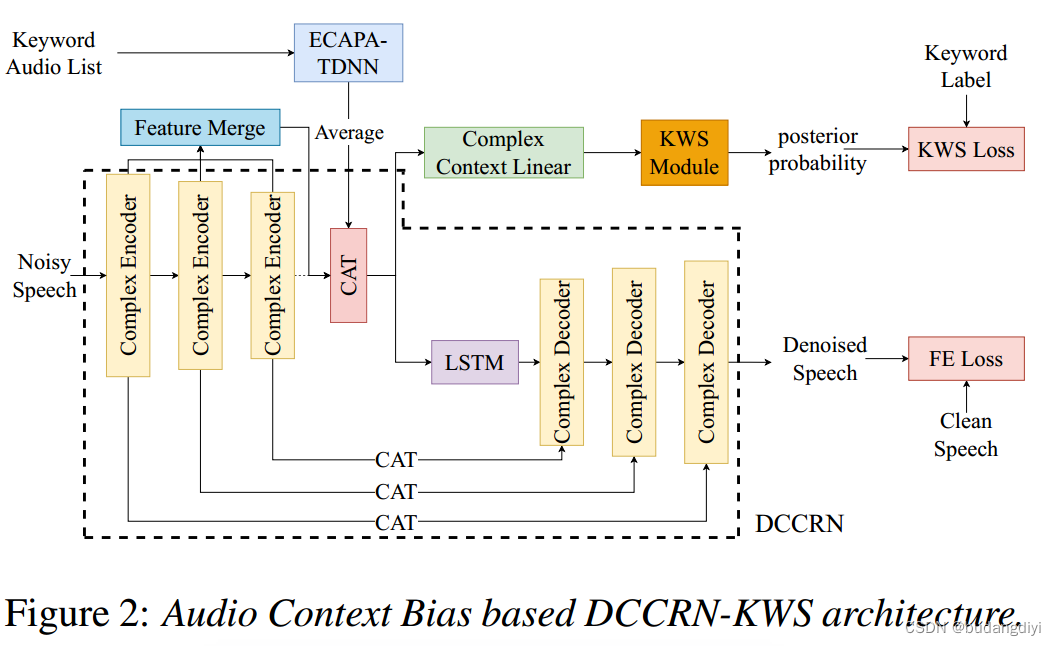
在DCCRN-KWS模型中引入了一种新的音频上下文偏差模块。首先从关键字语料库中选择一个关键字音频列表,该列表可以是固定的(一旦从语料库中选择,就不再更改)或可变的(每次从语料库中随机选择)。然后将列表上的关键字样本输入到嵌入提取器中提取偏差嵌入,最后对列表上的所有偏置嵌入向量进行平均,并将平均嵌入与DCCRN编码器的最后一层输出连接起来。
3. 功能合并
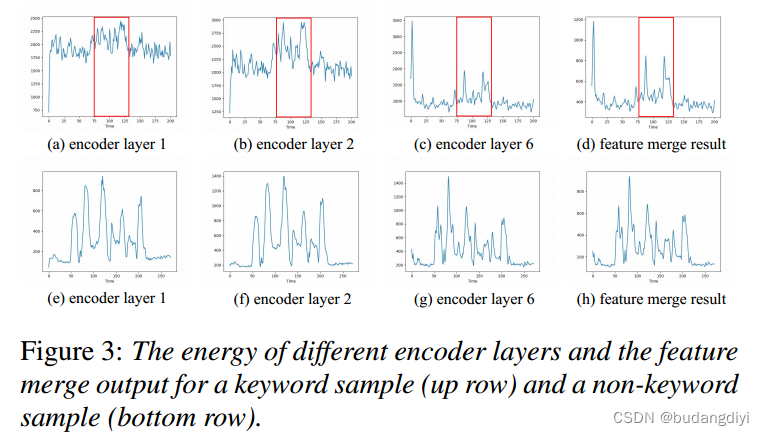
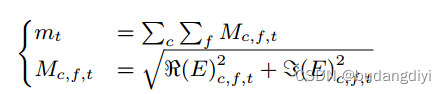
关键字部分相对于其他部分显示出相对较高的能量,并且这种现象在编码器层数越高的情况下更加明显。相反,这种现象在非关键字样本中并不存在,在非关键字样本中,能量分布在不同的层中具有相似的模式。DCCRN编码器旨在增强关键字部分的能量,从而有利于KWS模块更好地将关键字与其他音频部分区分开来。

由于前一个编码器层的维数是最后一层的两倍,我们对这些层的输出进行下采样。最后,对编码器各层的输出进行加权平均,得到特征合并输出E′。
4.复数上下文线性层
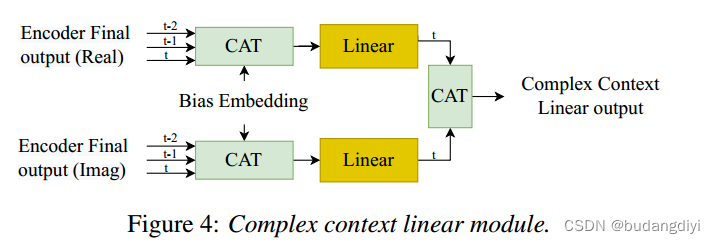
首先将编码器的输出分别拆分为实/虚部分,然后分别将实/虚部分与偏差嵌入连接起来。最后,将当前帧(t)和之前帧(t−1,t−2)的上下文特征组合在一起作为全连接层的输入。
采用典型的时域SI-SNR[20]损失函数进行语音增强任务,而使用二进制交叉熵(BCE)损失作为KWS损失。
五、实验评价
1.数据集
HIMIA数据集,该数据集来自高保真麦克风。
2.消融实验
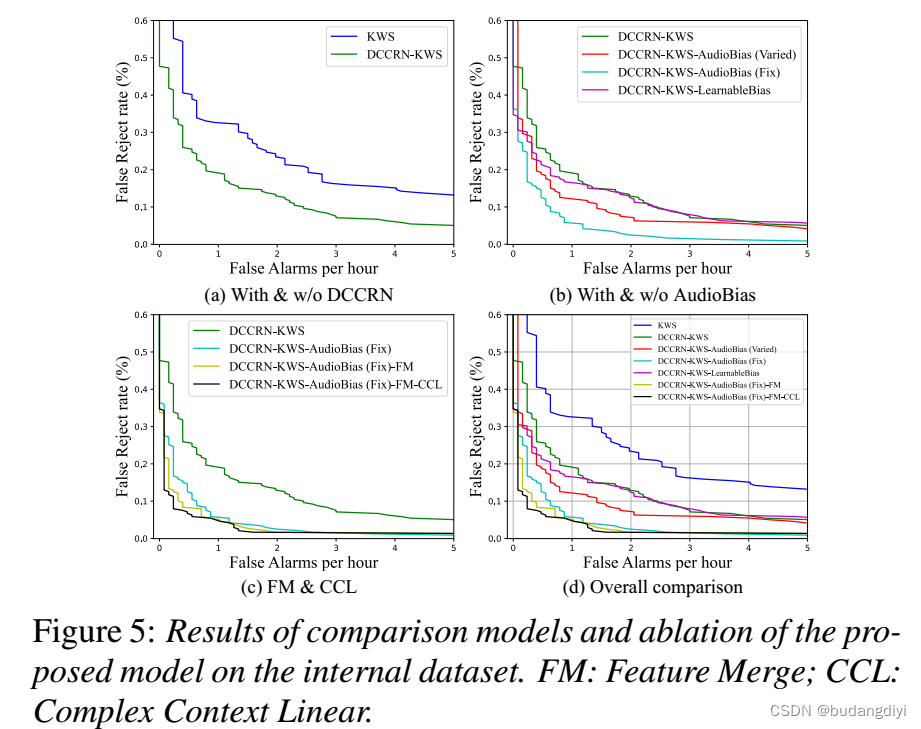
通过绘制接收者工作曲线(ROC)来衡量性能,该曲线计算每个虚警(FA)率的误拒(FR)率。
3.客观评价
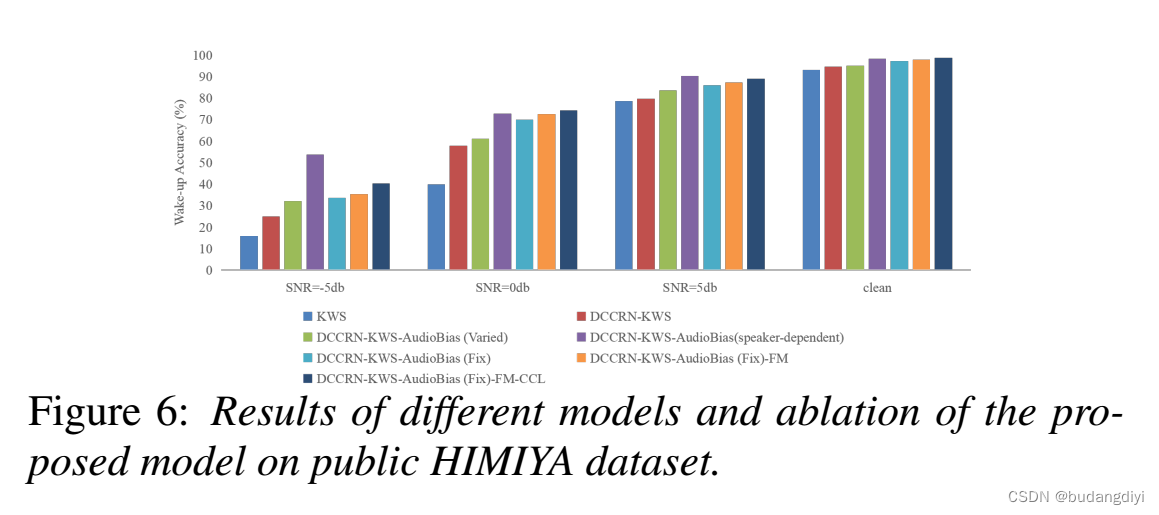
4.主观评价
六、结论
本文介绍一种用于噪声条件下KWS的前端和后端集成框架DCCRNKWS。DCCRN用于语音增强,其编码器输出与KWS模型相结合用于关键字识别。提出了一个音频偏差模块,旨在更好地学习关键字和非关键字之间的区分。引入特征合并和复杂上下文线性模块,分别加强识别和有效利用上下文信息。在两个数据集上的实验表明了该方法的有效性。


















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











